|obsah| |index autorů | | index názvů | | index témat | | archiv |
Knihovna
2012, ročník 23, číslo 2, s. 35-47
Zuzana Kratochvílová
Resumé
Článek rozebírá problémové oblasti a možnosti dlouhodobého uchování dat z webových archivů. Povaha webových zdrojů může oproti klasickým digitálním dokumentům do značné míry komplikovat jejich dlouhodobou ochranu a zpřístupnění. Je nastíněna problematika metadat pro webové archivy. Současný stav řešení je představen na příkladu WebArchivu Národní knihovny České republiky.
Klíčová slova: webové archivy, dlouhodobá ochrana digitálních dokumentů, metadata, WebArchiv
Summary
The article surveys the problem areas and possibilities of long-term preservation of data from web archives. Unlike conventional digital documents the nature of web resources can largely complicate their long-term preservation and access. It outlines the problems of metadata for web archives. Current state of solution in WebArchiv of National Library of the Czech Republic is introduced.
Keywords: web archives, digital preservation, metadata, WebArchiv
Projekt Národní knihovny České republiky (dále NK ČR) WebArchiv má za sebou více jak deset let své existence. Z pilotního projektu Registrace, ochrana a zpřístupnění domácích elektronických zdrojů v síti Internet, který probíhal v letech 2000-2001 (Celbová, 2001), se postupně přesunul do provozní fáze. V současnosti jde již o plně etablovaný a fungující projekt NK ČR.
Cílem WebArchivu je archivovat české webové zdroje - bohemikální dokumenty - a zajistit jejich dlouhodobé uchování a zpřístupnění. Internet se stal hlavním publikačním médiem dnešní doby, neustále narůstá počet elektronických/webových dokumentů a online publikací. Dynamická povaha Internetu ale způsobuje, že se webové stránky mění, přesouvají nebo zcela nenávratně mizí. Průměrná životnost stránky je dle společnosti Alexa Internet odhadována na 75 dní (Day, 2003). Pokud tyto zdroje nebudou archivovány, ztratí se významná součást národního kulturního dědictví.
Archivace je prováděna na základě třech přístupů, které se vzájemně doplňují:
Jedná se o celoplošnou sklizeň TLD1 domény .cz. Tato sklizeň probíhá jedenkrát ročně na základě seznamu registrovaných domén poskytnutého sdružením CZ.NIC2. Její průměrná velikost se pohybuje kolem 10 TB. Podle platné české legislativy je přístup k těmto datům omezen pouze na prostory NK ČR.
V rámci výběrových sklizní jsou archivovány zdroje vybrané na základě selekčních kritérií3. Výběrová archivace probíhá několikrát ročně a představuje jádro WebArchivu. Pro online zpřístupnění mimo prostory NK ČR je třeba získat souhlas vydavatele. Průměrná velikost měsíční sklizně je 1-2 TB dat.
Tematické sklizně jsou věnovány významným událostem, které se vztahují k České republice a které provází větší společenský ohlas. Celkem proběhlo 12 tematických sklizní4, poslední byla věnována úmrtí Václava Havla.
Pro sklízení a zpřístupňování dat jsou používány opensource nástroje vyvinuté konsorciem IIPC (International Internet Preservation Consortium5) a Internet Archive6. Sklízení webových zdrojů probíhá automaticky pomocí sklízecího robota (angl. crawler) Heritrix7, který data ukládá do formátu ARC, resp. od září 2012 do formátu WARC. Sklizně jsou následně zaindexovány a pomocí nástroje Wayback Machine8 zpřístupněny online. Pro správu zdrojů je používán systém WA Admin 2. Ke dni 12. 9. 2012 WebArchiv obsahoval 91 TB dat.
Do dnešní doby se většina aktivit v oblasti archivace webu soustředila především na vývoj strategií a nástrojů pro sklízení webu a na zajištění aktuálního přístupu k archivovaným zdrojům. Z dlouhodobého hlediska bude ale záležet na schopnosti uchovat a zpřístupnit archivované webové zdroje do budoucna, což již spadá do oblasti dlouhodobé ochrany digitálních dokumentů.
Dlouhodobá ochrana digitálních dokumentů, neboli digital preservation, je definována jako soubor "systematických opatření pro zajištění uchování, ochrany, integrity a dostupnosti digitálních dokumentů v dlouhodobém horizontu" (Cubr, 2003). Digitální informace jsou ukládány ve formě bitů, které samy o sobě nemají žádný význam. K jejich zprostředkování do do podoby srozumitelné pro člověka je třeba odpovídající technologické a technické zajištění. Vytváří se síť vzájemně propojených komponent (software, operační systém, hardware, média pro ukládání, jejich celkové vzájemné nastavení …), přičemž je nutné zajistit funkčnost každé z nich, aby uložená data mohla být zpřístupněna. Z tohoto pohledu je dlouhodobého uchování dat nejen z webových archivů spojeno s několika okruhy problémů:
Data z webových archivů se oproti "klasickým" digitálním dokumentům vyznačují specifickými vlastnostmi, které mohou ve větší míře znesnadňovat jejich dlouhodobé uchování.
Neexistuje žádná organizace, která by byla zodpovědná za web. Internetové prostředí bylo a je budováno na principu decentralizace, žádná vláda, úřad nebo instituce nemá mandát k tomu vyžadovat dodržování standardů nebo prosazovat jednotnou politiku dlouhodobé ochrany webových stránek (Day, 2003). Organizace jako W3C Consortium zveřejňují standardy, jedná se ale pouze o doporučení, záleží tedy na každém tvůrci webových stránek a interpretaci kódu prohlížečem, jaká bude jejich výsledná podoba. Webové zdroje jsou sklízeny a ukládány v podobě, v jaké byly zveřejněny na Internetu. Při jejich archivování nelze tedy vycházet z předpokladu, že všechny odpovídají jednomu standardu a že stačí nastavit jednotný postup pro jejich archivaci.
S tímto souvisí velké množství heterogenních formátů. Webové archivy obsahují nejenom HTML kód stránek, součástí jsou také obrazové a audiovizuální dokumenty, flashové a javascriptové aplikace, kaskádové styly, textové dokumenty. Stručný výčet nejpoužívanějších textových formátů (DOC, DOCX, TXT, RTF, PDF, ODT, XML …) převyšuje současný počet formátů plánovaných pro ukládání do LTP9 úložiště NK ČR (JPEG, JPEG 2000, XML, WARC, zvažuje se PDF/A a ePUB). Z dlouhodobého hlediska to znamená udržovat webový archiv doslova "plný" nejrůznějších formátů a zajistit jejich zpřístupnění.
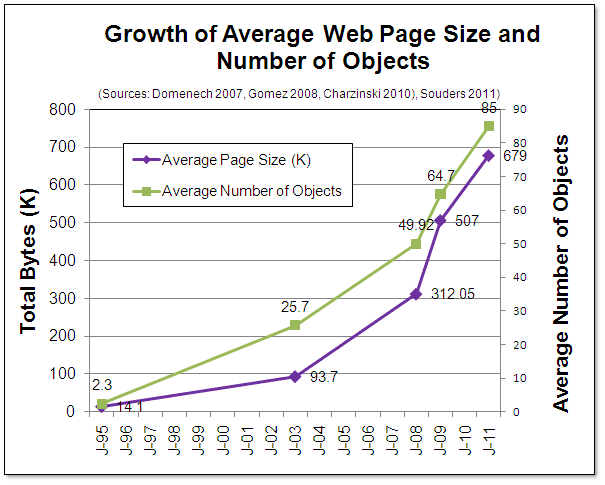
Webové stránky se skládají nejenom z různých formátů, které jsou mimo kontrolu archivu, ale navíc se ve většině případů nejedná o samostatné objekty, které by nebyly provázány s jinými objekty v rámci jedné stránky, nebo o samostatnou stránku, která by nebyla provázána s jinými stránkami v rámci jedné domény nebo domén. Anglické označení web neboli síť, plně vystihuje komplexní povahu webových zdrojů, které jsou vzájemně propojeny. Server WebSiteOptimization.com (Website Optimization, 2011) uvádí průměrný počet 85 objektů na stránku v roce 2011, kdežto v roce 2003 se webová stránka skládala z 30 objektů. Data uložená ve webových archivech by se při zobrazení měla chovat stejně jako stránky na živém webu (propojení pomocí hypertextových odkazů, adresářová struktura). Zachování této struktury a funkcionality je jedním z dalších požadavků na webové archivy. Jak zdůrazňuje Adrian Brown (Brown, 2006), archivace webových zdrojů zahrnuje nejenom uchování individuálních objektů, ale také zachování vztahů mezi nimi, takže celek může být obnoven z jeho jednotlivých částí. Musí existovat popis vztahů (často zahrnutý v samotném kódu stránek) a pokud v rámci akcí spojených s dlouhodobou ochranou dojde ke změně jedné části, musí dojít ke změně všech částí souvisejících. Např. webová stránka obsahuje obrázek ve formátu GIF, v HTML kódu stránky je uveden tag <img>, který na něj odkazuje. Proběhne migrace všech obrazových dokumentů ve formátu GIF do formátu PNG, tím pádem je třeba změnit i odkaz <img> v HTML kódu stránek, aby odkazoval na obrázek ve správném formátu10.
Obr. 1: Velikost a počet objektů průměrné webové stránky (Website Optimization, 2011)
Dalším úkolem a specifikem dat z webových archivů je zachovat chování webové stránky, které vzniká na základě interakce mezi uživatelem a serverem. Celosvětově se webové archivy potýkají s problémem, jak archivovat chování založené na skriptovacích jazycích a dynamickém obsahu. Ukazuje se, že archivace na straně serveru založená na extrakci odkazů ze zdrojového kódu stránek je čím dál tím méně vhodná, proto se vývoj ubírá směrem k simulaci chování webového prohlížeče11. Dalším z možných řešení je sledování chování uživatele a zachycení transakcí, které proběhly mezi ním a systémem, nebo uchování pravidel, na kterých je založeno chování stránky, aby mohlo být obnoveno za použití jiných technologií.
V neposlední řadě webové archivy schraňují velké objemy dat. Odhadovaná velikost viditelného webu je ke dni 10. 9. 2012 dle serveru WorldWideWebSize.com 8,85 miliard stránek (Kunder, 2012). Jedná se o statistické odhady na základě analýzy největších vyhledávačů. V roce 2005 odhadli na podobném principu A. Gulli a A. Signorini velikost webu na 11,5 miliard stránek (Coufal, 2012). Ačkoli webové archivy uchovávají pouze zlomek z celkové velikosti webu, jedná se o velké objemy dat, které dosahují řádu stovek TB až PB (Internet Archive uvádí velikost 5,8 PB v roce 2010 (Internet Archive, 2010)), což klade velké nároky na pravidelné zajištění dostatečných úložných kapacit (naplánovaný roční přírůstek WebArchivu je 30 TB dat) a s tím souvisejících finančních prostředků na jejich nákup. Zároveň je s touto velikostí třeba počítat i při jakémkoli nakládání s archivem a procesech s ním spojených.
Získaná data jsou nejčastěji ukládána do tzv. kontejnerových formátů (angl. container format). Umožňují ukládat do jednoho "balíčku" různé typy dat v různých formátech. Snižuje se tím množství souborů, se kterými je třeba nakládat, z řádově stovek milionů na desítky až stovky tisíc. Obsah kontejnerového formátu tvoří sled záznamů pro každý sklizený objekt webové stránky uvedený krátkou hlavičkou a následovaný vlastním obsahem. Mnoho institucí používá formáty ARC12 nebo WARC13. Internet Archive vytvořil v roce 1996 specifikaci kontejnerového formátu ARC jakožto formátu pro archivovaná data. ARC agreguje data do 100 MB velkých balíčků. Balík ARC se skládá ze dvou částí – jednoduché hlavičky a vlastních záznamů sklizených objektů.
Př. Ukázka hlavičky ARC záznamu
Version Block – společný pro celý soubor ARC
filedesc://SERIALS-2011-03-1M_6M-20110406141225-00000-tar.webarchiv.cz.arc 0.0.0.0 20110406141225 text/plain 1397
1 1 InternetArchive
URL IP-address Archive-date Content-type Archive-length
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
ARC metadata
<arcmetadata xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:arc="http://archive.org/arc/1.0/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://archive.org/arc/1.0/" xsi:schemaLocation="http://archive.org/arc/1.0/ http://www.archive.org/arc/1.0/arc.xsd">
<arc:software>Heritrix 1.14.4 http://crawler.archive.org</arc:software>
<arc:hostname>tar.webarchiv.cz</arc:hostname>
<arc:ip>10.3.0.34</arc:ip>
<dcterms:isPartOf>Archive-It-2011-04</dcterms:isPartOf>
<dc:description>mimoradna sklizen novych serialu s pulrocni, rocni a jednorazovou frekvenci k 31.3.</dc:description>
<arc:operator>Admin</arc:operator>
<dc:publisher>WebArchiv</dc:publisher>
<dcterms:audience>NK</dcterms:audience>
<ns0:date xmlns:ns0="http://purl.org/dc/elements/1.1/" xsi:type="dcterms:W3CDTF">2011-04-06T14:12:18+00:00</ns0:date>
<arc:http-header-user-agent>Mozilla/5.0 (compatible; heritrix/1.14.3 +http://www.webarchiv.cz)</arc:http-header-user-agent>
<arc:http-header-from>webarchiv@nkp.cz</arc:http-header-from>
<arc:robots>ignore</arc:robots>
<dc:format>ARC file version 1.1</dc:format>
<dcterms:conformsTo xsi:type="dcterms:URI">http://www.archive.org/web/researcher/ArcFileFormat.php</dcterms:conformsTo>
</arcmetadata>
Hlavička konkrétního záznamu
http://atopicky-ekzem.net/robots.txt 88.208.119.208 20110406141225 text/plain 1909
HTTP/1.1 200 OK
Date: Wed, 06 Apr 2011 14:12:26 GMT
Server: Apache
Last-Modified: Thu, 20 Jan 2011 12:09:58 GMT
ETag: "15f2209-624-49a4603253180"
Accept-Ranges: bytes
Content-Length: 1572
Cache-Control: max-age=1209600
Expires: Wed, 20 Apr 2011 14:12:26 GMT
Vary: Accept-Encoding
Connection: close
Content-Type: text/plain
Následuje vlastní obsah staženého záznamu
Na základě zkušeností získaných v průběhu let mezi členy IIPC se ukázalo jako vhodné rozšířit původní formát ARC o další popisné informace. Byla ustanovena pracovní skupina pro formát WARC (Web ARChive), který byl v roce 2009 přijat za mezinárodní normu ISO 28500:2009. Doporučená velikost byla navýšena na 1 GB. WARC umožňuje uchovávat kromě vlastního obsahu další související informace a metadata. Rozlišuje se osm typů WARC záznamů: Warcinfo, Response, Resource, Request, Metadata, Revisit, Conversion, Continuation (ISO, 2009). Warcinfo record slouží k popisu WARC souboru a obsahu, který bude následovat. Ostatní WARC záznamy popisují komunikaci klient/server, alternativní verze WARC souborů (např. po migraci) a související WARC soubory.
Př. Ukázka hlavičky WARC záznamu
Hlavička Warcinfo – společná pro celý soubor WARC
WARC/1.0
WARC-Type: warcinfo
WARC-Date: 2011-10-21T10:37:31Z
WARC-Filename: TEST-WARC--20111021103731-00000-har.webarchiv.cz.warc.gz
WARC-Record-ID: <urn:uuid:9ec9294b-98b6-4364-9087-0483d2822d0e>
Content-Type: application/warc-fields
Content-Length: 489
WARC metadata
software: Heritrix/1.15.5 http://crawler.archive.org
ip: 10.3.0.33hostname: har.webarchiv.cz
format: WARC File Format 1.0
conformsTo: http://bibnum.bnf.fr/WARC/WARC_ISO_28500_version1_latestdraft.pdf
operator: Admin
publisher: WebArchiv
audience: NK
isPartOf: Test-WARC-Rudolf-prodisedi.cz
description: testovaci sklizen - ticket #
robots: ignore
http-header-user-agent: Mozilla/5.0 (compatible; heritrix/1.14.3 +http://www.webarchiv.cz)
http-header-from: webarchiv@nkp.cz
WARC response hlavička
WARC/1.0
WARC-Type: response
WARC-Target-URI: dns:www.protisedi.cz
WARC-Date: 2011-10-21T10:37:30Z
WARC-IP-Address: 195.113.132.45
WARC-Record-ID: <urn:uuid:f31f37a7-8584-44ec-86cc-9f85de0181cc>
Content-Type: text/dns
Content-Length: 52
3. Strategie dlouhodobého uchování a možnosti jejich použití pro data z webových archivů
Existuje několik přístupů k dlouhodobé ochraně digitálních dokumentů. Obecně je lze rozdělit do dvou kategorií: 1) dlouhodobě neudržitelné metody, jako jsou např. žádné opatření, technologické muzeum nebo prostá záloha; 2) dlouhodobě udržitelné metody, jako jsou emulace a migrace, které by měly zajistit zobrazení archivovaného obsahu v budoucnu.
Pokud se zaměříme na aktivní aspekt dlouhodobé ochrany, jedná se v současné době o volbu mezi emulací a migrací, resp. i jejich vzájemnou kombinací. A. Long (Long, 2009) poukazuje na skutečnost, že existující silná polarizace názorů, která z těchto dvou metod je vhodnější, se zdá být z velké části založena na osobním přesvědčení, spíše než na konkrétních empirických důkazech. Ve skutečnosti nevíme, která z nich se ukáže udržitelnější v dlouhodobém horizontu.
Emulace je založena na simulování funkcionality původního, a tedy zastaralého, technického prostředí. Znamená vyvinutí softwarových nástrojů (emulátorů), které napodobují chování originálních technologií, ale které fungují na současných systémech. Výhodou emulátorů je, že zachovávají autentický vzhled a chování digitálních objektů, na druhou stranu vytváření emulátorů zahrnuje neustálé sledování změn a programování nových emulátorů, které se ve výsledku mohou vzájemně řetězit.
Z pohledu webových archivů představuje emulace vhodnou strategii pouze částečně. Webové prohlížeče mohou být implementovány na nejrůznějších platformách, vybrat vhodnou kombinaci hardwaru a softwaru pro emulaci může být proto do značné míry obtížné a v podstatě libovolné. Webové standardy a technologie, které prohlížeče podporují, se v průběhu času mění, z tohoto důvodu může být důležité zachovat různé verze prohlížečů, aby se stránky zobrazily správným způsobem. S tím souvisí také uchování pluginů a souvisejících používaných technologií a znalostí o nich (Masanès, 2006).
Migrace ve smyslu dlouhodobé ochrany představuje konverzi digitálního objektu z originálního (zastaralého) formátu do formátu nového, který je podporován současnými technologiemi. Existuje několik přístupů k migraci z hlediska jejího načasování (Brown, 2006):
Podle M. Daye (2006) může být migrace aplikována na většinu webového obsahu. Ačkoli mohou webové archivy obsahovat dokumenty v téměř jakémkoli formátu, praktické zkušenosti a výzkumy naznačují, že se jedná o relativně malý počet několika nejpoužívanějších formátů (HTML 48 %, GIF 25 %, JPEG 20 %, PDF 3 %). Úspěšná migrace vyžaduje detailní analýzu a identifikaci významných vlastností objektů, které by měly zůstat zachovány i při přechodu na nový formát. Ačkoli se ve výsledku může jednat o malý počet formátů, jednotlivé verze se od sebe mohou významně lišit (viz například balíčky Microsoft Office 1997 vs. Microsoft Office 2010). Jako hlavní nevýhoda migrace je uváděna možná ztráta významných vlastností a chování digitálních objektů. Jak již bylo zmíněno, u webových archivů je migrace složitější v tom smyslu, že se jedná o komplexní objekty, tj. pokud dojde k migraci obrazového dokumentu, musí se přepsat všechny odkazy na něj v ostatních souborech. Navíc migrace jednoho typu formátu neřeší zobrazení kompletní stránky.
Pro úspěšnou realizaci jakékoliv dlouhodobé strategie je klíčové zachycení vhodných metadat. Cílem tohoto článku není podat detailní analýzu metadat pro dlouhodobou ochranu digitálních dokumentů. Následující kapitola představuje uvedení do problematiky metadat vhodných pro dlouhodobé uchování a zpřístupnění z pohledu webových archivů, stručně jsou nastíněna již aplikovaná řešení ve světě.
Metadata jsou chápána jako různé typy dat, které popisují strukturu a obsah digitálních dat a umožňují jejich vyhledání, zpřístupnění a zaznamenání kontextových informací (Brown, 2006). U webových zdrojů je klíčovým aspektem detailní zachycení technických metadat a popis jejich technologické závislosti.
Metadatový popis lze vytvořit k různým aplikačním úrovním webových zdrojů uložených v archivu. Odvíjí se od struktury, v jaké je plánované jejich uložení do digitálního repozitáře. Může se vztahovat ke sbírce jako takové, např. v případě tematicky zaměřených kolekcí. Dále může být popsána jednotlivá sklizeň, webový zdroj, samostatná stránka nebo dokument. Může být také důležité popsat komunikaci mezi sklízecím robotem a serverem.
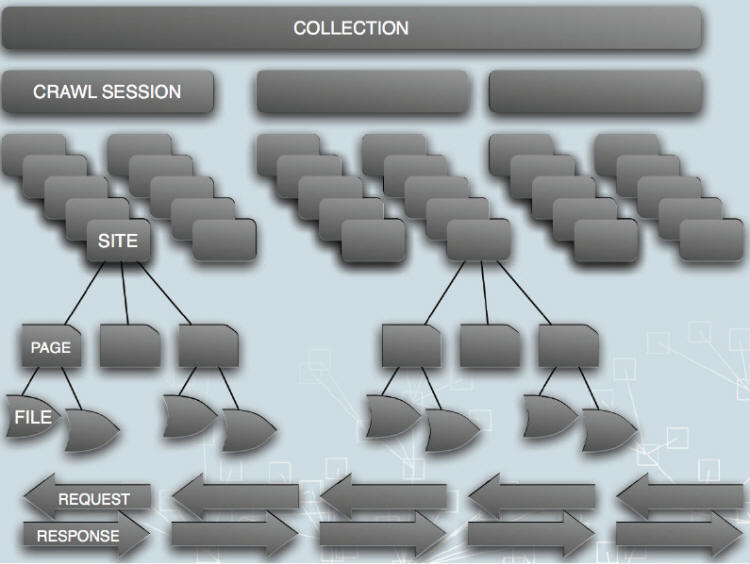
Obr. 2: Úrovně, ke kterým se může vztahovat metadatový popis (Masanès, 2005)
Některá metadata jsou generována přímo nástroji použitými pro archivaci a správu zdrojů. Heritrix vytváří soubor logů a reportů, které souvisí s nastavením a průběhem sklizně (Crawl.log, Local-errors.log, Progress-statistics.log, Uri-errors.log, Runtime-errors.log, Journal-log, Crawl-report.txt, Crawl-manifest.txt, Host-report.txt, Mimetype-report.txt, Processors-report.txt, Responsecode-report.txt, Seeds-report.txt, Seeds.txt, Order.xml, Settings.xml, State.job). Generuje také metadata vztahující se k jednotlivým archivovaným objektům a ta ukládá do hlaviček ARC/WARC souborů. Metadata vytvářená Heritrixem představují technický popis sklizně. Popisná metadata jsou generována nástroji pro správu zdrojů, např. Web Curator Tool14, NetarchiveSuite15 nebo WA Admin 2 používaný v NK ČR.
Vlastní návrhy metadatového formátu pro archivované webové zdroje si vytvořilo několik knihoven, např. Národní knihovna Francie (BNF), Národní knihovna Nového Zélandu (NLNZ) a Britská knihovna (BL). BNF používá kombinaci metadatových formátů METS a PREMIS a k doplnění dalších technických informací, které nejsou obsaženy v ARC, vyvinula vlastní formát ContainerMD (Oury, 2011); popisovanou intelektuální entitou je ARC. NLNZ používá kombinaci METS, Dublin Core a VCard, který slouží pro popis osob. Popisovanou intelektuální entitou je WARC. V BL aplikovali kombinaci METS, MODS, Dublin Core a PREMIS, popisovanou entitou je webové sídlo (Kvasnica, 2012).
WebArchiv je součástí projektu "Vytvoření Národní digitální knihovny" (dále NDK16), který řeší NK ČR od roku 2010. Spolu s Manuscriptoriem17 a Krameriem18 je hlavním dodavatelem digitálních dat pro NDK. Řešení se v roce 2012 zaměřilo na detailní analýzu a definování požadavků na ukládání a zpřístupnění dat z WebArchivu v plánovaném LTP úložišti. Byla navrhnuta dvouúrovňová struktura:
Byl vytvořen návrh metadatového formátu pro popis sklizně. Pro technická a administrativní metadata bude použit PREMIS, MODS pro popisná metadata a pro strukturální metadata METS.
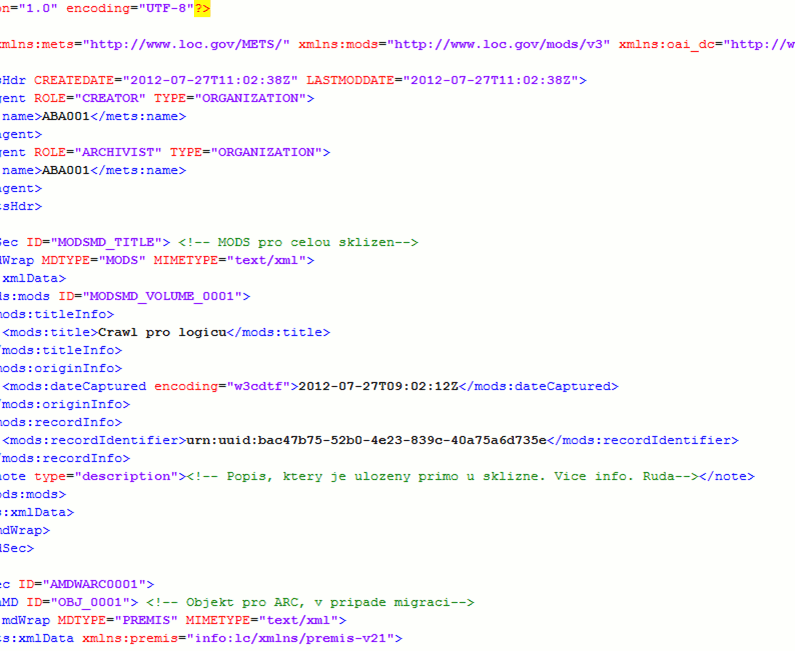
Obr. 3: Náhled navrhovaného metadatového formátu pro sklizeň
V řešení je způsob migrace ARC souborů. Do srpna 2012 se data ukládala do formátu ARC, od září 2012 se přešlo na sklízení do formátu WARC. V zadávací dokumentaci projektu NDK se předpokládá, že data z WebArchivu budou ukládána do LTP úložiště ve formátu WARC. Je tedy třeba vyřešit konverzi z formátu ARC do formátu WARC. V současné době jsou nejdostupnějším migračním nástrojem WARC Tools19 od společnosti Hanzo Archives, ale (na základě našich vlastních testů i zkušeností jiných institucí z IIPC) doposud nebyly velmi spolehlivé (Prokop, 2012). Je naplánována detailní analýza většího objemu dat před a po migraci a na základě získaných výsledků bude navržen další postup řešení. Výstupy této analýzy a zpracování doporučení pro migraci ARC-WARC souborů a návrh metadatového formátu pro data z webových archivů se mohou stát významným přínosem NK ČR pro ostatní členy IIPC.
Dlouhodobá ochrana dat z webových archivů je stále otevřenou oblastí. Aktivity v oblasti archivace webu se do dnešní doby soustředily především na vlastní archivaci a aktuální zpřístupnění webových zdrojů. Stanovení vhodných postupů pro aktivní dlouhodobou ochranu webových dat bude vyžadovat ještě značné úsilí a spolupráci různých institucí. Klíčová pro dlouhodobou ochranu jsou metadata, a to nejen popisná, ale hlavně technická a metadata o událostech, které se s daty udály. NK ČR se návrhem specifikace metadatového popisu webových dat snaží držet krok se zahraničními knihovnami, které řeší podobné problémy. Roli hlavního koordinátora a tvůrce standardů pravděpodobně převezme IIPC, zejména pracovní skupina pro dlouhodobé uchování (Preservation Working Group, PWG). Ačkoli prozatím schází standardizace v oblasti webových zdrojů, už nyní vznikají například doporučení, jak udělat webovou stránku "přátelskou" pro archivaci (archive-friendly).
Článek uvádí do problematiky dlouhodobé ochrany digitálních dokumentů z pohledu webových archivů. Naznačuje, jaké jsou problémové oblasti a na co je třeba se zaměřit při plánování dlouhodobého uchování webových zdrojů. Stav konkrétního řešení byl představen na příkladu WebArchivu Národní knihovny České republiky.
Poznámky
1 Top Level Domain = doména nejvyššího řádu
2 Sdružení CZ.NIC provozuje registr doménových jmen .cz a zabezpečuje provoz domény nejvyšší úrovně CZ [CZ.NIC, 2012]
3 http://www.webarchiv.cz/kriteria/
4 http://www.webarchiv.cz/tematicke_sbirky/
7 https://webarchive.jira.com/wiki/display/Heritrix/Heritrix
8 http://archive-access.sourceforge.net/projects/wayback/
9 Long-term preservation system
10 Zcela pomíjím skutečnost, že uživatel by měl vědět, že se při prohlížení archivní stránky nedívá na původní obrázek, ale na jednu z jeho novějších verzí.
11 Např. společnost Hanzo Archives, která komerčně archivuje webové stránky společností (mimo jiné Coca-Cola Company), uvádí na svých stránkách, že je schopna najít všechny odkazy i na vysoce dynamických stránkách založených na skriptovacích jazycích a umožňuje zachytit dynamické HTML, CSS, video, Flash atd. [Hanzo Archives, 2011]
12 http://archive.org/web/researcher/ArcFileFormat.php
14 http://webcurator.sourceforge.net/
15 https://sbforge.org/display/NAS/NetarchiveSuite
17 http://www.manuscriptorium.com
19 http://code.hanzoarchives.com/warc-tools/wiki/Home
Použitá literatura:
BROWN, Adam. 2006. Archiving websites: a practical guide for information management professionals. London: Facet, 2006. 238 s. ISBN 978-1-85624-553-7.
BURNER, Mike; KAHLE, Brewster. 1996. Arc File Format. In Internet Archive [online]. San Francisco: Internet Archive, 15th September 1996 [cit. 2012-08-26]. Dostupné z: http://archive.org/web/researcher/ArcFileFormat.php
CELBOVÁ, Ludmila. 2001. WebArchiv: projekt zaměřený na českou národní bibliografii elektronických zdrojů. ITlib : informačné technologie a knižnice [online]. 2001, roč. 5, č. 3 [cit. 2012-09-14]. ISSN 1336-0779. Dostupné z: http://www.cvtisr.sk/itlib/itlib013/webarchiv.htm
CELBOVÁ, Ludmila et al. 2008. Archivace webu. 1. vyd. Praha: Národní knihovna ČR, 2008. 45 s. ISBN 978-80-7050-562-5.
COUFAL, Libor. 2012. Jaká je velikost webu? In WebArchiv: blog [online]. Praha: WebArchiv, 21. února 2012 [cit. 2012-09-14]. Dostupné z: http://blog.webarchiv.cz/2012/02/jaka-je-velikost-webu.html
CUBR, Ladislav. 2003. Dlouhodobá ochrana digitálních dokumentů. In KTD: Česká terminologická databáze knihovnictví a informační vědy (TDKIV) [online]. Praha: Národní knihovna ČR, 2003- [cit. 2012-09-06]. Dostupné z: http://aleph.nkp.cz/F/?func=direct&doc_number=000014623&local_base=KTD
CZ.NIC. 2012. CZ.NIC [online]. Praha: CZ.NIC, 2012 [cit. 2012-08-26]. O Sdružení. Dostupné z: http://www.nic.cz/page/351/o-sdruzeni/
DAVIS, Maxine. 2009. Preserving access - making informed guesses about what works: report to the IIPC Preservation Working Group. In International Internet Preservation Consortium [online]. IIPC, 23rd November 2009 [cit. 2012-08-26]. Dostupné z: http://www.netpreserve.org/publications/preservingaccess.pdf
DAVIS, Robin C. 2011. Five tips for designing preservable websites. In Smithsonian Institution Archives [online]. Washington: Smithsonian Institution Archives, 2nd August 2011 [cit. 2012-08-26]. Dostupné z: http://siarchives.si.edu/blog/five-tips-designing-preservable-websites
DAY, Michael. 2003. Collecting and preserving the World Wide Web: a feasibility study for the JISC and Wellcome Trust. In UKOLN [online]. Bath: UKOLN, 2003 [cit. 2012-09-14]. Dostupné z: http://www.jisc.ac.uk/uploaded_documents/archiving_feasibility.pdf
DAY, Michael. 2006. The long-term preservation of web content. In UKOLN [online]. Bath: UKOLN, 2006 [cit. 2012-08-26]. Dostupné z: http://www.ukoln.ac.uk/preservation/publications/2006/web-archiving/md-final-draft.pdf
Hanzo Archives. 2011. Hanzo Archives: Leading social media and website archiving [online]. San Francisco: Hanzo Archives, last modif. Jan/21/2011 [cit. 2012-09-14]. Web archiving overview. Dostupné z: http://www.hanzoarchives.com/solutions/web_archiving_overview
Internet Archive. 2010. Internet Archive [online]. San Francisco: Internet Archive, 2010 [cit. 2012-09-14]. Petabox 4. Dostupné z: http://archive.org/web/petabox.php
ISO. 2009. Information and Documentation: the WARC file format/draft as of November 2008 [online]. Paris: BnF, last updated 2009-05 [cit. 2012-09-14]. Dostupné z: http://bibnum.bnf.fr/warc/
KUNDER, Maurice de. 2012. WorldWideWebSize.com [online]. Aktualizováno 10. 9. 2012 [cit. 2012-09-10]. Dostupné z: http://worldwidewebsize.com/
KUNZE, John. 2005. WARC: an archiving format for the web. In 5th International Web Archiving Workshop: IWAW05, 22.-23. September 2005 [online]. Vienna: IWAW, 2005 [cit. 2012-09-14]. Dostupné z: http://iwaw.europarchive.org/05/kunze.pdf
KVASNICA, Jaroslav. 2012. Podklady pro ukládání WARC souborů do LTP systému. Praha: Národní knihovna ČR, 4. 6. 2012. Nepublikovaný dokument.
LAZORCHAK, Butch. 2012. Designing preservable websites, Redux. In The Signal: digital preservation [online]. Washington: Library of Congress, 6th February 2012 [cit. 2012-09-14]. Dostupné z: http://blogs.loc.gov/digitalpreservation/2012/02/designing-preservable-websites-redux/
LONG, Andrew S. 2009. Long-term preservation of web archives: experimenting with emulation and migration methodologies . In International Internet Preservation Consortium [online]. IIPC, 10th December 2009 [cit. 2012-08-26]. Dostupné z: http://www.netpreserve.org/publications/NLA_2009_IIPC_Report.pdf
LONG, Andrew S.; PEARSON, David. 2009. I say emulate; He says migrate: Are emulation or migration feasible preservation strategies? In IIPC Open Day [online]. San Francisco: IIPC, 7th October 2009 [cit. 2012-09-14]. Dostupné z: http://www.nla.gov.au/openpublish/index.php/nlasp/article/view/1475/1803
MASANÈS, Julien. 2005. IIPC Web archiving metadata set. In 5th International Web Archiving Workshop: IWAW05, 22.-23. September 2005 [online]. Vienna: IWAW, 2005 [cit. 2012-09-14]. Dostupné z: http://iwaw.europarchive.org/05/masanes2.pdf
MASANÈS, Julien. 2006. Web archiving. New York: Springer, 2006. 234 s. ISBN 978-3-540-23338-1.
MOHR, Gordon. 2012. Tools for web archiving: the Java/Open source tools to crawl, access & search the Web. In National Library of Australia [online]. Canberra: NLA, 28th March 2012 [cit. 2012-08-26]. Dostupné z: http://www.nla.gov.au/podcasts/docs/NLA-ToolsForWebArchiving.pdf
OURY, Clément. 2009. WARC implementation guidelines: contribution from WARC usage task force. In International Internet Preservation Consortium [online]. IIPC, 27. 1. 2009 [cit. 2012-08-26]. Dostupné z: http://www.netpreserve.org/publications/WARC_Guidelines_v1.pdf
OURY, Clément; PEYRARD, Sébastien. 2011. From the World Wide Web to digital library stacks: preserving the French web archives. In iPres 2011: 8th International conference on preservation of digital objects, 1st-4th Nov, 2011, Singapore [online]. Singapore: iPres, 2011 [cit. 2012-09-14]. Dostupné z: http://ipres2011.sg/
PHILLIPS, Margaret E. 1999. The National library of Australia: ensuring long-term access to online publications. JEP: The Journal of electronic publishing [online]. 1999, vol. 4, issue 4 [cit. 2012-08-26]. Dostupné z: http://quod.lib.umich.edu/cgi/t/text/text-idx?c=jep;view=text;rgn=main;idno=3336451.0004.405
PROKOP, Martin. 2012. Nástroje pro migraci webového archivu. Brno, 2012. 71 s. Bakalářská práce (Bc.). Masarykova univerzita, Fakulta informatiky.
STRODL, Stephan. 2005. Selecting preservation strategies for web archives. In 5th International Web Archiving Workshop: IWAW05, 22.-23. September 2005 [online]. Vienna: IWAW, 2005 [cit. 2012-09-14]. Dostupné z: http://iwaw.europarchive.org/05/strodl.pdf
Website Optimization. 2011. WebSiteOptimization.com [online]. Ann Arbor: Website Optimization, 2011 [cit. 2012-09-14]. Average web page size septuples since 2003. Dostupné z: http://www.websiteoptimization.com/speed/tweak/average-web-page/
CITACE:
Kratochvílová, Zuzana. Dlouhodobá ochrana a zpřístupnění dat z webových archivů : WebArchiv Národní knihovny České republiky. Knihovna [online]. 2012, roč. 23, č. 2, s. 35-47 . Dostupný z WWW: <http://knihovna.nkp.cz/knihovna122/kratochv.htm>. ISSN 1801-3252.
![]()
| nahoru | |obsah| | archiv | | domů |
| index autorů | | index názvů | | index témat |