|
1
|
- Ivana Anděrová, NKČR
- Ivo Mattern, Anopress
- Josef Kučera, Anopress
- Oddělení analytického zpracování NKČR
- Anopress
|
|
2
|
- závažnost
- významnost
- důležitost
- adekvátnost
- závažný
- významný
- důležitý
- adekvátní, odpovídající
|
|
3
|
- příslušnost
- potřebnost
- využitelnost
- příslušný
- potřebný
- využitelný
|
|
4
|
- relevance je určitý stupeň shody mezi entitami, oblastmi, prvky, jevy
- může být formální a obsahová
- má relativní charakter v závislosti na čase a místě
- relevance odpovídající konkrétní potřebě koncového uživatele se nazývá
pertinence
|
|
5
|
- relevance systému tvorby a potřeby informací
- relevance informačního systému
vzhledem k jeho funkci a postavení v komunikačním procesu
- relevance z hlediska funkcí a procesů probíhajících v informačním
systému
|
|
6
|
- relevance akvizice k informačnímu fondu a relevance obou vzhledem k funkci informačního systému
- relevance z hlediska vstupního zpracování - relevance selekčního obrazu
k dokumentu
- relevance z hlediska výstupního zpracování - relevance selekčního
předpisu k dotazu
- relevance selekčního obrazu k selekčnímu předpisu, resp. vybraného
dokumentu k dotazu
- relevance, resp. pertinence výsledku vyhledávání k informační potřebě
koncového uživatele
|
|
7
|
- relevance je definována jako počet relevantních dokumentů na výstupu /
počet všech dokumentů na výstupu systému
- relevance vyhledávání je závislá na poměru mezi úplností a přesností
vyhledávání
- úplnost (recall) a přesnost (precision) vyhledávání se měří koeficientem úplnosti a přesnosti
- optimálně: hodnota koeficientu přesnosti a úplnosti se rovná jedné
|
|
8
|
- kvalita vyhledávání závisí na tom, do jaké míry selekční jazyk odráží a
vystihuje obsah a strukturu dokumentu
na vstupu a dotazu na
výstupu
- selekční jazyk je nástroj určený k formulaci identifikačních a
obsahových údajů o dokumentu (selekční obrazu) a k formulaci dotazu
uživatele (selekčního předpisu)
- kvalita výsledku vyhledávání je určena mírou shody selekčního obrazu a
selekčního předpisu a do jaké
míry vyhovuje uživatelově informační potřebě
|
|
9
|
- syntaktická úroveň (formální přenos zpráv, elementy jazyka a jejich
vzájemné vazby, formální uspořádání)
- sémantická úroveň (přenos zpráv z hlediska obsahu, vztah elementů k
mimojazykovým entitám, vztah mezi znaky a objekty)
- pragmatická úroveň (soustavy, mezi nimiž dochází ke komunikaci - účinky
komunikace na vysílajícího a
příjemce)
|
|
10
|
|
|
11
|
|
|
12
|
- formální relevance (formální vztah poskytnuté informace k obsahu dotazu)
- vztah syntaxe
- věcná relevance ( vztah obsahu
poskytnuté informace k obsahu dotazu) - sémantický vztah
- pertinence (vztah poskytnuté informace k informační potřebě) -
pragmatický charakter
|
|
13
|
|
|
14
|
|
|
15
|
|
|
16
|
- ekonomická efektivnost (zisk, náklady, rentabilita)
- selekční efektivnost (vyhledání a poskytnutí relevantních, resp. pertinentních informací)
- flexibilita (kritéria časová a schopnost přizpůsobit se změnám)
|
|
17
|
- Propojení analytických záznamů s plnými texty a optimalizace
zpřístupnění plných textů (VaV, MKČR, 1999-2003)
- Souborná databáze Kooperačního systému článkové bibliografie -
optimalizace integrace a právy heterogenních dat (VaV, MKČR, 2000-2004)
|
|
18
|
- zdroje plných textů
- získávání plných textů
- zpracování záznamů a plných textů
- identifikace plných textů
- propojení záznamů s plnými texty
- uložení plných textů
- vyhledání a zpřístupnění plných textů
- výstupy
- uživatelé
- služby a platby
|
|
19
|
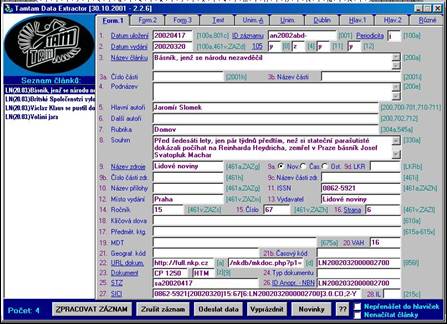
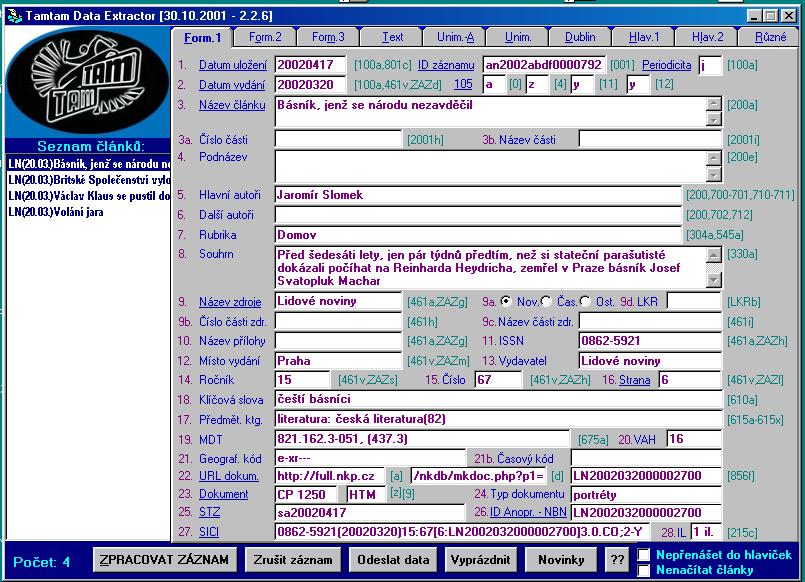
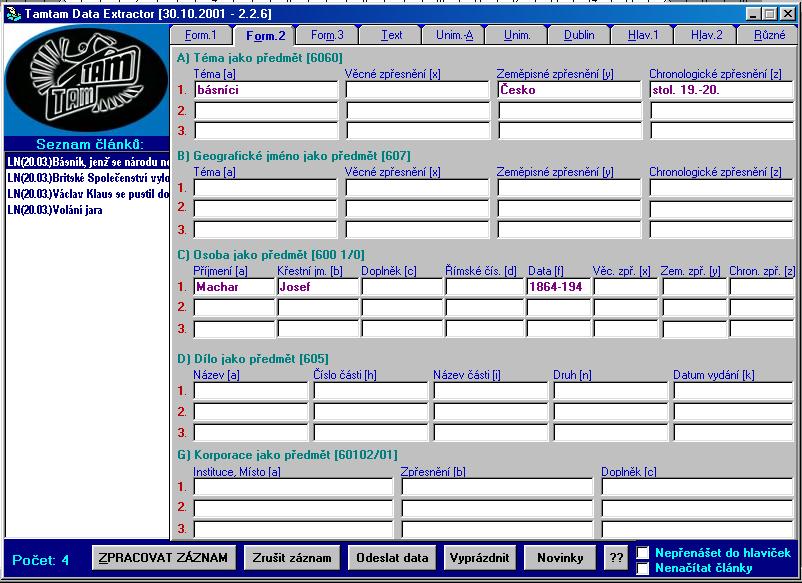
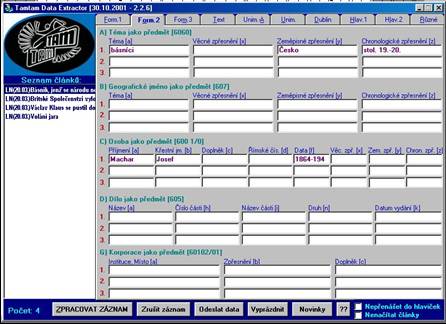
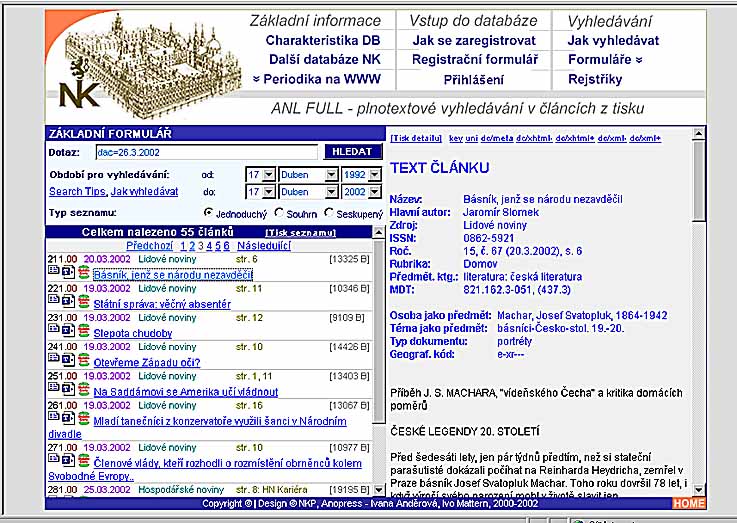
- zpracování článků v ČR - rozsáhlé co do zdrojů i typů institucí
- Kooperační systém článkové bibliografie - „užší“ a „širší“
- kooperace po linii regionální a oborové
- souborná bibliografická databáze KOSABI - ANL a lokální databáze
spolupracujících institucí, plnotextová báze ANL FULL s metadaty
|
|
20
|
|
|
21
|
- počet : ANL 710 000 bibliografických záznamů, ANL FULL 92 000 plných
textů s metadaty
- počet zpracovávaných titulů: ANL 210 v NKČR, 469 ve spolupracujících
institucích; ANL FULL 30 titulů, běžně zpracovávaných zatím 14
- časové pokrytí: ANL 1990/91 -, ANL FULL 1997-
|
|
22
|
- výběrové článkové databáze
- obory: všechny (lékařství a sport okrajově, technika posílila)
- typy seriálů (časopisy, sborníky, ročenky vydávané AVČR, vysokými
školami aj. institucemi, noviny a kulturně politické časopisy,
populárně-naučné časopisy omezeně)
- úplnost excerpce (výběr článků vzhledem k typům seriálů)
- typy článků (faktograficky přínosné, odborné, s dokumentární a uměleckou
hodnotou, recenze, biografické články, akce, rozhovory, komentáře..)
- popis (UNIMARC, AACR2, MDT-MRF, předmětové kategorie, hesla, klíčová
slova)
|
|
23
|
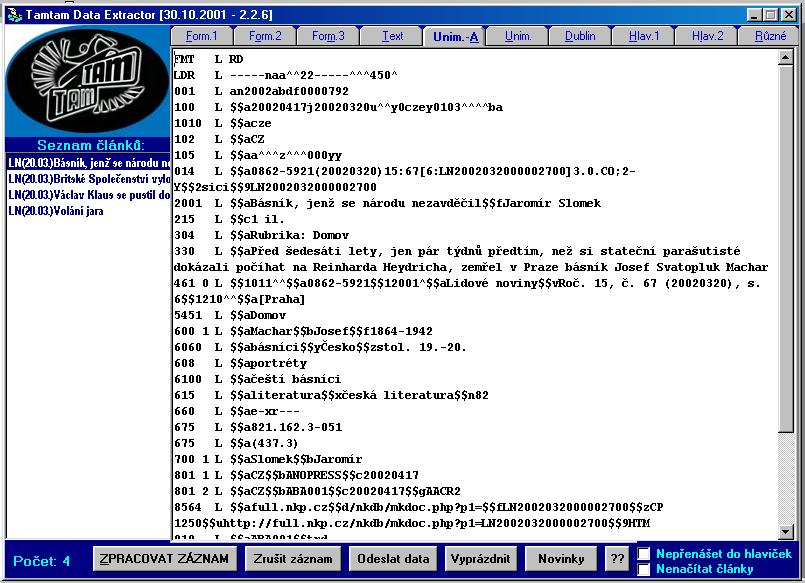
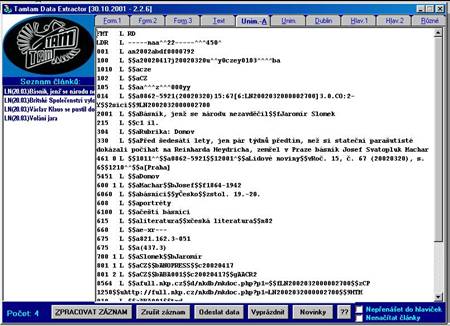
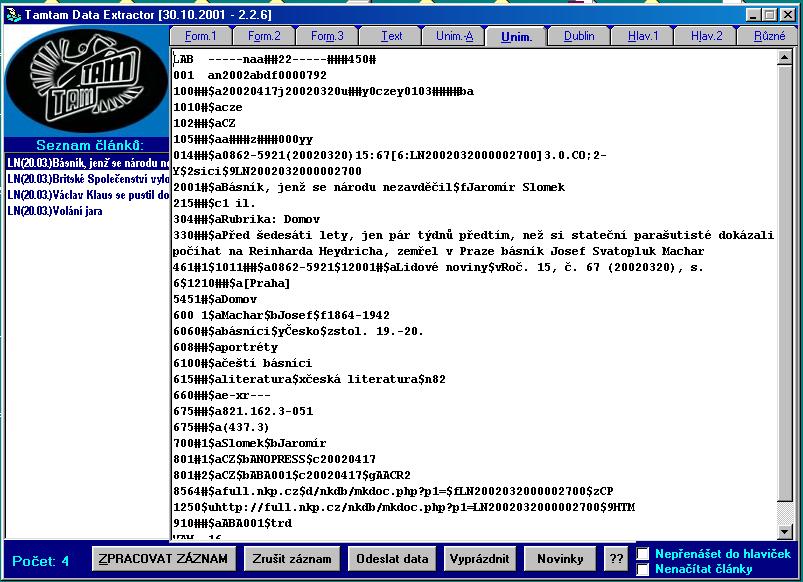
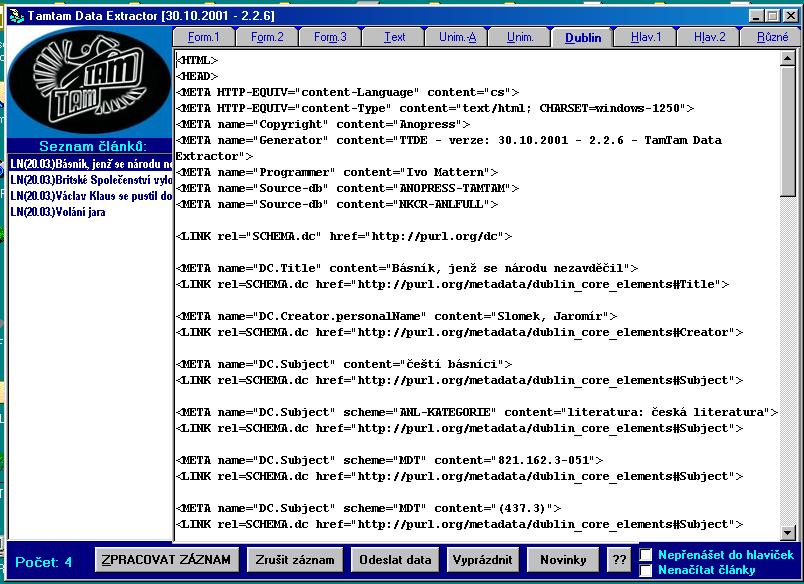
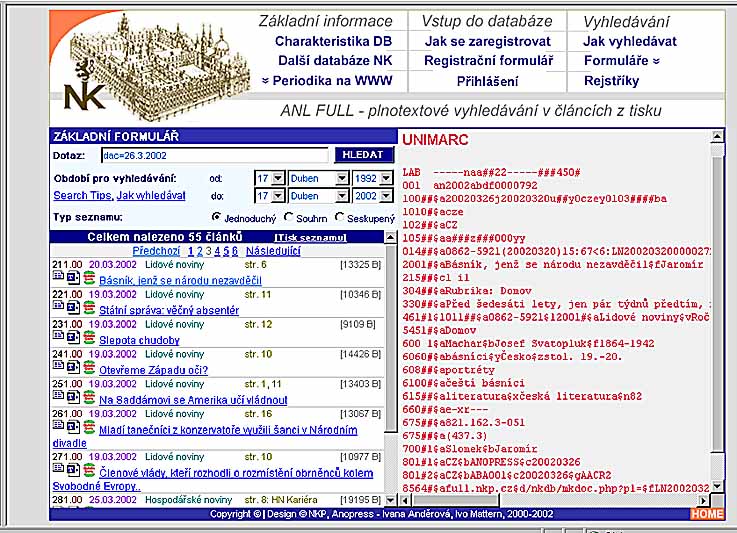
- ANL zpracovávána v sytému ALEPH+lince zpracování a zpřístupněna v ALEPH,
ANL FULL vzniká v lince zpracování TTDE a zpřístupněna v systému TOPIC
- ANL obsahuje bibliografické záznamy, ANL FULL plné texty s metadaty
- ANL obsahuje všechny typy stanovených seriálů
- ANL FULL obsahuje zatím deníky a některé
časopisy
- záznamy ANL jsou propojeny s plnými texty ANL FULL, ANL FULL doplňuje
ANL
- ANL FULL doplňuje portál volně
přístupných textů na internetu a
samostatná aplikace pro zpřístupnění periodika Národní knihovna
- ANL propojení na vybrané volně přístupné www tituly
|
|
24
|
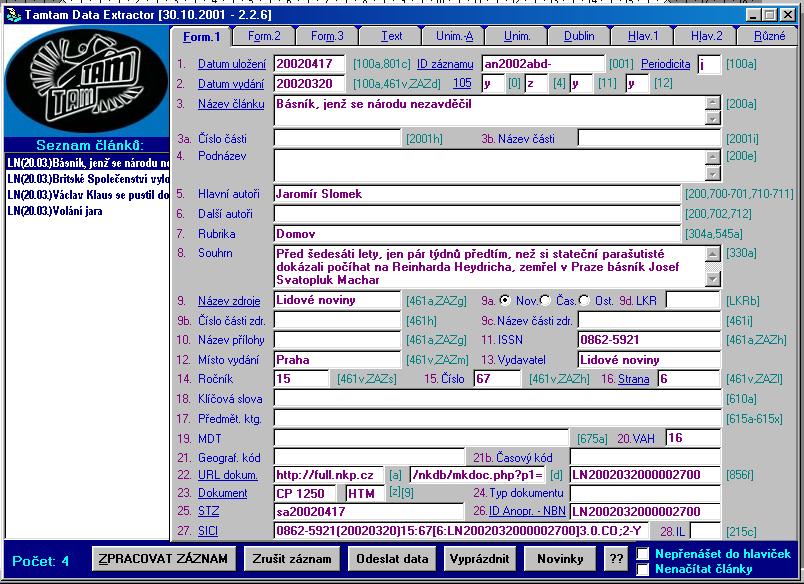
- báze ANL - přírůstek NKČR - 3266 záznamů / měsíc / 11 úvazků /
jmenný a věcný popis; zpracování v
ALEPHu a lince zpracování TTDE pro ANL/ALEPH a ANL FULL/ TOPIC, a
to:
- zpracování v ALEPHu - 1689
záznamů / měsíc / 7,25 úvazku - jmenný a věcný popis ručně, linka TTDE - 1577 záznamů / měsíc
/ 3,75 úvazku - jmenný popis extrahován a
generován automaticky, věcný popis ručně
- zpracování v ALEPHu - 11 záznamů / úvazek, zpracování v TTDE - 20
záznamů / úvazek
- báze ANL - přírůstek z kooperujících institucí:1000 záznamů / měsíc
|
|
25
|
- v současné době ANL FULL vzniká on-line v rámci linky zpracování
bibliografických záznamů, resp. metadat z plných textů, které jsou
získávány z databáze Tam Tam (Anopress)
- plné texty získány též v rámci
konzorcia Anopress, retrospektiva - nákup
- báze je provozována v systému TOPIC
|
|
26
|
|
|
27
|
|
|
28
|
|
|
29
|
|
|
30
|
|
|
31
|
|
|
32
|
|
|
33
|
|
|
34
|
|
|
35
|
|
|
36
|
|
|
37
|
|
|
38
|
|
|
39
|
|
|
40
|
- fulltextový pojmově orientovaný vyhledávací systém, pojmové vyhledávání
(concept retrieval) pomocí strukturovaných dotazů (topiců)
- přesné hodnocení důležitosti vyhledaných dokumentů vzhledem k dotazu
(relevance ranking)
- kvantifikace obsahu dokumentů
- shlukování dokumentů podle společného kontextu (clustering) a vytváření automatické anotace -
sumarizace (summarization)
- interaktivní vyhledávací systém – hledání dokumentů s podobným
obsahem - volný dotaz (Free Text
Query), dotaz příkladem (Query By Example)
|
|
41
|
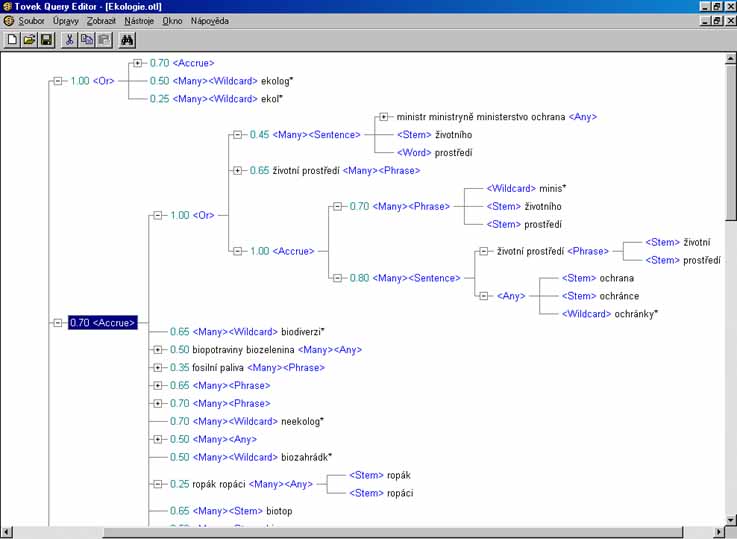
- topic je předem definovaný strukturovaný
dotaz, resp. pojem, resp. téma,
který je tvořen podpojmy, resp. podtématy, na nejnižší úrovni dále
nedělitelnými klíčovými slovy
- topic má podobu pojmového stromu,
na jeho nižších úrovních (větvích) jsou množiny dalších pojmů, resp.
témat, dále pak podpojmů, resp. podtémat, které jsou tvořeny dále
nedělitelnými klíčovými slovy (listy)
- pojmový strom tvoří vyhledávací
podmínku pro dokumenty týkající
se určitého tématu
- topic je konceptuální popis
znalosti o dané problematice ve formě znalostního stromu
- definice topiců tvoří tzv. znalostní bázi
|
|
42
|
- jednotlivé větvě topicu, pojmy resp. témata, podpojmy, resp. podtémata a
klíčová slova jsou připojeny k
vyšší úrovni operátory
- důležitost pojmů resp. témat, podpojmů resp. podtémat vzhledem k
ostatním je určena váhami
- topic se vytváří speciálním editorem
- předpoklad: dobrá znalost operátorů a orientace v dané oblasti
|
|
43
|
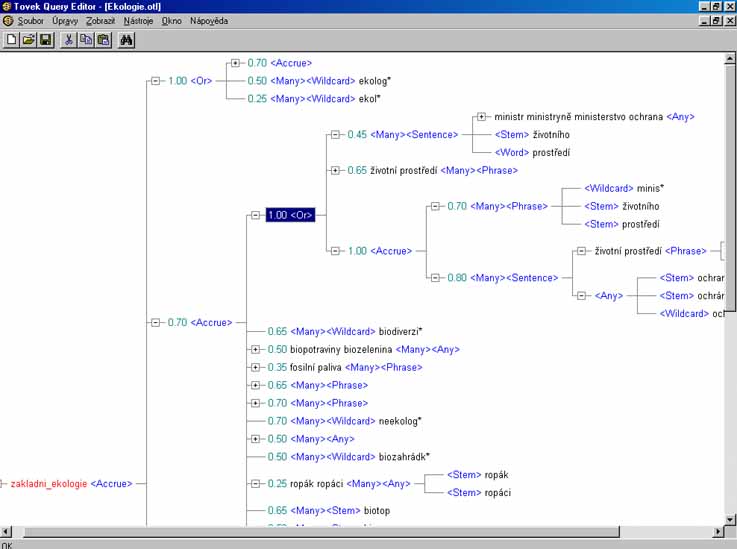
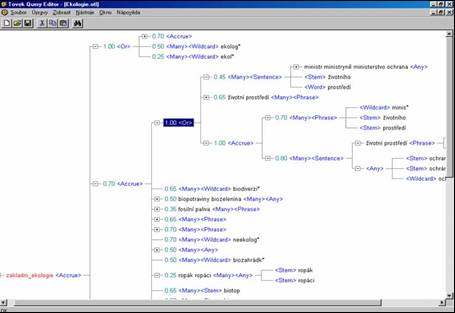
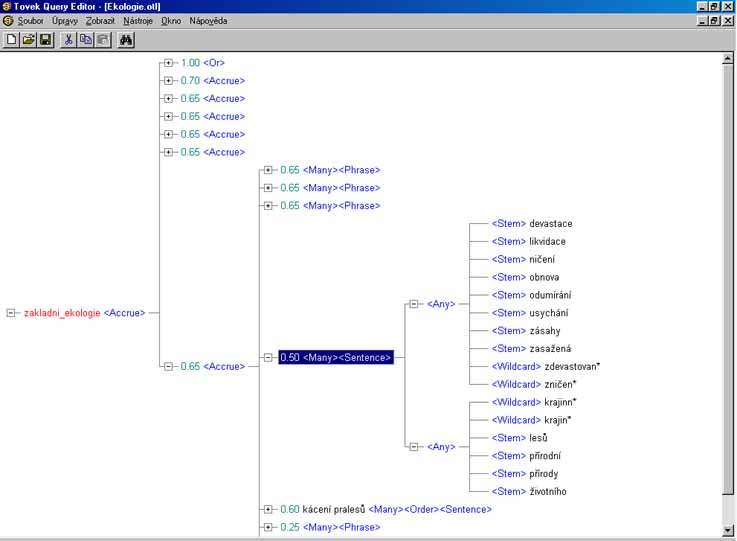
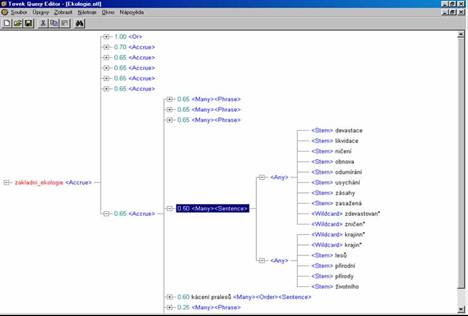
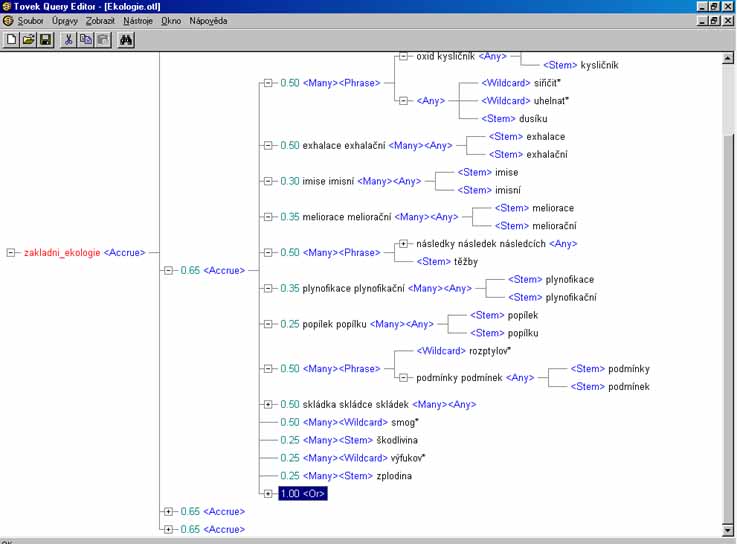
- listové operátory: WORD, STEM, SOUNDEX, WILDCARD, THESAURUS, SUGGEST a TYPO
- proximitní operátory: PHRASE, SENTENCE a PARAGRAPH
- koncepční operátory: AND, OR a ACCRUE
- logické operátory: ANY a ALL a relační
operátory: rovnost `=', větší než `>', větší nebo rovno `>=',
menší než `<', menší nebo rovno `<=', MATCHES, SUBSTRING, CONTAINS,
STARTS, ENDS
|
|
44
|
- váhy lze použít pouze u uzlů připojených pomocí koncepčních
operátorů (AND, OR a ACCRUE); pokud váhu u připojovaného uzlu
neuvedeme, použije se standardní váha - pro AND a OR 1.00, pro ACCRUE 0.50
- přiřazením váhy k určitému uzlu určujeme, jak (od 0.01 do 1.00) se
určitý uzel podílí na celkovém skóre daného dokumentu při výběru; změnou
vah je možno změnit pořadí dokumentů v seznamu dokumentů dle skóre
relevance
|
|
45
|
- ACCRUE sbližuje operátor AND a OR: “čím více různých klíčových slov
nalezeno, tím je dokument důležitější“
- ACCRUE řeší dilema mezi přesností a úplností
|
|
46
|
|
|
47
|
|
|
48
|
|
|
49
|
|
|
50
|
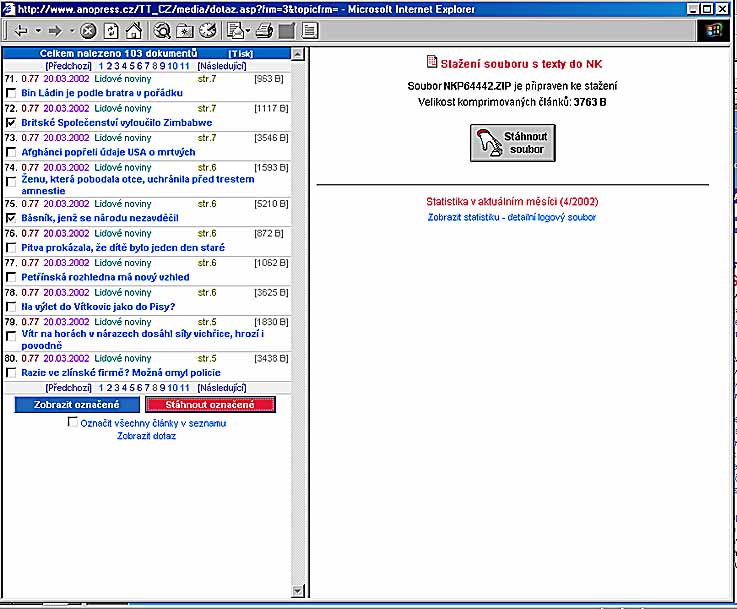
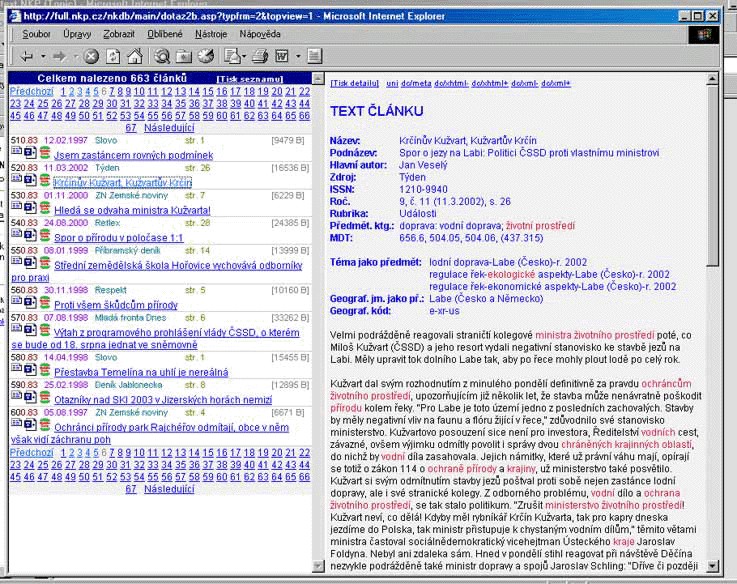
- v současné době obsahuje výběr článků z celostátních deníků, některé
kulturně politické, ekonomické tituly, periodikum Národní knihovna,
okrajově některé regionální tituly, doplněna portálem volně přístupných
textů na internetu (strukurovaný obovorově a regionálně)
- vzniká v lince zpracování bibliografických záznamů z plných textů
- přístup: interní uživatelé NK - metadata a plné texty, externí uživatele
- metadata, plné texty zkušebně na 7 dnů
|
|
51
|
|
|
52
|
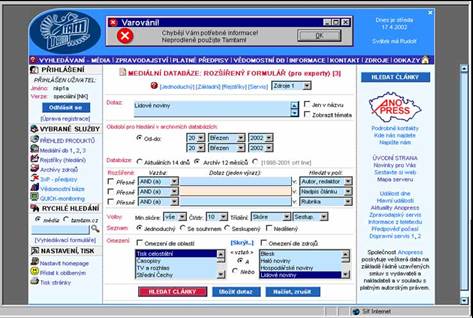
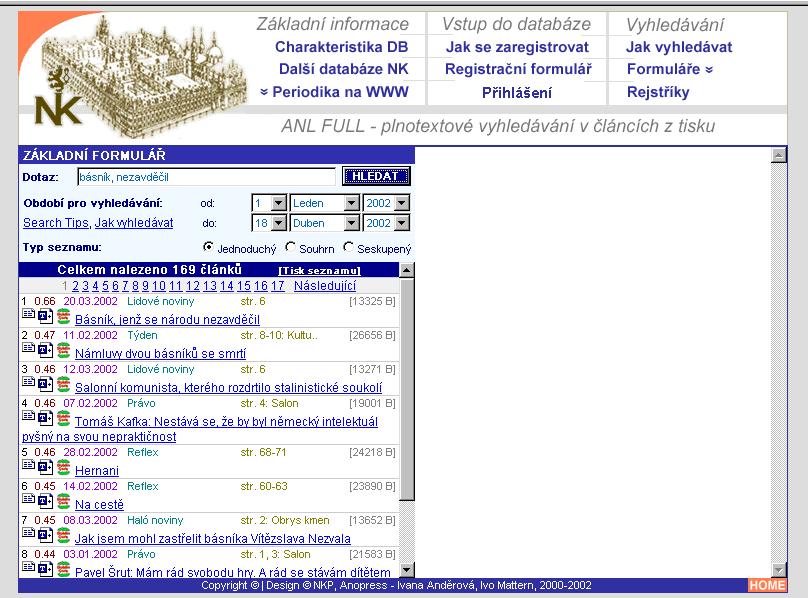
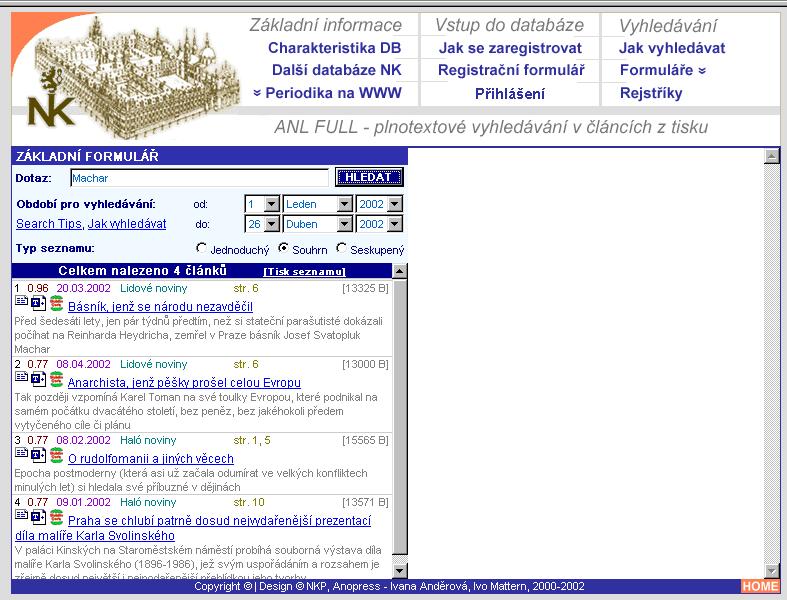
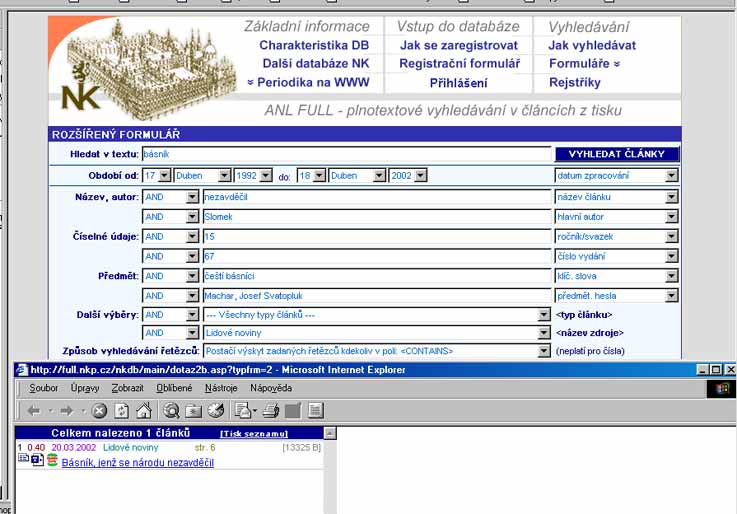
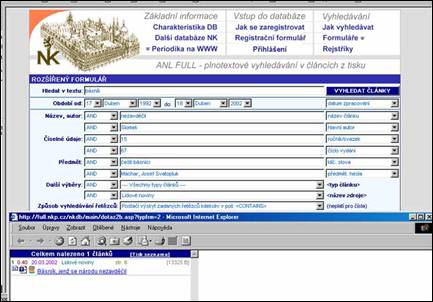
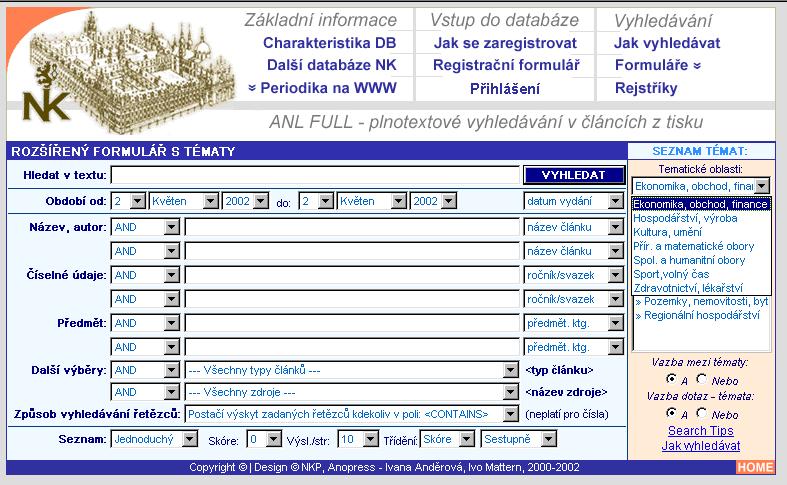
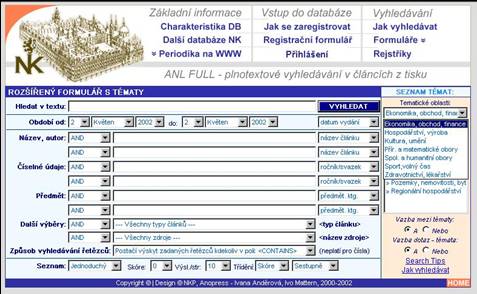
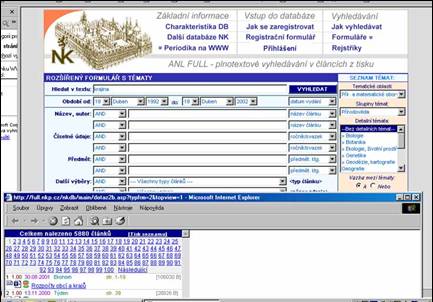
- čtyři způsoby hledání: pole dotaz, pomocí formulářů, pomocí topiců
(předem strukturovaných dotazů), pomocí rejstříků
- tři druhy dotazů: prostý dotaz, formulářový dotaz, tematický dotaz
- tři druhy formulářů: základní, rozšířený, rozšířený s tématy
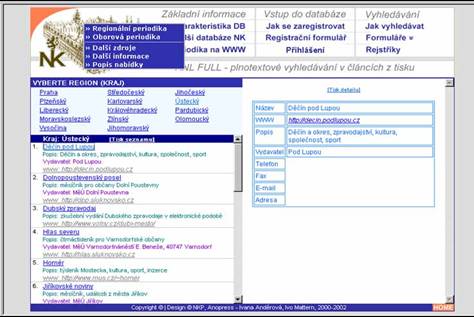
- seznam výsledků: jednoduchý, se souhrnem, seskupený
- třídění seznamu: skóre, výsl./str., vlastní třídění
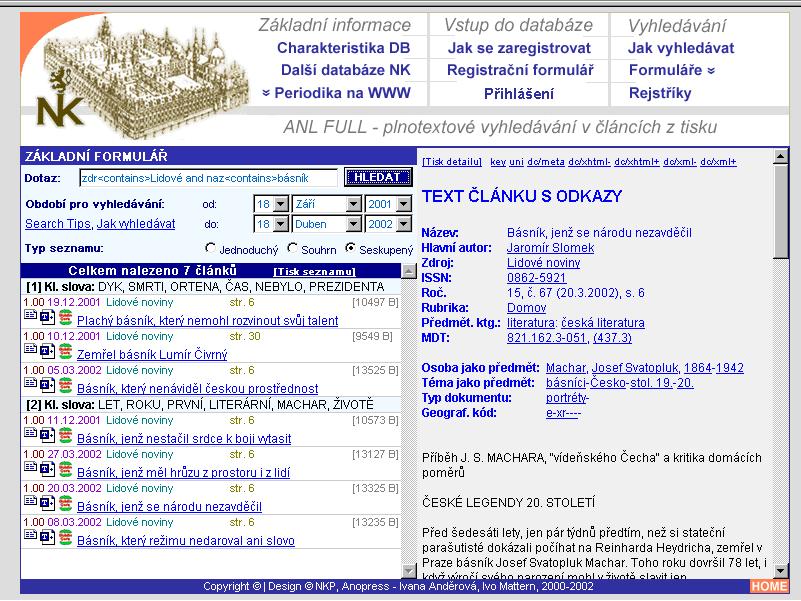
- zobrazení metadat: uživatelské formáty, pracovní formáty
- rejstříky - nadefinováno 17 rejstříků
|
|
53
|
|
|
54
|
|
|
55
|
|
|
56
|
|
|
57
|
|
|
58
|
|
|
59
|
|
|
60
|
|
|
61
|
|
|
62
|
|
|
63
|
|
|
64
|
|
|
65
|
|
|
66
|
|
|
67
|
- Marc 1
- zvážení možnosti a efektivnosti spojení automatické sklizně dat a linky zpracování
- automatická indexace věcná - do jaké míry je možná
- předpoklad automatické indexace věcné - existence homogenního nástroje
- napojení na autority
- budování digitální knihovny na základě propojování citací u odborných
článků
- řešení legislativně právních otázek a otázek plateb (jasné oddělení textů
poskytovaných zdarma a za úplatu)
- rozšíření linky zpracování na další instituce a aplikace moderních metod
zpracování a zpřístupnění na KOSABI
- orientace na další typy seriálových publikací
- pro externí uživatele zpřístupnění báze v rámci konzorcia Anopress,
resp. celostátní licence
|
|
68
|
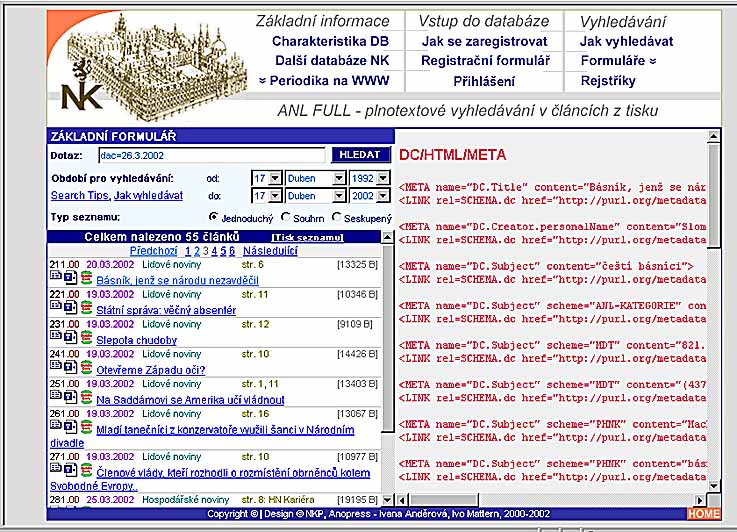
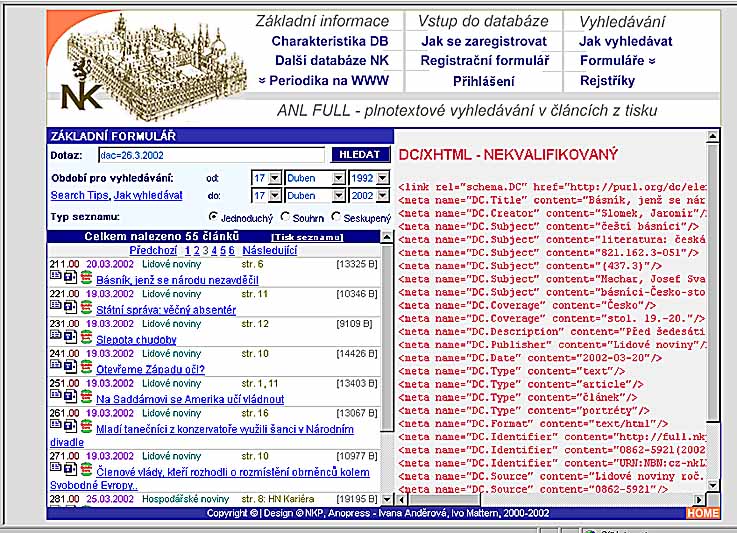
- začlenění linky zpracování do předpokládaného možného vývoje
- předpoklad: strukturované údaje, resp. údaje Dublin Core v textových
formátech, resp. HTML formátu
|
|
69
|
|
|
70
|
|
|
71
|
|
|
72
|
|
|
73
|
|
|
74
|
- strukturovat nestrukturované informace a užívat takových vyhledávacích
systémů, které mají kvalitní nástroje k uchopení nestrukturovaných
plných textů, protože tyto ve velké míře převažují
- propojovat věcný selekční jazyk se systematickou notací, zapojovat
autority, aplikace pojmového vyhledávání
- interakce mezi uživatelem, informačním pracovníkem a informačním
systémem
|
|
75
|
|
|
76
|
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}