

|
|
Ivana Anděrová
Národní knihovna ČR
Úvod
Informace o článcích a zpřístupnění
obsahu článků v jakékoli formě patří v současné době mezi standardní služby
zahraničních knihoven a informačních institucí. Přístup k nim je zajištěn
z mnoha zdrojů rozptýlených po síti, z místních připojení, ze systémů CD-ROM.
Moderní technologie (např. Z39.50) umožňují zavádění jednotných uživatelských
rozhraní pro přístup do různých databází. Většina uživatelů používá databáze
sekvenčně, vzniká nutnost existence rozhraní, které by slučovalo záznamy
získané z několika databází do logické "souborné" databáze a potřeba distribuovaného
vyhledávání.
Elektronické dokumenty jsou
zpřístupňovány prostřednictvím nakladatelství, distributorských firem,
informačních institucí či služeb a jejich produktů, dále pak prostřednictvím
digitálních knihoven a služeb vznikajících na základě projektů. Přístup
k plným textům je zajišťován přes různé formy bibliografií a soupisů, obsahů
časopisů a plnotextových databází. Vyhledávání v plných textech zvyšuje
komfort přístupu uživatelů k informacím. Elektronické dokumenty jsou zpřístupňovány
v dohodnutých formátech, např. JPEG, GIF, PDF, TIFF, HTML. Služby knihoven
jsou založeny na typu služby "document delivery".
Uživatelé sdružují své prostředky
pro přístup k databázím, zejména plnotextovým. Vznik konsorcií různého
typu je na pořadu dne. Současně vznikají tzv. celostátní licence
pro libovolný počet uživatelů.
Poměrně dobře jsou zpřístupňovány
plné texty novin, týdeníků a časopisů. Problém vytváření vazeb na primární
obsah v tištěné či elektronické formě se v současnosti soustřeďuje na článkové
databáze.
Různé typy vyhledávačů založené
na vyhledávání fulltextovém, katalogovém či na kombinaci obou typů zachycují
informační zdroje v nestrukturované podobě. Relevance takto vyhledaných
dokumentů je problematická.
V poslední době vznikají
na internetu systémy, které přistupují ke zpracování zdrojů přes strukturované
záznamy. Tyto údaje mohou být obsažené ve zdrojích samotných (metadata).
Pro popis webovských informačních zdrojů je navržen formát Dublin Core
(DC) jako základní soubor údajů pro popis zdrojů. Dublin Core může být
vytvářen autorem, vydavatelem nebo distributorem těchto zdrojů.
Mezi nejkvalitnější a nejprogresivnější
služby zabývající se zpřístupněním sekundárních informací o článcích
a zpřístupněním plných textů v zahraničí patří např. UNCoverWeb, ingentaJournals,
OCLC FirstSearch Electronic Collection Online, Science Direct, PCI, ProQuest
5000, souborné katalogy DANBIB, LIBRIS a BIBSYS, JADE, program PICA. Na
WWW je možno využít služeb upozorňujících na obsahy časopisů (např. Link
Alert), rovněž je zpřístupňován denní tisk a některé časopisy s různou
hloubkou retrospektivity. Přístup k bibliografickým citacím a abstraktům
je zpravidla volný, k plným textům v závislosti na typu periodika a strategii
zainteresovaných subjektů je přístup umožněn jen předplatitelům formou
pay-per-view nebo volně. Vyhledávat lze z věcného hlediska podle klíčových
slov, předmětových hesel, stále více se uplatňuje prvotní uspořádání časopisů
do obecných kategorií. Problematikou metadat se zabývají projekty NORDINFO
a The Nordic Metadata Project.
Služby, knihovny a instituce zabývající se zpřístupněním plných textů a sekundárních informací o článcích v ČR
České nakladatelské elektronické
zdroje na internetu jsou ve stadiu vývoje a hledání podoby. Vztahy
mezi uživateli, knihovnami a vydavateli/nakladateli nejsou dosud jasné
jak z hlediska právního, tak obchodního, v budoucnu lze předpokládat v
tomto směru vznik nových iniciativ.
Na českém internetu se však
již profilovalo několik výrazných nakladatelství/vydavatelství,
informačních agentur a služeb.
Objevují se specializovaná
elektronická nakladatelství - Economia a.s., Sagit, Portál, Muzikus, Tigis
aj. vydávávající elektronické podoby tištěných specializovaných periodik
(v úplnosti i výběrově), zákonů aj. dokumentů. Přibývá elektronických
časopisů, které nemají svůj tištěný ekvivalent.
Relativně velký rozvoj na
internetu nastal v nabídce českých novinových a časopiseckých elektronických
zdrojů - jsou vystaveny deníky, týdeníky a časopisy s různou hloubkou
retrospektivy a úplnosti, od volně přístupných přes registraci a služby
placené. V některých elektronických zdrojích lze vyhledávat plnotextově.
České internetové vyhledávače
umožňují vyhledávat fulltextově i pomocí předmětových hesel a obsahových
kategorií (www.seznam.cz, www.centrum.cz, search.quick.cz, www.redbox.cz
aj.). Mezi nejúspěšnější zpravodajské servery patří www.ceskenoviny.cz,
www.iDNES.cz, www.ihned.cz, www.press.cz, www.lidovky.cz. Na těchto
serverech jsou většinou zpřístupněna aktuální vydání deníků a časopisů.
Politika, metody a strategie
vystavování elektronických zdrojů na českém internetu se často mění,
u některých je však možnost vysledovat určitou stálost a uvažovat o propojení
s analytickými záznamy. Propojování s volně přístupnými zdroji na internetu
však musí být velmi obezřetné.
Na českém informačním trhu
působí dvě společnosti, které se zabývají zpřístupňováním plných textů
programově. Společnost ANOPRESS, s.r.o. (http://www.anopress.cz)
a společnost Newton I.T., s.r.o. (http://www.newtonit.cz).
Obě společnosti získávají na základě smluv s jednotlivými vydavateli plná
znění deníků a dalších periodik. Převod článků do tvaru vhodného k dalšímu
zpracování se děje pomocí vlastních patentových postupů a zajišťuje
věrnost původní předloze. Obě společnosti vlastní archiv titulů celostátních,
regionálních a dalších včetně jejich mutací, dále pak přepisy televizních
a rozhlasových pořadů. Poskytované služby a prezentace služeb na internetu
se však liší.
Newton I.T., s.r.o.
provozuje archiv plných textů (vznikl v r. 1996), který je postupně zpřístupňován
na internetu (Právo, Zemské noviny, České Slovo, Mladá fronta Dnes, Respekt).
Služby se soustřeďují na
výběry článků a jsou poskytovány v rámci Elektronické výstřižkové služby
a prostřednictvím vyhledávacího SW Media Monitoring. Služby Newton IT jsou
přizpůsobeny individuálním potřebám uživatele a zahrnují monitoring zpráv
a článků na základě klíčových slov charakterizujících dané téma. Newton
zpřístupňuje on-line běžně aktuální měsíc vybraných titulů. Databáze
není kompletně on-line přístupná. Společnost se zaměřuje spíše na individuální
monitoring a na tvorbu archivu pro vydavatele.
Vydává elektronický časopis
Český výběr, který přináší důležité ekonomické a politické zprávy hlavních
českých deníků.
Zdroje: celostátní deníky,
regionální periodika, odborná periodika, televizní a rozhlasové pořady,
všeobecné a ekonomické databáze zpravodajství ČTK, některá zahraniční periodika.
ANOPRESS, s.r.o.
umožňuje
on-line přístup do databanky plných textů TAMTAM v aktuálním roce,
na jejíž bázi poskytuje další služby. Pomocí produktu TOVEK TOOLS pak mají
uživatelé přístup i do archivních dat několika let zpět.
Společnost zpřístupňuje
informace zákazníkovi na dané téma. ANOPRESS, s. r. o. umožňuje přístup
do databanky novin on-line na základě licenčních smluv a umožňuje nákup
celých titulů periodik. Společnost Anopress je výhradním zpracovatelem
elektronické podoby většiny českých regionálních titulů (51 titulů
nakladatelství Bohemia). Pro zpřístupnění plných textů ve veřejných knihovnách
bylo založeno v roce 2000 konsorcium ANOPRESS. Společnost je výhradním
zástupcem slovenské firmy SLOVAKIA ONLINE v ČR, která zpracovává elektronickou
podobu slovenských tištěných médií. Kromě mediální části obsahuje databanka
TAMTAM i část vědomostní, v níž jsou k dispozici pro fulltextové
vyhledávání různé encyklopedie, příručky a další knihy referenčního charakteru.
Vyhledávací systém TOPIC,
který ANOPRESS používá k monitoringu a analýze informačních zdrojů,
je v současnosti jediným interaktivním systémem na českém trhu.
Automaticky vyhodnocuje
relevanci dokumentů a umožňuje jejich řazení podle důležitosti. Na rozdíl
od zdlouhavého fulltextového vyhledávání jde v tomto případě o pojmové,
tzv. inteligentní vyhledávání. ANOPRESS ve spolupráci s Národní knihovnou
ČR vytváří v rámci tohoto projektu technologii, která umožní propojit bibliografické
záznamy knihovny s plnými texty článků z databáze Anopress, dále pak vkládat
bibliografická metadata do analytických záznamů a metadata typu Dublin
Core do plných textů (viz dále).
Zdroje: celostátní tituly,
regionální periodika, odborná periodika, televizní a rozhlasové pořady,
zpravodajství ČIA, slovenský tisk, Slovakia On-line (slovenská média),
kroniky, encyklopedie, mapy aj.
Albertina icome Praha je česká soukromá společnost zaměřená na zpřístupnění profesionálních informačních zdrojů v elektronické formě a jejich využití v praxi. AiP nabízí přes 1000 elektronických titulů předních světových vydavatelství a možnost konsorciálních licencí pro přístup k zahraničním informačním zdrojům (ProQuest 5000, PCI aj.). Elektronické vydavatelství spolupracuje na vydávání ČNB na CD-ROM.
V České republice existují
některé oborové báze plnotextových informací, např. ASPI (Automatizovaný
systém právních informací), který je vyvíjen od roku 1988 a stal se nejrozšířenějším
právním informačním systémem v České republice.
Akademie věd ČR
zpřístupňuje na internetu current content a abstrakty článků
časopisů vydávaných AV prostřednictvím jednotlivých redakcí časopisů (plné
texty zatím pouze některé redakce).
V rámci Parlamentní knihovny
se buduje systém, ve kterém jsou zpřístupněna v plné formě parlamentária.
V rámci programu "Informační
zdroje pro výzkum a vývoj" (MŠMT) byl schválen projekt "Zpřístupnění
plnotextových databází odborných zahraničních periodik na základě programu
Open Society Institute - EIFL Direct". EIFEL Direct zpřístupňuje
prostřednictvím databází EBSCO více než 3300 plnotextových
časopisů a 1300 brožur a plnotextových referenčních publikací. Báze zahrnují
humanitní a společenské obory, obchod, medicínu, aplikované přírodní vědy,
výpočetní a telekomunikační techniku. Na základě projektu "Zabezpečení
vědy a výzkumu v humanitních oborech základními informačními zdroji" (MŠMT)
je umožněn knihovnám v ČR v rámci národní licence přístup do článkových
databází PCI, PCI Full Text a ProQuest 5000.
Bibliografické zpracování
článků v ČR je poměrně rozsáhlé jak co do zdrojů, které se analyticky
zpracovávají, tak co do typů institucí, které tuto činnost provozují.
Národní knihovna ČR
zpracovává výběrově bibliografické záznamy článků ze všech druhů seriálů
(noviny, časopisy, odborná periodika, sborníky) v rámci Kooperačního
systému článkové bibliografie (KOSABI), ve kterém spolupracují
SVK, resp. krajské knihovny a MZK, specializované odborné knihovny (STK,
ÚZPI, SPKK-ÚIV, ČSAV). Na základě této spolupráce vzniká souborná databáze
ANL.
Kromě toho zúčastněné knihovny disponují svými vlastními databázemi z hlediska
svého regionálního a/nebo odborného zaměření. V systému LANIUS se
zpracovávají biblio-grafické záznamy článků v knihovnách na úrovni okresů.
V budoucnu je třeba sladit systém KOSABI a LANIUS tak, aby nedocházelo
k duplicitnímu zpracování. V současné době se postupně v rámci KOSABI aplikuje
nebo plánuje přechod na nové SW vyšší generace, zatím probíhá ve většině
SVK popis článků v ISISu. V SVK Kladno se články popisují v systému RAPID,
v MZK v Brně a v SVK Olomouc v ALEPHu. V době přechodu spolupracujících
institucí na nové integrované systémy (KP-SYS, TINLIB, RAPID apod.)
je kvalitní automatizovaná správa souborné databáze nutná. Souborná
databáze KOSABI ANL obsahuje přes 630 000 záznamů, v NK ČR se excerpuje
cca 210 titulů, 469 titulů ve spolupracujících institucích (278 specializované
knihovny, 191 titulů v SVK a MZK). Přechod na zpracování v systému
ALEPH 500 v dubnu 2000 posunul zpracování na úroveň mezinárodního formátu
UNIMARC
a pravidel popisu AACR2 s respektováním mezinárodních standardů
věcného popisu - MDT-MRF pro oblast systematické indexace. Záznamy respektují
metodické materiály Záznam pro soubornou databázi : UNIMARC a
Záznam pro soubornou databázi : Výměnný formát. Byla aktualizována
pracovní verze metodické příručky pro zpracování článků v UNIMARCu. V oblasti
verbální
věcné indexace se kombinují klíčová slova, věcné obecné kategorie a
předmětová hesla. Vyváženost vazby mezi jednotlivými vrstvami popisu je
klíčovým momentem. V rámci kooperačního systému byla stanovena pravidla
pro výběr titulů k popisu (na základě územní gesce - tituly
regionální a celostátní provenience - a dále pak na základě odborného zaměření).
Dále byly stanoveny zásady výběru článků co do úplnosti i co do typů. Analytické
záznamy zpracovávané v rámci KOSABI jsou zpřístupňovány také na CD-ROM
vydávaném
AiP
v rámci ČNB jako řada Články v českých novinách, časopisech a sbornících,
od června 2000 v UNIMARCu, od ledna 2001 s hypertextovými odkazy na volně
přístupné plné texty. CD-ROM je vydáván ve čtvrtletních aktualizacích,
každý měsíc je vystavena aktualizace na internetu .
Projekty týkající se zpracování české článkové bibliografie a zpřístupnění plných textů
V posledních letech vzniká
několik projektů zabývajících se zpřístupněním analytických záznamů
v kooperaci s ostatními knihovnami, jejich prezentací na internetu a propojením
těchto záznamů s plnými texty.
Projekt Zpřístupnění
výsledků analytického zpracování prostřednictvím internetu (kooperační
projekt 13 knihoven v rámci RISKu, řešen v roce1998, hlavní řešitel Ivana
Anděrová) umožnil konverzi analytických záznamů z CDS/ISISu do UNIMARCu.
V rámci projektu byla vypracována a odzkoušena konverze tehdejší verze
TINLIBu do UNIMARCu. V rámci průzkumu internetu se ukázalo, že postupné
propojení článků s některými plnými texty již vystavovanými na internetu
na různých serverech bylo v tehdejší době a situaci na českém internetu
krajně nespolehlivé (různá retrospektiva a úplnost vystavovaných plných
textů, různá strategie vystavovatelů ). Výběr spolehlivých zdrojů
plných textů v budoucnu je možným řešením.
Projekt Západočeský
ANAL - Kooperativní zpracování periodické produkce západních Čech (SVK
v Plzni a 11 městských knihoven, řešitel Jaroslava Hanzlíčková, RISK, podaný
v roce 1999) se zabývá odstraněním duplicit při zpracování, metodikou excerpce
titulů a zpracování záznamů v jednotlivých okresech západočeského regionu.
Projekt Zavedení automatizovaného
zpracování článkové bibliografie v systému T-Series (SVK v Ostravě,
hlavní řešitel Alena Hrazdilová, VaV, 2000-2001) řeší problematiku bibliografického
zpracování článků v tomto systému.
Projekt SVK Kladno
(ve schvalovacím řízení) je velmi významný z hlediska tvorby a rozvoje
regionálních faktografických databází a souborů autorit
Propojení analytických
záznamů s plnými texty a optimalizace zpřístupnění plných textů
(VaV, hlavní řešitel Ivana Anděrová, 1999-2003) je projekt analyticko-koncepční
a připravuje půdu pro praktickou realizaci programového projektu Souborná
databáze kooperačního systému článkové bibliografie - optimalizace integrace
a správy heterogenních dat. Cílem výzkumného záměru je optimalizace přístupu
uživatelů k plným textům dokumentů domácí provenience (nikoli zahraniční).
Základem je propojení analytických záznamů o článcích s plnými texty,
které jsou dostupné na internetu.
V rámci projektu proběhlo
v roce 1999 v Národní knihovně ČR výběrové řízení na základě výzvy k podání
nabídky pro společnost Anopress. V rámci projektu byla vyvinuta iniciativa
k vytvoření konsorcia Anopress. Smlouva Konsorcium uživatelů databanky
TAMTAM informační agentury ANOPRESS s.r.o. byla podepsána mezi SKIP a Anopressem
v roce 2000. V roce 1999 bylo experimentálně propojeno cca 4000 záznamů
s plnými texty získanými od Anopressu. Dále byly propojeny záznamy s plnými
texty některých knihovnických periodik vystavených na internetu. Od zmíněné
agentury bylo zakoupeno 20 075 plných textů článků, které byly publikovány
převážně v celostátních denících v roce 1999 a které byly následně bibliograficky
zpracovány v oddělení analytického zpracování. Periodikum Národní knihovna
bylo v Anopressu převedeno do digitální formy a zpřístupněno na internetu
(v roce 1999 pouze technikou OCR, od roku 2000 se přistoupilo i k prezentaci
obrázků). V budoucnu se počítá s vystavením tohoto periodika ve formátech
HTML a PDF.
V roce 2000 byla ujasněna
základní koncepce, strategie a metody zpřístupňování plných textů ve vazbě
na bibliografické záznamy obsažené v bázi ANL a vznikající v rámci Kooperačního
systému článkové bibliografie (KOSABI). Koncepce má flexibilní charakter
vzhledem k vyvíjející se situaci ve zpřístupňování plných textů
na internetu a očekávaným aplikacím nových metod zpřístupnění dokumentů
v rámci jiných projektů. Na projekt bylo v tomto roce z institucionálních
prostředků vyčleněno 229 000 Kč.
Záměr souvisí s programovým
projektem Souborná databáze kooperačního systému článkové bibliografie
- optimalizace integrace a správy heterogenních dat, který je svým charakterem
realizační.
S ohledem na časovou, druhovou
a tematickou skladbu záznamů obsažených v bázi ANL byly stanoveny základní
zdroje získávání plných textů pro propojení s bibliografickými záznamy:
plné texty volně přístupné na internetu s relativně stálým způsobem vystavení
(elektronická vydavatelství/nakladatelství, ČSAV, UK, archivy aj. databáze)
a plné texty získané od distributora plných textů (Anopress s.r.o.). Zpracování
bibliografických záznamů a plných textů probíhá v rámci integrovaného knihovnického
systému respektujícího UNIMARC (ALEPH aj.) a v rámci linky automatické
indexace bibliografických záznamů z plných textů za současné tvorby URL
a metadat DC. Propojení může být realizováno ručně i programově, metodou
on-line i off-line. Propojení může být statické a dynamické, uzavřené a
otevřené. Zpřístupnění plných textů z hlediska typu navigačních prvků a
způsobu vyhledávání: OPAC - bibliografické záznamy uložené v UNIMARCu s
URL adresou, systém pojmového vyhledávání (TOPIC) a fulltextového vyhledávání,
metadata DC zabudovaná do plných textů, protokoly např. Z 39.50, SFX, vyhledávače
pracující na WWW. Uložení plných textů: na internetu, na WWW serveru NK,
WWW serveru distributora (Anopress s.r.o.). Pro správu Kooperačního systému
článkové bibliografie v systému ORACLE bylo formulováno zadání na základě
již existující aplikace pro Souborný katalog.
V rámci projektu bylo propojeno
cca 1214 bibliografických záznamů s relativně stálými elektronickými prezentacemi
na WWW z knihovnictví aj. oborů. Dynamicky bylo propojeno cca 1800 plných
textů z celostátních deníků a vybraných časopisů za současného
uložení na server NK v rámci konsorcia Anopress. Zároveň bylo zakoupeno
9350 plných textů určených k propojení off-line (seznam titulů viz dále).
Plné texty uložené na serveru NK jsou vybaveny metadaty DC. V rámci
projektu byl pravidelně poskytován monitoring médií pro oddělení vztahů
s veřejností a ředitele NK a hrazeny licence (4 měsíce) na plné texty v
rámci konsorcia Anopress. Na CD-ROM Česká národní bibliografie, v řadě
Články v českých novinách, časopisech a sbornících, byla implementována
funkce pro aktivní hypertextové odkazy, které umožňují propojení záznamů
o článcích s plnými texty na internetu.
Souborná databáze kooperačního
systému článkové bibliografie - optimalizace správy a integrace heterogenních
dat (programový projekt VaV, r. 2000-2004, hlavní řešitel Ivana Anděrová).
Náplní projektu je optimalizace
integrace a správy heterogenních dat souborné databáze Kooperačního systému
článkové bibliografie (KOSABI). Bibliografické záznamy článků publikovaných
v českém periodickém tisku zpracovávané spolupracujícími knihovnami jsou
postupně propojovány s elektronickou podobou článků a takto prezentovány
na internetu. V projektu jsou řešeny nové metody zpracování článků na základě
dat přebíraných z plných textů v rámci linky automatické indexace
za současného vkládání metadat DC do plných textů. Obě části souborné databáze
- vznikající databáze plných textů (ANLFULL) a báze bibliografických
záznamů ve formátu UNIMARC (ANL) - vyžadují permanentní kvalitní
SW a HW podporu. Vývoj aplikace pro management kooperačního systému
(pro příjem a správu dat) je předpokladem profesionalizace tohoto systému.
Plné texty článků (celostátní
deníky, Respekt, Reflex, Ekonom, Týden) byly v rámci konsorcia Anopress
průběžně stahovány, připravovány k dynamickému propojení a následně propojeny
s bibliografickými záznamy ve 2. pololetí roku 2000 (cca 7528 propojení
). Plnotextová databáze byla dále průběžně doplňována články z celostátních
deníků a výše jmenovaných časopisů vydanými v roce 2000 a 1998 (cca
17930 plných textů). Průběžně byly staticky propojovány záznamy s plnými
texty z oblasti knihovnictví aj. oborů dostupnými na internetu (Národní
knihovna, U nás, Ikaros, Daidalos, Veřejná správa, Obchodní právo, Právo
a podnikání, Moderní obec, Vesmír, Collection of Czechoslovak Chemical
Communication, Harmonie, Lesnická práce, Obecná psychologie).
V roce 2000 probíhaly
rozsáhlé korektury báze. Chybovost v bázi je z velké části dána existencí
dvou podob báze v minulosti - v ISISu a UNIMARCu - a způsobem
zpracování v CDS/ISISu. Opravy v databázi si vyžadují průběžnou pozornost,
chybovost je stále velká jak na straně NK, tak i spolupracujících institucí.
Pro optimalizaci integrace
a správy heterogenních dat souborné databáze kooperačního systému vyvinula
česká firma ANOPRESS na podkladě analýzy a funkčního zadání návrh speciální
technologie - linky automatického získávání plných textů, indexace bibliografických
záznamů a plných textů, propojování záznamů na plné texty a jejich
zpřístupnění. Řešení je progresivní a odpovídá nejnovějším trendům v této
oblasti, je podpořeno kvalitním technickým a programovým vybavením. Jednotlivé
moduly lze použít i samostatně. V rámci experimentu v roce 2001 je
třeba ještě doladit technologii v rámci různých stadií aplikace.
Řešení spočívá ve
speciální aplikaci v praxi již používané technologie firmy na získávání
a zpřístupňování plných textů pro NK - TAMTAM Profesional NK
(TTPNK). Pomocí této technologie je možno stahovat plné texty článků
z internetu z báze TAMTAM, založené na plnotextovém pojmovém vyhledávání
systému TOPIC. Je možno stahovat více článků najednou na základě
tématu, názvu článku, názvu zdrojového dokumentu aj. údajů. (Pro stahování
je možné využít i verzi TAMTAM Standard - TTS).
Pro vlastní automatickou
indexaci článků a plných textů - pro vytváření bibliografických záznamů
v UNIMARCu a v Dublin Core na základě údajů uložených v plných textech
a naopak pro vkládání metadat Dublin Core do plných textů - je připravena
technologie TAMTAM Data Extractor (TTDE).
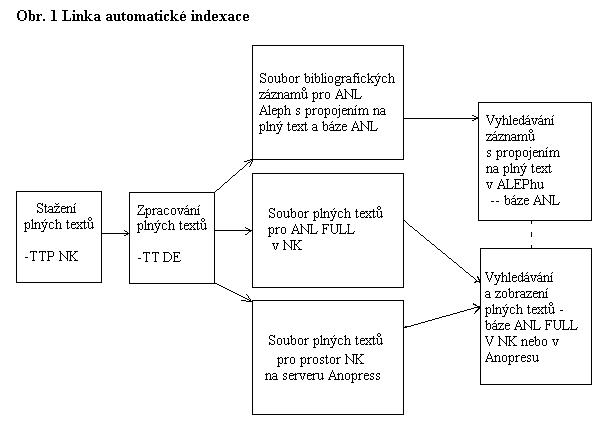
Pro automatické generování dat z plných textů bylo připraveno 6 hlaviček (headers) :
a) Formulář pro editaci, do kterého se generují bibliografická data z plného textu. Data lze katalogizátorem následně upravovat a provádět tak korekce nejen ve Formuláři, ale automaticky také v hlavičce UNIMARC-A, UNIMARC, Dublin hlavičce. Obsahuje údaje jmenného popisu, které se přebírají z hlavičky plného textu (oproti původním údajům byly doplněny údaje: ročník, číslo, ISSN), dále pak údaje věcného popisu (předmětové kategorie, automaticky generovaná klíčová slova, automaticky generovaný abstrakt - extrakt), automaticky generovanou URL, složenou z jednotlivých komponent, odpovídající struktuře propojovacího pole 856 ALEPH a UNIMARC. Volbou Text na horní liště je možno zobrazit plný text.
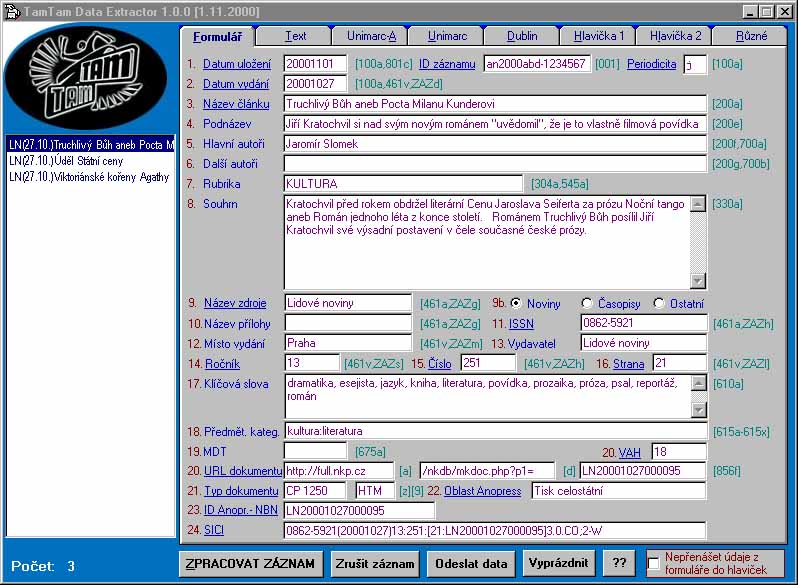
Obr. 2 Hlavičky
b) UNIMARC-A hlavička
je hlavička s bibliografickými údaji pro importní vstupní soubor záznamů
pro ALEPH (řádkový UNIMARC), do které se automaticky generují současně
tatáž data i úpravy zanesené do Formuláře pro editaci. Tato hlavička
je též přístupná pro editaci samostatně.
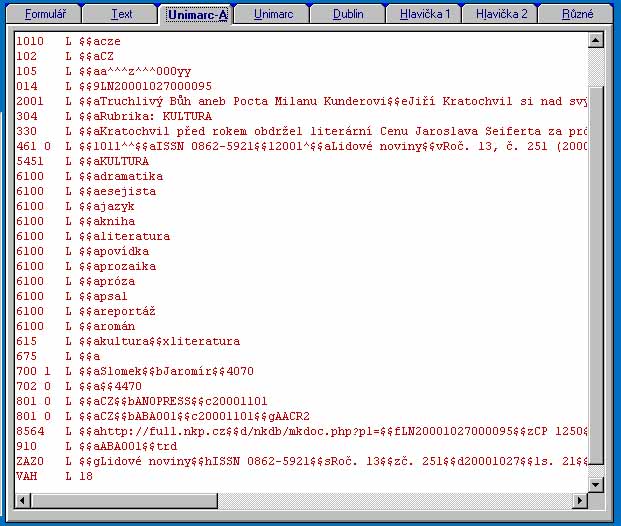
Obr. 3 UNIMARC-A hlavička
c) UNIMARC
hlavička, hlavička pro klasický UNIMARC se stejnými vlastnostmi jako
hlavička UNIMARC-A - slouží k eventuálnímu importu pro systémy, které jsou
založeny na UNIMARCu - řádkový UNIMARC.
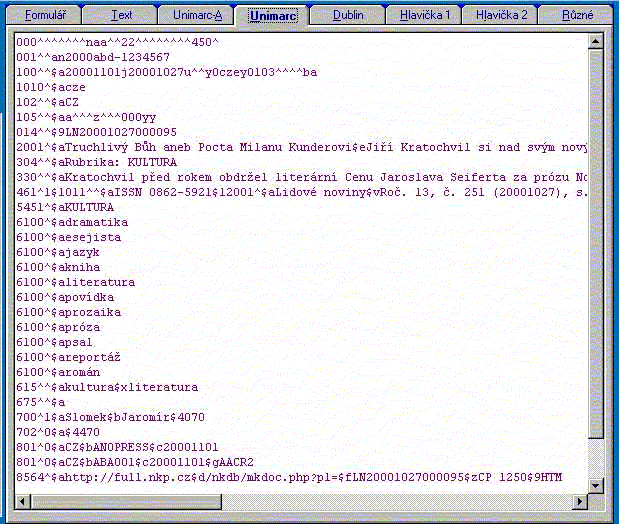
Obr. 4 UNIMARC
hlavička
d) DUBLIN hlavička s týmiž vlastnostmi jako předchozí dvě hlavičky slouží ke generování metadat Dublin Core zpět do plného textu - slouží k zabudování těchto metadat do plných textů pro fulltextovou databázi. Tato hlavička vychází z poslední verze Dublin Core Metadata Set, obsahuje automaticky generované SICI (Serial Item and Contribution Identifier) a provizorní NBN (National Bibliography Number) .
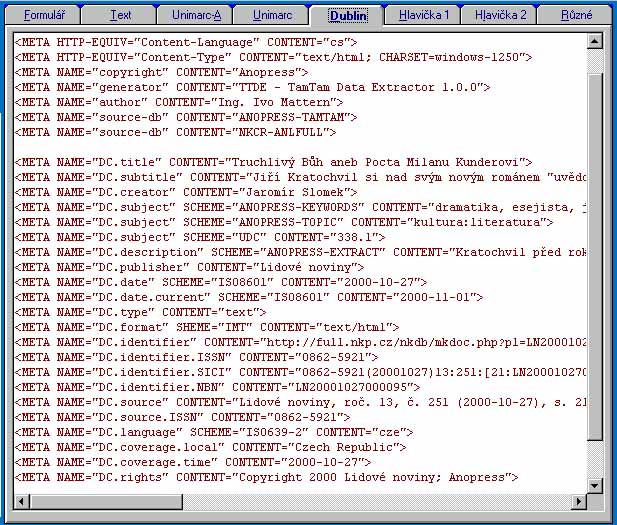
Obr. 5 DUBLIN hlavička
e) Indexovací hlavička
obsahuje údaje jmenného popisu.
f) Zobrazovací
hlavička slouží k zobrazení údajů v hlavičce plného textu .
Po odrážce různé je možno
nastavit tvar výstupní hlavičky pro UNIMARC-A nebo UNIMARC
a spustit ruční vstup dat. V další fázi následuje přesunutí UNIMARC-A
hlavičky do importu pro ALEPH (báze ANL) a umístění plných
textů ve tvaru HTML na WWW server NK k indexaci do fulltextové databáze
v NK nebo v Anopressu.
Pro indexaci dat do fulltextové
databáze (ANL FULL) v NK byl vyvinut program MkIndex (MkI).
Tento program nalezená data automaticky zaindexuje, umožňuje jejich
vyhledání ve fulltextové databázi a zpřístupnění. Plné texty
jsou ve formátu HTML.
V budoucnu bude Formulář
pro editaci pravděpodobně rozšířen o některé údaje věcného popisu, které
budou dodávány ručně.
Pro propojení plných
textů se systémem ALEPH (doplnění URL adres do záznamů) byl vytvořen
skript
mkdoc.http. Propojení probíhá na základě dynamicky generovaného odkazu
na dokument. Program vyhledá požadovaný dokument dle identifikace (identifikační
číslo), provede statistiku a v budoucnu bude provádět kontrolu autorizace
a na jejím základě zobrazí plný text nebo abstrakt.
Pro vyhledávání v
datech ve fulltextové databázi jsou vyvinuty formuláře pro vyhledávání
jednoduché, pokročilé a pokročilé s tématy.
Dotaz lze zadávat třemi
způsoby:
Prostý dotaz je pouze
seznam slov, které se mohou vyhledat. Všechna slova mají stejnou váhu -
možno použít při hrubém hledání, kdy se přesně neví, co se má vyhledat.
Formulářový dotaz slouží
k přesnějšímu vymezení dané oblasti. Dotaz lze specifikovat dalšími atributy,
jako např. autor, zdroj, datum atd.
Tematický dotaz je
nejpřesnější. Spočívá ve vytvoření topiku, kdy mohou být zadány všechny
váhy.
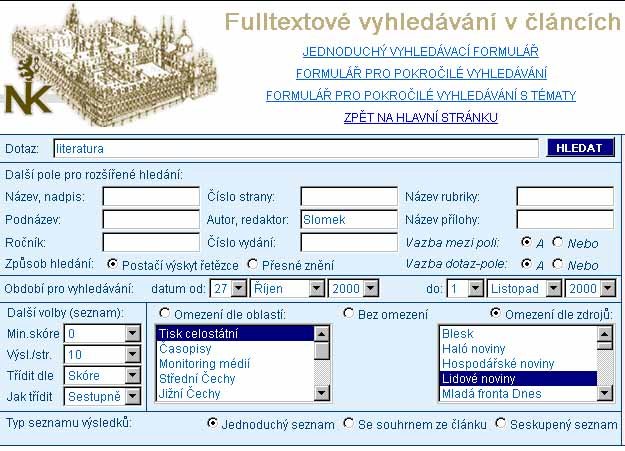
Obr. 6 Formulář pro
vyhledávání s tématy
Vyhledávání probíhá v systému
TOPIC
(Search 97) a definice formulářů vychází z jeho filozofie.
TOPIC
(pojmově orientovaný vyhledávací systém, concept based retrieval) je
systém třetí generace založený na následujících principech:
rozklad pojmu na podpojmy, vážení jednotlivých podpojmů (větví pojmového
stromu), neostré vyhodnocování dotazů.
Dotaz v systému třetí generace
reprezentuje pojem, resp. ideu vyhledávaného tématu. Jádrem dotazu je stromová
hierarchická struktura, která rozkládá hledané téma na podtémata a přiřazuje
jednotlivým částem váhy, které vyjadřují, do jaké míry příslušné téma přispívá
k celkovému určení tématu. Systém dále vypočítá míru relevance vyhledaných
dokumentů. Oproti běžně používaným operátorům používá TOPIC logický operátor
ACCRUE se specifickými vlastnostmi. Tento operátor sbližuje operátory and
a or. Každý topik obsahuje tedy tři charakteristiky - strukturu, váhy a
operátory.
Nabízí se zde jistá formální
analogie k hierarchickému selekčnímu jazyku systémové notace MDT. Je
však třeba zdůraznit, že topiky jsou tvořeny podle skutečnosti, MDT je
víceméně taxativní systém jednotlivých oborů, nikoli témat. Proto je třeba
k definici topiků přistupovat svébytně. V roce 2000 byl vypracován
hrubý návrh některých topiků.
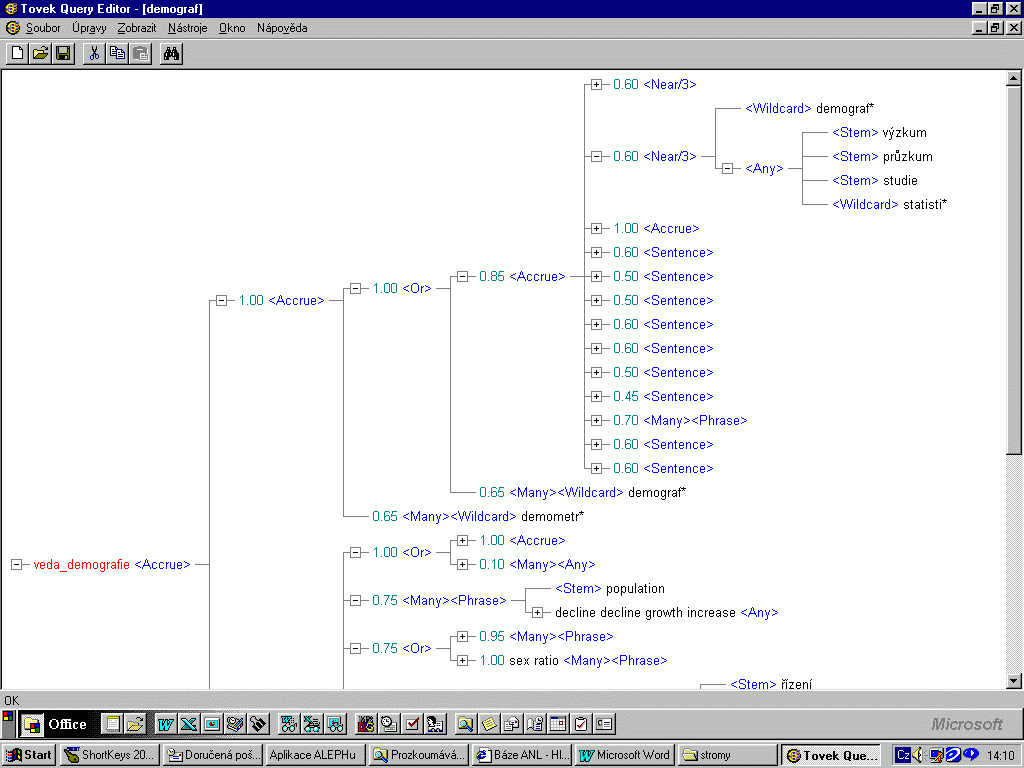
Obr. 7
Topik pro obor Demografie
V oddělení analytického zpracování
se používají k indexaci hrubých témat a podtémat předmětové kategorie,
které připomínají svou podstatou topiky, resp. témata a skupiny témat v
systému TOPIC v databázi Anopress. Je však třeba je sladit
(podle možností) obsahově.
Na základě zadání pro řízení
a správu kooperačního systému a za využití již vyvinutých řešení v rámci
Souborného
katalogu CASLIN probíhají práce na vývoji aplikace pro management
Kooperačního systému článkové bibliografie. V roce 2000 byl nainstalován
na server ANL systém LINUX a
ORACLE, ve stadiu ladění
je aplikace pro příjem a automatizované zpracování dat (příjímání analytických
záznamů, integrace stávajících programů pro konverzi analytických
záznamů, globální úpravy analytických záznamů, vývoj programů na formálně
logické kontroly kooperujících knihoven - test na UNIMARC pro
analytické záznamy).
V rámci projektu bylo zakoupeno
kvalitní hardwarové a softwarové vybavení.
Dodatek č. 3 ke Smlouvě
o sdružení pro Českou národní bibliografii, který zabezpečuje fungování
Kooperačního systému článkové bibliografie v situaci reformy státní správy,
byl podepsán koncem roku 2000.
Závěr
Kooperační systém článkové
bibliografie existuje bezmála 10 let - přetrval a existuje díky trpělivé
a vytrvalé práci mnoha zúčastněných. Jeho budoucnost spočívá v zavedení
nových metod získávání, zpracování a zpřístupňování informací o článcích.
Integrace heterogenních
dat do Kooperačního systému článkové bibliografie, v němž dochází k propojení
tradičních knihovnických postupů a fondů s určitými prvky digitální knihovny,
je předpokladem jeho úspěšného a efektivního fungování v budoucnu. Nalezení
příslušného článku z novin či časopisu (v budoucnu snad i statě ze sborníku)
v elektronické formě a navigace k primárním dokumentům přispěje ke zvýšení
uživatelského komfortu.
K posunu znalostí došlo v posledních letech především v těchto oblastech:
- Možnost zpřístupňování
a získávání plných textů v rámci konsorcia.
- Návrh a praktická realizace
nových trendů ve zpracování a zpřístupňování informací na konkrétní fungující
systém, která umožní jeho přetrvání v budoucnu (UNIMARC, AACR2, automatická
indexace dokumentů, metadata, pojmové vyhledávání, propojování s elektronickými
zdroji na základě dynamických a statických URL adres, vazba na klasický
fond a fond elektronických dokumentů).
- Vytvoření předpokladů
pro distribuované vyhledávání informací za současného využití tradičního
slučování informací do souborné databáze založené na architektuře statických
bází a implementaci systému do konceptu metaknihovny.
- Posílení vazeb v rámci
KOSABI
v
situaci reformy státní správy a samosprávy.
- Nová forma poskytování
informačních služeb za spolupráce knihovnické a moderní informační
instituce.
Návrhy předpokladů pro úspěšné fungování systému v budoucnu:
- Zajištění dalšího financování
projektů.
- Posílení vazeb stávajícího
KOSABI na existující kooperační systémy na nižší úrovni z hlediska
správního, zejména na systém LANIUS.
- Personální zajištění
projektu z hlediska počtu pracovníků oddělení analytického zpracování
v NK.
- Existence aktuálních
souborů autorit v oblasti jmenného a věcného popisu jsou nutným předpokladem
kvalitního zpracování a vyhledávání informací.
- Přísnější výběr článků
k indexaci deníků s cílem vyloučení subjektivního faktoru při excerpci
deníků, zkvalitnění popisu článků.
- Funkčnost propojovacích
vazeb v systému ALEPH a možnosti expanze a spolehlivosti systému
v tomto ohledu. Moderní informační systémy jsou založeny na propojování
sekundárních informací s primárními, jak klasickými, tak elektronickými,
ale také na vzájemném propojování sekundárních informací o různých typech
dokumentů. Nejde pouze o propojení záznamů s plnými texty, ale také o provázání
seriálů a jednotlivých čísel na analytický rozpis článků obsažených v seriálu
v rámci báze NKC či Souborného katalogu CASLIN, dále pak připojení článků
- recenzí k recenzovaným dokumentům v rámci těchto bází.
- Nutnost řešení problému
jednotného přístupu uživatelů do informačního systému, existence plnotextových
databází českých informačních zdrojů a stanovení pravidel pro jejich zpřístupňování,
konsorciální a celostátní licence pro přístup k těmto informačním zdrojům.
Literatura:
Tištěné dokumenty
ANDĚROVÁ, Ivana. Metodika popisu článků ve formátu UNIMARC - podklad pro interpretace AACR2R : verze 1.1 (14.4.2000). 103 s. Pracovní materiál.
ANDĚROVÁ, Ivana [et al.]. Národní bibliografie - analytický popis : příručka pro zpracovatele. Praha : Národní knihovna, 1993. 412 s. Revize 1, 1993; Revize 2, 1997.
ANDĚROVÁ, Ivana. Současný stav a perspektivy kooperačního systému článkové bibliografie. Národní knihovna : knihovnická revue, 1995, roč. 6, č. 1, s. 39-42.
BRATKOVÁ, Eva. K otázkám
pojmu, třídění a typologie internetových a webovských informačních zdrojů.
Národní knihovna : knihovnická revue, 1998, roč. 9, č. 5, s. 262-276.
BRATKOVÁ, Eva. Metadata
jako nový nástroj pro komunikaci webovských informačních zdrojů. Národní
knihovna : knihovnická revue, 1999, roč. 10, č. 4, s. 178-195.
ČERVENÝ, Vlastimil. Vyhledávání v databázích plných textů. Národní knihovna : knihovnická revue, 1999, roč. 10, č. 1, s. 6-12.
OPPENHEIM, Charles and SMITHSON, Daniel. What is the hybrid library? Journal of Information Science, 1999, vol. 25, no. 2, s. 97-112.
Záznam pro soubornou databázi : UNIMARC. Fyzicky nesamostatné části dokumentů. Tištěné monografie a seriály. 1. vyd. Praha : Národní knihovna České republiky, 1999. 45 s. (Standardizace ; č. 19).
Záznam pro soubornou databázi : Výměnný formát. Fyzicky nesamostatné části dokumentů. Tištěné monografie a seriály. 1. vyd. Praha : Národní knihovna České republiky, 1999. 39 s. (Standardizace ; č. 20).
Topic : systém pro inteligentní vyhledávání dokumentů. Praha : Tovek, 19?, 77 s.
Elektronické dokumenty
BURGETOVÁ, Jarmila. Právní aspekty poskytování knihovních elektronických a reprografických služeb. Ikaros [online], 1999, č. 6. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c06/repro.htm.
CELBOVÁ, Ludmila. Elektronické zdroje publikované v síti Internet jako součást České národní bibliografie. Ikaros [online], 2000, č. 6. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/2000/c06/elzdroje.htm.
Cobra+ : Computerised Bibliographic Record Actions [online]. Boston Spa (Velká Británie) : COBRA+, 1997. Dostupný z: <URL: http://portico.bl.uk/gabriel/en/projects/cobra.html.
DOI, the Digital Object Identifier System [online]. Kidlington (Oxford, Velká Británie) : International DOI Foundation, 1998, updated 4 April 2000. Dostupný z: <URL: http://www.doi.org/.
Dublin Core Metadata Initiative [online]. Dublin (Ohio, USA) : OCLC, 2000. Dostupný z: <URL : http://purl.org/dc/.
HEIJTING, Inge. Interconnectivity and the Hybrid Library. Ikaros [online], 1999, č. 10. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c10/ebsco.htm.
HORA, Michal a RICHTER, Vít. Veřejné informační služby knihoven - nový program pro občany a knihovny. Ikaros [online], 2000, č. 8. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/2000/c08/visk.htm.
JONÁK, Zdeněk. Inteligence systémů zpracování textů. Ikaros [online], 2000, č. 1. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/2000/c01/isko/z_jonak.htm.
JONÁK, Zdeněk. Krize mezilidské komunikace v období komunikační a informační exploze. Ikaros [online], 1999, č. 5. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c05/veda4.htm.
JONÁK, Zdeněk. Pojem "informace" ve světě sdíleného pojetí skutečnosti. Ikaros [online], 2000, č. 2. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/2000/c02/veda.htm.
JONÁK, Zdeněk. Pokles důvěry ve vědu jako důsledek změny paradigmatu vědy : důsledky změny paradigmatu v informační vědě. Část 1. Ikaros [online], 1999, č. 2. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c02/veda.htm .
JONÁK, Zdeněk. Reflektuje teorie informace a komunikace dostatečně na zvýšený zájem společenských věd o semiotické a komunikační aspekty života? Ikaros [online], 1999, č. 3. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c03/veda2.htm.
JONÁK, Zdeněk. TEXTQUEST: software pro obsahovou analýzu. Ikaros [online], 2000, č. 5. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/2000/c05/text.htm.
JONÁK, Zdeněk. Vztah komunikační a obsahové struktury literárního díla. Ikaros [online], 1999, č. 6. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c06/kom.htm.
KOCH, Traugott and BORELL, Maattias. Dublin Core Metadata Template [online]. Lund (Švédsko) : Lund universitetsbibliotek, 1997, last update 1997-08-20. Dostupný z: <URL: http://www.lub.lu.se/metadata/DC_creator.html.
KRČMAŘOVÁ, Gabriela. Sdílená katalogizace a CASLIN. Ikaros [online], 2000, č. 8. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/2000/c08/caslin.htm.
Metadata [online]. Bath (Anglie) : UKOLN, last updated 16-Feb-2000. Dostupný z: <URL: http://www.ukoln.ac.uk/metadata/.
Nordic Countries URN-generator : provided by the Nordic Libraries [online]. Lund (Švédsko) : Lund universitetsbibliotek, 1997. Dostupný z: <URL: http://lub.lu.se/cgi-bin/nmurn.pl.
The Nordic Metadata projects [online]. Helsinki (Finsko) : Helsinki University, 1996, last updated 21 February 2000. Dostupný z: <URL : http://www.lib.helsinki.fi/meta.
OLSON, Nancy B. Cataloging Internet Resources [online]. Dublin (Ohio, USA) : OCLC, 1997. Dostupný z: <URL: http://www.purl.org/oclc/cataloging-internet.
PAPÍK, Richard. Trendy v rozvoji informačních služeb. Ikaros [online], 1999, č. 8. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c08/usti/usti_papik.htm.
POKORNÝ, Jaroslav. Elektronické časopisy a jejich vliv na infrastrukturu vědeckých znalostí. Ikaros [online], 1999, č. 8. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c08/ústi_pokorny.htm.
Projects at the Royal Library in Stockholm, Sweden [online]. Stockholm : Royal Library, updated July 1, 1999. Dostupný z: <URL: http://www.kb.se/ENG/projekt.htm.
Sborník příspěvků ze semináře CASLIN ´99 - Souborné katalogy:organizace a služby. Dostupný z: <URL: http://www.caslin.cz:7777/caslin99/prispevky.html.
Serial Item and Contribution Identifier. Dostupný z: <URL: http://sunsite.berkeley.edu/SICI/version2.html.
SICI Generator. Dostupný z: <URL: http://www.ep.cs.nott.ac.uk/~sgp/sicisend.html.
SVOBODA, Martin. Elektronické publikování. Ikaros [online], 1999, č. 3. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c03/elpubl98/index.htm .
TKAČÍKOVÁ, Daniela. Když se řekne digitální knihovna ... Ikaros [online], 1999, č. 8. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c08/usti/usti_tkacikova.htm.
UHLÍŘ, Zdeněk. "Computing in Humanities", čili: Táhneme, anebo jsme vlečeni? Ikaros [online], 1999, č. 11. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c11/computing.htm.
Uniform Resource Names (urn) Charter [online]. Reston (VA, USA) : IETF, last modified 03-Jun-99. Dostupný z: <URL: http://www.ietf.org/html.charters/urn-charter.html.
VOJTÁŠEK, Filip a CELBOVÁ, Iva. Helsinská univerzitní knihovna přívětivá vůči každému. Ikaros [online], 2000, č. 9. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/2000/c09/helsinky.htm.
VOJTÁŠEK, Filip. Knihovny zaujmou pozornost médií neobvyklými událostmi. Ikaros [online], 2000, č. 9. Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/2000/c09/tyden.htm.
Poznámka:
Výsledky práce Kooperačního
systému článkové bibliografie - báze ANL lze nalézt na WWW adrese: http://www.nkp.cz
Výsledky práce společnosti
ANOPRESS, s.r.o. lze nalézt na adrese: http://www.anopress.cz