|obsah| |index autorů | | index názvů | | index témat | | archiv |
Knihovna
2013, ročník 24, číslo 1, s. 28-44
Mgr. Marie Balíková / Národní knihovna ČR, Ing. Miroslav Kunt / Národní archiv, Mgr. Jana Šubová / Cosmotron Bohemia, s. r. o., Ing. Nadežda Andrejčíková Ph.D. / Cosmotron Bohemia, s. r. o.
Resumé:
Příspěvek informuje o projektu Interoperabilita v paměťových institucích (INTERPI) DF11P01OVV023 Programu aplikovaného výzkumu a vývoje národní a kulturní identity (NAKI) financovaném Ministerstvem kultury ČR.
Fondy a sbírky paměťových institucí tvoří jádro národního kulturního, industriálního a přírodního dědictví. Cílem projektu INTERPI je tvorba společné ontologie a znalostního modelu odpovídajícího potřebám všech paměťových institucí a obohaceného o potřebné sémantické informace umožňující i strojové zpracování dat. Přináší také nové paradigma zpracování dat na základě objektového přístupu, které se zaměřuje na zpracování entit (tříd) a komplexních vztahů mezi nimi, a jehož cílem je zabezpečení sémantické interoperability.
Studie přináší teoretická východiska projektu a také informace o výsledcích a prostředcích pro jejich dosažení.
Klíčová slova: sémantická interoperabilita, paměťové instituce, objektový přístup, ontologie
Summary:
The article informs about the project called "Interoperability in memory institutions” (INTERPI) DF1P01OVV023 realized in the Programme of applied research and development of national and cultural identity (NAKI) funded by the Ministry of Culture of the Czech Republic. Collections of memory institutions form the heart of national cultural, industrial and natural heritage. The aim of the project INTERPI is to create an ontology and a conceptual model of knowledge which meets the requirements and needs of all memory institutions, enlarged by necessary semantic information which make machine processing of data possible. The project also brings a new paradigm of data processing based on object-oriented approach which is focused on processing of entities (classes) and on complex relations among them – the aim of this process is semantic interoperability. The study describes theoretic basis of the project and brings information about the results and the process of obtaining the data.
Keywords: semantic interoperability, memory institutions, object-oriented approach, ontology
Studie přináší informace o projektu "Interoperabilita v paměťových institucích (INTERPI)". Jedná se o společný (konsorciální) projekt Národní knihovny ČR, která je koordinátorem projektu, a Národního archivu, který je spoluřešitelem projektu; poskytovatelem projektu je MK ČR. Projekt je pětiletý: byl schválen v prosinci 2010, zahájen 1. 2. 2011; předpokládané datum ukončení projektu je 31. 12. 2015. První kapitola studie přibližuje cíl projektu INTERPI. Ve druhé kapitole je nastíněn současný stav zpřístupnění kulturního dědictví v jednotlivých institucích, jeho hodnocení z pohledu projektu INTERPI a jsou stanoveny požadavky na úpravu stávajících autorit. Základním tématem třetí kapitoly je datová struktura projektu a vymezení tříd entit používaných v projektu. Čtvrtá kapitola se věnuje nástrojům pro technickou realizaci projektu INTERPI. Předmětem páté kapitoly je problematika webového rozhraní. V poslední šesté kapitole nastíníme další směřování projektu INTERPI.
Cílem projektu INTERPI je připravit vědeckou a technologickou infrastrukturu pro podporu zpracování, sdílení a využívání kulturního obsahu ve formě metadatových informací o informačních objektech zpřístupňovaných v paměťových institucích na bázi interoperability především sémantické, za pomoci v současné době dostupných informačních a komunikačních technologií podporujících tvorbu sémantického a webu publikovaných konsorciem W3C (URL/URI, XML, XMLS, RDF, RDFS).
Informační objekty představují objekty reálného světa, např. osobnosti, instituce, akce, trojrozměrné předměty (lidské výtvory, objekty neživé přírody), události, umělecké a jiné výkony i jejich textové, obrazové, zvukové reprezentace (včetně digitálních), které jsou předmětem odborných činností v paměťových institucích a které mohou být jednoznačně identifikovány prostřednictvím jmenných a věcných autorit.
V rámci projektu je však nutné funkci autorit jako záznamů obsahujících především jednoznačný unifikovaný selekční prvek doplnit o odkazy na autoritní záznamy souvisejících informačních objektů a rozšířit jejich informační a dokumentační hodnotu. Budou tak splňovat nejenom požadavky na ně kladené z pohledu jednotlivých typů paměťových institucí, ale zároveň budou vytvářet mnohem širší základ pro sémantickou interoperabilitu kulturního obsahu všech paměťových institucí. Sémantická interoperabilita je podmínkou uživatelsky vlídného zpřístupnění národního kulturního dědictví.
Jedním z hlavních výsledků projektu bude nástroj pro uživatelsky vlídné a diferencované pořizování a zpřístupnění informací o těchto informačních objektech. Tento nástroj bude zároveň vytvářet základní předpoklady pro zpřístupnění a sdílení kulturního obsahu napříč paměťovými institucemi se zabezpečením sémantické interoperability na konceptuální úrovni.
Zpřístupnění kulturního dědictví – současná praxe v paměťových institucích
K paměťovým institucím se řadí knihovny, archivy, muzea, výzkumné ústavy, univerzity, jejichž cílem je ochrana a zpřístupňování informačních zdrojů kulturního dědictví (Marvanová 2003). Rozdíly ve zpřístupňování kulturního dědictví v jednotlivých paměťových institucích jsou podmíněny především rozdílností zpřístupňovaných informačních objektů:
Při zpřístupnění textových dokumentů lze vycházet z předem daných identifikačních údajů (autor, název, vydavatel atd.). Také zpřístupnění uvedených informačních zdrojů po obsahové stránce je mnohem jednodušší: je možné se soustředit pouze na standardizované přístupové selekční prvky definované v autoritních záznamech, které jsou součástí institucionálních, národních i mezinárodních souborů autorit. Tyto soubory se však vyznačují tím, že obsahují minimum informací, mnohdy se omezují pouze na selekční prvky. Na rozdíl od toho, při zpřístupnění informačních zdrojů v muzeích, galeriích a archivech nelze ve většině případů vycházet z předem daného názvu nebo jiných formalizovaných identifikátorů. Identifikační i obsahové údaje pro daný informační zdroj musí kurátor/archivář vytvořit sám a pomocí takto vytvořených údajů tento informační zdroj (archiválii, exponát nebo jejich kolekce) popsat a začlenit do archivní pomůcky či do sbírky. Takový popis v sobě nese značnou míru subjektivity a má sám navíc výrazně kontextuální rysy definované hierarchickými vztahy k podsbírce, sbírce (v muzeích a galeriích), k nadřazené skupině archiválií, k archivnímu fondu nebo archivní sbírce (v archivech). Jistého stupně standardizace je i zde dosaženo. V archivech jsou používány v rámci archivní pomůcky standardizované přístupové body – rejstříková hesla s odkazy. Jedna z nejdůležitějších kontextuálních informací – provenience – je vyjádřena hned v úvodu archivní pomůcky. Tento vztah archiválie k původci1 je (s výjimkou archivních sbírek) vlastně základem archivnictví.
V muzeích a galeriích jsou selekční údaje standardizovány pomocí odborných slovníků, kódovníků, číselníků, které se však používají pouze v daném systému, např. systém Demus; v některých systémech se slovníky, kódovníky, centrálně spravované číselníky nepoužívají vůbec, např. systém ProMuzeum (Tezaury… 2012).
Při hodnocení praxe týkající se zpřístupnění v jednotlivých typech paměťových institucí se zaměříme na:
Pravidla, standardy a postupy v knihovnách
V knihovnách se používají pravidla AACR2 (Angloamerická katalogizační pravidla, druhé vydání) a na ně navazující v současné době vyvíjená a postupně implementovaná pravidla RDA (Resource Description and Access), která však doposud plně nepokrývají dnešní potřeby, protože neřeší problematiku zápisu geografických termínů, objektů a pojmů. Kromě způsobu zápisu údajů se pravidla RDA orientují nejenom na zařazení selekčních prvků do jednotlivých skupin entit, na rozsah informací důležitých pro identifikaci a vymezení entity, ale i na oblast vzájemných vztahů, které jsou pro tvorbu znalostní báze podstatné (objektově orientovaný přístup). Vzhledem k tomu, že na oba standardy navazují standardy v současné době již používané i v dalších paměťových institucích (např. CCO – viz níže), jsou tyto standardy pro projekt INTERPI klíčové.
Struktura dat a explicitní vyjádření vztahů se řeší pomocí entitně-relačních (FRBR, FRAD, FRSAD) a objektově orientovaných (FRBRoo) konceptuálních modelů, které odpovídají principu objektového přístupu zvoleného v projektu INTERPI a svým významem zasahují i do systému zpřístupnění kulturních a informačních objektů ostatních paměťových institucí.
FRBR (Funkční požadavky na bibliografické záznamy) poskytují strukturovaný rámec uvádějící do souvislosti údaje zaznamenané v bibliografických záznamech z pohledu uživatelů a doporučují základní úroveň funkčnosti pro záznamy vytvořené národními bibliografickými agenturami.
FRAD (Funkční požadavky na autoritní data) modelují reálný svět fyzických osob a korporací, které byly definovány v modelu FRBR v tvůrčím nebo vlastnickém vztahu vůči entitám: dílo, vyjádření, provedení a jednotka. Jde o obecný model, který lze aplikovat na širší doménu autoritních dat, nejen na systémy autoritních záznamů budovaných v národních bibliografiích2.
FRSAD (Funkční požadavky na předmětová autoritní data) definují klíčové entity, které pokrývají předmětové (tematické) zaměření děl (definice podle FRBR). Definované entity reflektují pouze oblast předmětu díla (aboutness), tj. o čem dílo pojednává, nikoliv žánrové zařazení (isness), tj. že je dílo např. románem, sonatinou, životopisem nebo sochou či obrazem.
FRBRoo (Objektově orientovaný model FRBR) je formální ontologie, jejímž cílem je podchytit a reprezentovat základní sémantiku bibliografických informací a usnadnit integraci, zprostředkování, výměnu, sdílení a vícenásobné využití bibliografických, muzejních i archivních informací. Standard vznikl harmonizací modelu FRBR a CIDOC CRM s cílem podpořit sémantickou interoperabilitu uvedených informací. Z pohledu INTERPI se jedná o perspektivní objektově orientovaný model.
Kooperační systémy
Národní knihovnické autority (jmenné a věcné) se staly základem mnoha projektů na institucionální, národní i mezinárodní úrovni. Cílem všech těchto projektů je tvorba a následná aplikace kvalitních standardních selekčních prvků, které představují základní platformu pro tvorbu uživatelsky přívětivých systémů zpřístupnění různého typu aplikovaného v různých prostředích.
"Kooperativní tvorba a využívání souborů národních autorit”3, projekt primárně určený knihovnám, byl zpočátku koncipován pro tvorbu jmenných, tj. personálních a korporativních autorit spravovaných oddělením národních jmenných autorit (ONJA) NK ČR; posléze se rozrostl i o dva typy věcných autorit, tj. geografických a formálních, které jsou spravovány oddělením národních věcných autorit a věcného zpracování (ONVAZ) NK ČR.
Projekt "Národní autority v prostředí muzeí a galerií – interoperabilita s NK ČR” integruje potřeby muzeí a galerií a možnosti národních autorit (více informací níže).
VIAF – mezinárodní webový portál zpřístupňující autoritní záznamy osob, korporací a geografických termínů4 vytvářených národními katalogizačními agenturami; autoritní záznamy jsou obohacené o údaje ze souvisejících bibliografických záznamů např. o názvy, ISBN, jména nakladatelů, spoluautorů, ISNI5 atd.
Slabé a silné stránky zpřístupnění v knihovnách
K slabým stránkám zpřístupnění informací v knihovnických autoritních systémech patří především:
Za silné stránky považujeme:
Pravidla, standardy a postupy v muzeích a galeriích
Pravidla CCO (Cataloguing of Cultural Objects) představují komplexní standard pro katalogizaci a zpřístupnění informačních zdrojů, používaný v muzeích a galeriích a navazující na pravidla AACR2. Ve srovnání s pravidly používanými v knihovnictví, obsahují pravidla CCO také doporučení týkající se struktury databází a doporučení pro aplikaci popisných položek (polí) obsahujících nejenom řízené údaje, ale i polí umožňujících zápis různých doplňujících údajů formou volného textu. V tom jsou pro projekt INTERPI inspirativní.
Model CRM (CIDOC Conceptual Reference Model – Konceptuální referenční model CIDOC) byl vyvinut v r. 2004, schválen jako norma ISO 21127:2006. Je formální doménovou ontologií, která modeluje vztahy mezi pojmy na objektově orientovaném principu. Poskytuje definice a formální strukturu pro popis implicitních a explicitních konceptů a vazeb užívaných v dokumentaci kulturního dědictví. Datová struktura projektu INTERPI se v zásadě řídí principy tohoto konceptuálního modelu.
Kooperační systémy
Muzejní autority – výsledkem projektu "Národní autority v prostředí muzeí a galerií – interoperabilita s NK ČR" (2007–2011)6 jsou tzv. "Muzejní autority", které představují nadstavbu národních knihovnických autorit plně respektující rozsah knihovnického autoritního záznamu. Navíc však prezentují informace potřebné pro adekvátní vyjádření vztahů a vazeb na principu konceptuálního modelu CIDOC CRM, které jsou nezbytné pro adekvátní zpřístupnění informačních objektů uchovávaných v galeriích a muzeích.
Registr sbírek výtvarného umění – katalog sbírek členských galerií Rady galerií České republiky – je praktickou ukázkou úspěšné aplikace Muzejních autorit na zpřístupnění kulturního dědictví obsaženého v galerijních sbírkách členských galerií Rady galerií ČR za technické podpory a spolupráce s CITeM7.
Slabé a silné stánky zpřístupnění v muzeích a galeriích
K slabým stránkám zpřístupnění informací v muzeích a galeriích patří především:
Za silné stránky považujeme:
Pravidla, standardy a postupy v archivech
ISAD(G) – Všeobecný mezinárodní standard pro archivní popis – definuje víceúrovňový hierarchický popis archiválií (skupin archiválií – fondů, sérií apod.) a je zaměřen na tvorbu archivní pomůcky jako prostředku pro vyhledávání archiválií; zahrnuje také v minimální míře popis původců (osob, korporací, rodů).8
ISAAR(CPF) – Mezinárodní standard pro archivní autoritní záznamy korporací, osob a rodů – definuje strukturu a obsah autoritních záznamů zejména v případě původců archiválií – fyzických osob, korporací a rodů. Definuje vazby mezi autoritními záznamy vzájemně i mezi záznamy a archiváliemi a naznačuje možnosti použití archivních autoritních systémů.9
Oba zmíněné standardy jsou z pohledu projektu INTERPI významné, zvláště standard ISAAR(CPF), a to tím, že klade důraz na explicitně vyjádřené vazby a vztahy mezi entitami.
Kooperační systémy v archivech
Kvalitně koncipované kooperační systémy na bázi národních autorit v archivnictví neexistují, a to ani ve světě. V případě archivů se kooperace omezuje zpravidla na jeden archiv, pokud není celý systém budován jako národní10.
Slabé a silné stránky zpřístupnění informací v archivech
K slabým stránkám řadíme:
Za silné stránky považujeme:
Zpřístupnění kulturního dědictví – výsledky analýzy
V souvislosti s masivní digitalizací a s rostoucí potřebou zpřístupnění veškerého kulturního dědictví v prostředí sémantického webu dochází ke změně v pojetí a aplikaci knihovnických autoritních souborů: jejich primární funkcí není pouze standardizace selekčních prvků/přístupových bodů, ale mají být obohaceny o dostatečné množství informací k jednoznačné identifikaci entit i z pohledu ostatních paměťových institucí, a především mají obsahovat dostatečné množství informací pro adekvátní reprezentaci vztahů a vazeb mezi jednotlivými entitami. Navíc, standardizované selekční prvky obsažené v autoritních záznamech mají být dostupné, a především strojově zpracovatelné i pro vyhledávače (softwarové agenty). Vzniká tak oprávněná potřeba strukturovaného, strojem zpracovatelného, algoritmizovaného zápisu jednotlivých částí selekčních prvků (přístupových bodů).
Specifikace požadavků týkajících se aplikace stávajících autorit
Na základě uvedené analýzy byly stanoveny následující požadavky na záznamy autorit:
1. Mají-li být knihovnické autority používány ve všech paměťových institucích, musejí být uváděny následující údaje:
2. V současných knihovnických autoritách se jako problematické jeví:
Úprava a rozšíření údajů ve stávajících záznamech Národních autorit
V souvislosti s formulací požadavků na Národní autority se realizují dvě nejdůležitější změny, které usnadní další využívání věcných autorit pro kooperaci.
V záznamu geografické autority byl doplněn kód cz_retro (stabilní číselný kód v číselné řadě 1 až 99999), který je součástí databáze CZ_RETRO zahrnující všechna města, městečka a vesnice na území Čech, Moravy a Slezska, a rovněž jejich čtvrti a díly.14 Uvádění detailnějšího geografického třídění v záznamech geografických autorit je nezbytné pro kooperaci s ostatními paměťovými institucemi.
Výrazně se mění i struktura zápisu kvalifikátorů u geografických autorit a tematických autorit typu bitvy, války.15
Objektový přístup
V současné době je objektový přístup považován za jeden z hlavních programovacích stylů a jeden z hlavních přístupů k tvorbě informačních systémů. Vychází ze širšího filozofického kontextu a využívá metody abstraktního myšlení, při kterém se konkrétní prvky nahrazují abstraktními pojmy, které se následně přizpůsobují požadavkům a konkrétnímu účelu a aplikují se na množství konkrétních situací (Drbal 2005). Abstraktní pojmy, se kterými se v objektovém přístupu pracuje, jsou označovány jako objekty: objekt je tedy reálná entita, instance třídy (Madan 2004, s. 228).
Z hlediska modelování informačních systémů je za objektový přístup považován ten, který je "založen na modelování reálného světa pomocí objektů, tříd, dědičnosti apod." (Chidamer 2005). Zjednodušeně je možné za objekty v modelování informačních systémů považovat nejen objekty reálného světa (např. osoby, věci), ale i vlastnosti a události – "všeobecně všechno, co můžeme nazvat podstatným jménem" (Pecinovský 2010, s. 42). Objekty s podobnými vlastnostmi je možné rozdělit do skupin, které se označují jako třídy. Objekt, který patří do určité třídy, se označuje jako instance třídy. Odlišení jednoho objektu od druhého se označuje jako identita (Paetau 2005, s. 27). Mezi objekty vznikají statické a dynamické vztahy. Statické vztahy znamenají dlouhodobé spojení objektů, dynamické vztahy představují komunikaci mezi objekty (Pecinovský 2010, s. 27). Vztahy je možné typologicky rozdělit na asociativní vztah, vztah agregace a vztah dědičnosti (Pecinovský 2010, s. 37–38). Asociativní vztah znamená, že dva objekty spolu souvisejí a v tom případě může jít buď o jednosměrný, nebo obousměrný vztah, kdy jeden objekt odkazuje na druhý a opačně. Vztahem agregace se rozumí stav, kdy jeden objekt pozůstává z více jiných objektů. Vztah dědičnosti zahrnuje vztah zobecnění a specifikace. Kromě vyjmenovaných vztahů mezi objekty je možné vymezit i vztahy mezi objektem a třídou.
Jak již bylo zmíněno, objekty se začleňují do tříd a tyto třídy určují typ objektů. Třída určuje vlastnosti objektů a činnosti, které je možné s objekty vykonávat. Možné je rozlišovat abstraktní, konkrétní nebo smíšenou třídu (Pecinovský 2010, s. 33). Abstraktní třída neobsahuje žádné objekty, může však být zapojena a použita pro podchycení dědičnosti. Prvotním účelem konkrétní třídy je seskupení objektů, může též podporovat dědičnost.
Hierarchie jako další vlastnost objektového přístupu umožňuje nadřadit a podřadit jednu třídu jiné. S třídami se spojuje také dědičnost, která je též základní charakteristikou objektového přístupu. Dědičnost podporuje princip znovupoužití (reuse). Teoreticky je možné dědit všechny vlastnosti, přičemž dědičnost může být víceúrovňová.
Objektový přístup se v projektu INTERPI odráží především v návrhu datové struktury a v přístupu k vymezení tříd entit. V konkrétní realizaci informačních systémů se objektový přístup promítá také do využívání objektově orientovaných (nebo objektových) databází, které na rozdíl od entitně-relačních struktur umožňují vícerozměrné ukládání dat a podporu vlastností objektového přístupu.
Terminologický základ projektu16
Již při formulování projektového záměru bylo zřejmé, že bude nutné podrobit použí-vanou terminologii důkladné analýze, protože význam jednotlivých pojmů a termínů vnímají jednotlivé odborné komunity participující na projektu různě. Z důvodů úspěšné kooperace bude tedy nutné najít vhodný terminologický průnik. Po dlouhých diskusích bylo dohodnuto použít "neutrální" obecný pojem informační objekt, který může být definován jako "jakýkoliv fragment skutečnosti nacházející se ve vztahu se subjektem, pro nějž je zdrojem informací" (Čabrunová 1998, s. 144). Informační objekt je tedy ve vztahu k paměťovým institucím cokoli, co je předmětem jejich zájmu a odborných činností a co má pro ně význam jako zdroj informací.
Za informační objekt se bude považovat v projektu osoba (ve smyslu fyzické osoby, tj. reálná nebo fiktivní), korporace (ve smyslu instituce, dočasné korporace, sdružení apod.), geografická entita, pojem, předmět, dílo, výtvor, událost. Obecně se všechny tyto kategorie označují jako entity. Výklad pojmu entita se neshoduje s pojmem autorita, tak jak tomu často bývá v knihovnické praxi, nýbrž výklad pojmu entita se pro projekt používá ve všeobecném filozofickém významu a není také spojován s entitně-relačním modelem z informatiky. Pojem třída se používá pro označení skupiny entit se stejnými vlastnostmi, tj. pro osoby jako skupinu entit (jde o třídu osob), pro korporace (tj. jde o třídu korporací), nebo pro geografické entity (tj. jde o třídu geografických entit). Pojem třída se používá především tehdy, kdy je nutné zdůraznit rozdílnost jednotlivých entit. Pojem autorita se v projektu pro označení informačních objektů nebo souvisejících informací nepoužívá17.
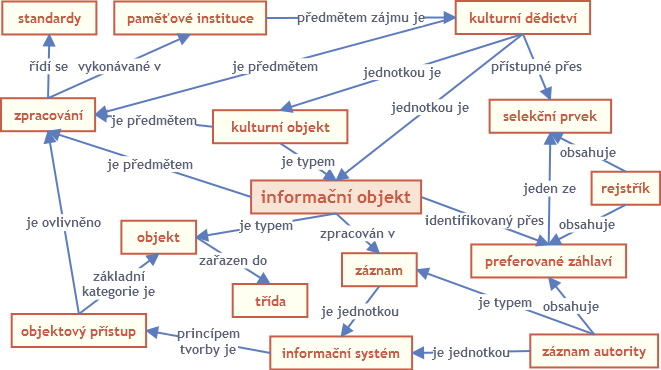
Komplexnost pojmové oblasti související s informačním objektem je zčásti znázorněná na pojmové mapě (obr. 1). K pojmům zobrazeným na pojmové mapě můžeme také přiřadit skupiny pojmů související s oblastí záznamů autorit, informačních systémů a objektovým přístupem.
Specifikace požadavků na datovou strukturu
Před zahájením tvorby datové struktury aplikované v projektu INTERPI bylo nutné definovat jednotlivé typy entit a požadavky na oblasti údajů, které mají být v záznamech těchto entit obsaženy. Tyto požadavky musejí respektovat potřeby všech typů paměťových institucí, protože úspěšná realizace projektu je podmíněna dohodou o společných rysech entit, o detailnosti a způsobu jejich zpracování a o aplikaci odpovídajících standardů. Tato dohoda a shoda paměťových institucí na způsobu zpřístupnění informačních objektů je jedním z vynikajících výsledků této fáze projektu INTERPI.
Obr. 1 Pojmová mapa informačního objektu (archiv autora)
Pro specifikaci požadavků na datovou strukturu byly stanoveny některé základní principy:
V projektu INTERPI se používají tyto entity: osoba/bytost, rod/rodina, korporace, geografický objekt, událost, dílo/výtvor, pojem (viz níže).
Požadavky u jednotlivých typů entit byly rozděleny do několika oblastí:
Související informace lze vyjádřit pomocí souvisejících entit propojených prostým vztahem asociace (viz též), nebo diferencovaně pomocí komplexních vazeb a vztahů, tedy prostřednictvím jednotlivých událostí významných pro danou entitu, na nichž se podílejí všichni aktéři.
Za významné události, které mají být vyjádřeny pomocí komplexní vazby, tj. formou události, se u entity považují: narození/vznik, úmrtí/zánik, studium, profesní kariéra/zaměstnání, členství v různých organizacích, významné aktivity (proslavení), rodinné a partnerské vztahy, vztahy předchůdce/následovník.
Byla doporučena obecná struktura události, která má obsahovat tyto prvky: datace, místo, osoba, instituce (korporace), poznámka, zdroj.
Nedílnou součástí požadavků na záznam INTERPI je i životopis/historie a zaměření, činnost (vyjádřené formou volného textu), související symboly (jako logo, znak, erb apod.), typ a status, uvedení použitých pramenů a zdrojů a možnost zaznamenat další údaje formou veřejné i neveřejné poznámky.
Datová struktura
Návrh datové struktury představuje jedinečné a komplexní řešení uspořádání dat pro zpracování personálních entit, korporací a geografických entit. Jedinečnost a přínos návrhu spočívá v aplikaci všeobecných principů (viz níže) spolu s integrací požadavků odsouhlasených všemi typy paměťových institucí. Datová struktura současně respektuje mezinárodní standardy a je kompatibilní s modelem CIDOC CRM.
Pro návrh datové struktury jsou formulovány následující základní principy, z nichž především znovupoužitelnost, dědičnost, polymorfizmus a zapouzdření vycházejí z objektového principu:
Popis jednotlivých prvků datové struktury se skládá z následujících částí:
Pro smysluplný popis je důležité dodržet minimální strukturu entity, proto jsou prvky, které se v záznamu entity musejí vyskytovat, označeny jako povinné.
Vlastnosti, vycházející z principu CIDOC CRM, jsou navrženy jako nepovinné, protože cílem je akceptovat i alternativní názory a neúplný popis, v zájmu srozumitelnosti popisu se však některé vlastnosti považují za nevyhnutelné a doporučené.
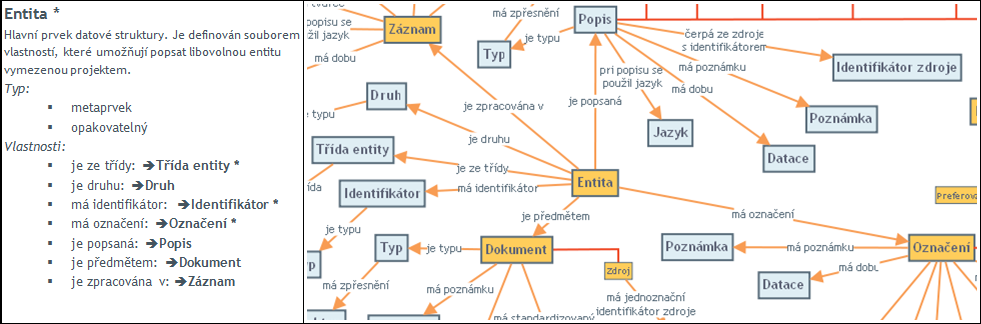
Obr. 2 Příklad popisu prvku Entita v datové struktuře a jeho grafická reprezentace (archiv autora)
Vymezení tříd entit
Na základě terminologické analýzy byly specifikovány společné třídy entit – tedy skupiny entit se stejnými vlastnostmi. Pro jejich vymezení bylo tedy nezbytné sumarizovat vlastnosti, které mají jednotlivé entity, a vzájemné sémantické vztahy vyskytující se v metadatech při popisu informačních objektů i souborů autorit. Výsledkem je sedm tříd entit: osoba/bytost, rod/rodina, korporace, geografický objekt, událost, dílo/výtvor, pojem.
Každá třída je rozdělena do podtříd. Členění do podtříd vychází ze společných znaků, resp. ze společné metodiky pro zpracování entit v rámci podtřídy.
Označení třídy a podtřídy entity tvoří základ pro zpracování entity; předpokládá se, že pro zpracování každé třídy entit bude vytvořena samostatná metodika a samostatné softwarové rozhraní, nebo jeho samostatná část (např. pracovní list, formulář). Taktéž mohou být vyčleněna metodická pravidla pro každou podtřídu entity.
Pro bližší zařazení entity do nějaké skupiny entit se používá při zpracování samostatný datový prvek, proto bylo možné zachovat pouze dvouúrovňovou kategorizaci tříd a podtříd.
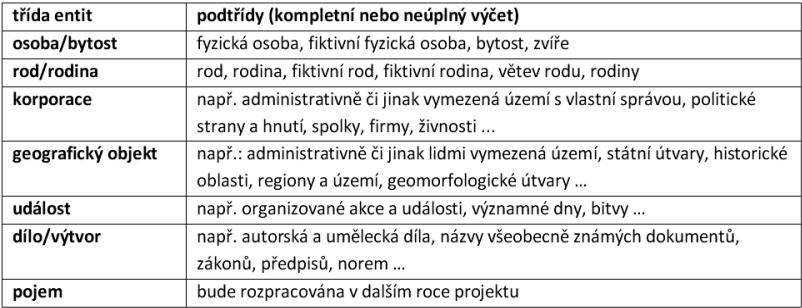
Obr. 3 Přehled tříd a podtříd entit v projektu INTERPI (archiv autora)
Informační technologie – nástroje pro technickou realizaci výsledků projektu INTERPI
Interoperabilita
Interoperabilita je klíčové slovo pro projekt INTERPI, protože k ní směřují všechny očekávané výsledky projektu. Interoperabilita je definována jako vlastnost dvou a více systémů nebo jejich komponentů spočívající ve schopnosti vyměňovat si informace a dokázat s těmito informacemi pracovat (Institute of Electrical and Electronics Engineers 1990, s. 114). Interoperabilita ovlivňuje efektivitu sdílení a vícenásobného využívání informačních zdrojů. Sémantická interoperabilita má umožnit propojení obsahově souvisejících dat, která jsou původně zpracovávána odděleně ve formátech a podle pravidel jednotlivých paměťových institucí. Jedním z nástrojů pro dosažení sémantické interoperability jsou ontologie (vytvořené obvykle pro jednu aplikační oblast, tj. doménu). Ontologie se využívají a) jako pomoc při komunikaci mezi lidmi, b) pro dosažení interoperability mezi systémy, c) pro podporu designu a kvality systému (Bittner 2013, s. 4).
Z pohledu projektu INTERPI, který si klade za cíl vytvořit prostředí pro budování ontologie pro paměťové instituce, jsou ontologie důležité jako nástroj při zpracování objektů kulturního dědictví (případ použití ad a), dále jako nástroj pro komunikaci mezi různými systémy (především vyhledávání) bez ohledu na formát a pravidla (případ b), a konečně i pro zpřístupnění kulturního dědictví prostředky sémantického webu např. v rámci jednotného portálu (případ c).
Sémantická interoperabilita úzce souvisí s problematikou sémantického webu, protože ontologie (slovníky) jako základní nástroj sémantické interoperability představují spolu s propojenými daty, dotazováním, dedukcí a aplikacemi do hloubky18 základní prvek pro tvorbu sémantického webu (W3C 2013). V současné době sémantický web se všemi svými nástroji považujeme za primární médium pro aplikaci a publikaci výsledků jakéhokoliv projektu, proto je důležitý i pro projekt INTERPI. Prostřednictvím technologií je možné vytvořená data reprezentovat, zveřejňovat a sdílet. V této souvislosti je potřebné uvažovat o vhodných modelech pro uložení a přístup k datům (dotazovací jazyky).
Technologie sémantického webu
Technologie sémantického webu jsou nástroje, které, mimo jiné, umožňují vytvořit formáty určené k prezentaci dat uložených v existujících tezaurech a slovnících (např. formát SKOS). Jsou tedy nástroji, kterými lze dosáhnout strojové srozumitelnosti obsahu publikovaného na webu a současně propojit vzájemně související informace (tj. dosáhnout principů linked data – propojených dat).
Tyto technologie je možné rozdělit do několika vrstev podle známého schématu (Berners-Lee 2013) (obr. 4). Z jednotlivých technologií charakterizujeme ty, které jsou klíčové pro projekt INTERPI.
URI
URI (Uniform Resource Identifier – jednotný identifikátor zdroje) je nyní používán nejen pro identifikaci dokumentů a digitálního obsahu, ale také pro identifikaci konkrétních objektů a abstraktních pojmů (lidí, míst, věcí) a pro identifikaci konkrétních významových vztahů mezi nimi.
Obr. 4 Technologie sémantického webu (BERNERS-LEE, TIM. SEMANTIC WEB – XML2000)
RDF a RDF Schéma
RDF (Resource Description Framework) představuje specifikaci formátu webového jazyka, vytvořeného konsorciem W3C, určeného pro reprezentaci informací pomocí abstraktního modelu metadat. RDF je jazyk, pomocí něhož je možné publikovat informace o různých zdrojích v prostředí World Wide Web. RDF poskytuje způsob zápisu jednoduchých tvrzení o zdrojích pomocí pojmenovaných vlastností a jejich hodnot. Používá tzv. trojici (triplet): subjekt – predikát – objekt (zdroj – vlastnost – hodnota). V praxi existuje celkem přirozený požadavek mít k dispozici pojmový aparát (terminologii), zahrnující slova, termíny a slovní spojení, které se v dané oblasti činnosti vyskytují a používají. Pro tento účel vzniklo rozšíření RDF s názvem RDF Vocabulary Description Language, nebo jinak, RDF Schéma (RDFS).
OWL
OWL (Web Ontology Language) je tak jako RDF nebo XML výsledkem práce konsorcia W3C. Jazyk OWL je značkovací jazyk navržený pro tvorbu ontologií. Rozšiřuje slovník RDFS o další elementy související s třídami a jejich vlastnostmi. Existují tři konkrétní implementace jazyka OWL, a to OWL Lite, OWL DL, OWL Full, přičemž platí, že ontologie definovaná v OWL Lite je platnou ontologií i pro jazyk OWL DL a ontologie definovaná v OWL DL je platná také pro jazyk OWL Full.
SPARQL
Pro vyhledávání konkrétních údajů notovaných prostřednictvím RDF jmenného prostoru jsou nezbytné algoritmy, které procházením obsahu a pomocí porovnávání řetězců naleznou námi hledané anotace. Aby byl postup hledání v prostoru sémantického webu unifikován, konsorcium W3C nabízí definici a doporučení pro funkcionalitu dotazovacího jazyka SPARQL (Simple Protocol and RDF Query Language).
Linked data – princip propojených dat
Pro projekt INTERPI je důležitý i princip propojených dat představující soubor metod publikování a vzájemného propojení strukturovaných dat v prostředí webu s cílem zvýšit efektivitu jejich využitelnosti. Tento způsob publikování je založen na standardních webových technologiích, jako je protokol HTTP pro zabezpečení přístupu, HTML formát pro zpřístupnění obsahu a unikátní identifikátor URI. Na rozdíl od klasických webových stránek, které umožňují publikovat a propojovat dokumenty určené pro čtení lidmi, koncept propojených dat rozšiřuje možnosti sdílení informací tím, že stroje jsou schopny tyto informace číst, rozumí jim a mohou je i zpracovávat.
Tim Berners-Lee (2006) definoval 4 základní principy pro propojená data:
Koncept propojených dat (linked data) se příliš neodlišuje od konceptu propojených otevřených dat (linked open data). Hlavní rozdíl je v tom, že propojená otevřená data jsou publikována pod tzv. otevřenou licencí – to znamená, že jsou volně použitelná při dodržení daných podmínek. Je potřeba si ovšem uvědomit, že ne každá propojená data jsou zároveň otevřená, a obráceně, že ne každá otevřená data jsou současně propojená.
Princip propojených dat koresponduje v projektu INTERPI se záměrem aplikovat objektový přístup a přejít od lineárního zpracování k objektovému, tedy k propojování souvisejících objektů. Propojená data spolu s příslušnými technologiemi poskytují pro INTEPRI rámec pro konkrétní webové realizace.
Data o informačních objektech zpracovávaných v rámci projektu budou přístupná nejen ve formátech, které vyžaduje kooperace s paměťovými institucemi (MARC formáty, ISO 2709, EAC), ale především v RDF reprezentaci. Předpokládá se využití navržené datové struktury, nebo její transformace do příbuzného standardu. O konkrétním řešení v oblasti technologií není v současnosti rozhodnuto, je totiž součástí poslední fáze projektu. Hlavním důvodem je, že technologie sémantického webu jsou zatím relativně nové a je potřeba důkladně otestovat možnost jejich reálného nasazení. Svědčí o tom různé projekty, které je aplikují, jsou však ve fázi experimentálního testování.
Webové rozhraní pro zpracování entit
V roce 2012 bylo do řešení projektu "předsunuto" vytvoření prototypu webového rozhraní pro zpracování entit. Posuzování datové struktury a požadavků na rozsah záznamů o entitách se ukázalo jako příliš složité bez možnosti praktického vytvoření záznamu. Pro webové rozhraní bylo stanoveno několik funkčních požadavků, které se promítly do funkčního konceptu a také do samotného rozhraní. Webové rozhraní je vytvořeno pomocí technologie ExtJS19 a umožňuje práci se záznamy pro jednotlivé entity. Jde především o grafické rozhraní, jehož funkcí je existující záznamy vyhledávat, upravovat a nové záznamy vytvářet. Pro každou třídu entit je k dispozici samostatný formulář, kde jsou jednotlivé prvky označeny vhodným popiskem a doplněny dalšími nástroji, jako je výběr z hodnot z číselníku, vyhledávání a vložení související entity apod. Vyplňování formuláře tak nevyžaduje znalost datové struktury, která je na pozadí aplikace. Pro zpracování je třeba znát pouze metodiku pro vyplňování jednotlivých údajů. Metodika je dalším připravovaným výstupem projektu. V případě, že se pravidla pro jednotlivé typy paměťových institucí odlišují, umožňuje rozhraní vytvořit údaje podle specifických pravidel.
Webové rozhraní respektuje životní cyklus záznamu (obr. 5) a dvojúrovňové zpracování (zpracovatel – supervizor).
Obr. 5 Životní cyklus záznamu (archiv autora)
Řešení webového rozhraní vyvolalo také diskusi o některých otázkách, které bude řešit připravovaný poloprovoz infrastruktury, např. zmíněný vztah zpracovaných dat k specifickým pravidlům, vztah vytvořených záznamů k existujícím autoritním souborům, určení efektivní hloubky zpracování faktografických informací o informačním objektu, kompetence a požadavky na znalosti supervizorů.
Závěr – další směřování projektu
Předpokládaným výsledkem projektu INTERPI bude funkční poloprovoz celé infrastruktury, základ znalostního modelu naplněný daty a ověření vzájemné spolupráce všech typů paměťových institucí v této oblasti. Cílem je, aby poloprovoz řešil všechny aspekty kooperace a zabezpečil kontinuitu budování znalostního modelu kulturního dědictví. Tento znalostní model bude následně využíván při zpracování a zpřístupnění objektů kulturního dědictví ve všech typech paměťových institucí, bude využit pro strojové odhalování skrytých znalostí a bude do značné míry schopen automatizovat zpracování kulturních objektů, ať už primárně digitálních či digitalizovaných. V paměťových institucích tak budou vznikat data pro sémantický web.
Diskuse
Objektový přístup k zpracování a další směřování projektu přináší několik otázek, které budou námětem dalších odborných diskusí zástupců paměťových institucí participujících na projektu:
1. Jaká je efektivní hranice mezi faktografickou komplexností zpracovávaných dat a kapacitními možnostmi odborných pracovníků?
2. Je možný reálný dlouhodobý provoz informačního systému založeného na principech propojených dat s využitím technologií sémantického webu (včetně dotazování), který je zároveň uživatelsky přívětivý, nebo jde pouze o teoretické teze a experimentální provoz na vzorcích dat?
3. Jsou lokální informační systémy využívané v jednotlivých typech paměťových institucí schopné využít potenciál připravované infrastruktury (např. výměna dat prostřednictvím webových služeb, identifikace objektů pomocí URI), nebo bude nutné hledat kompromisní řešení na úkor kvality poskytovaných služeb?
Poznámky
1 "Každý, z jehož činnosti dokument vznikl; za dokument vzniklý z činnosti původce se považuje rovněž dokument, který byl původci doručen nebo jinak předán." § 2 písm. d) zákona č. 499/2004 Sb., o archivnictví a spisové službě a změně některých zákonů (úplné znění vyhlášeno zákonem č. 329/2012 Sb.).
2 Volně podle podkladů B. Drobíkové pro Zprávu o výsledcích řešení projektu v roce 2011. Více na: http://autority.nkp.cz/interpi/zpravy-o-reseni-vyzkumneho-zameru-interpi/zprava-o-vysledcich-reseni-projektu-interpi-v-roce-2011.
3 Projekt programu Veřejné informační služby knihoven (VISK), podprogramu VISK9 – Rozvoj funkcí CASLIN – souborného katalogu ČR a koordinace kooperativní tvorby a využívání souborů národních autorit.
4 Na zpřístupnění geografických autorit se intenzivně pracuje. Více na: http://viaf.org/.
5 Mezinárodní standardní identifikátor jména.
6 Řešený v rámci výzkumného programu MK ČR "Zpřístupnění a ochrana kulturních, uměleckých a vědeckých zdrojů", podprogramu "Integrované interaktivní zpřístupnění kulturního dědictví". Více na: http://www.citem.cz/projekty/narodni-autority/.
7 Metodické centrum pro informační technologie v muzejnictví. Více na: http://www.citem.cz/.
8 Dostupné na: http://www.ica.org/10207/standards/isadg-general-international-standard-archival-description-second-edition.html..
9 Dostupné na: http://www.ica.org/10203/standards/isaar-cpf-international-standard-archival-authority-record-for-corporate-bodies-persons-and-families-2nd-edition.html..
10 Takovým příkladem je RHiNET arhivski informacijski sustav (Chorvatsko). Více na:
11 Výsledek projektu "Možnosti a formy zpřístupnění archivních fondů nebo jejich částí veřejnosti v elektronické podobě" realizovaného v letech 2007–2009 a financovaného z prostředků výzkumu a vývoje Ministerstva vnitra ČR.
12 Dostupné na: http://www.mvcr.cz/clanek/metodiky.aspx..
13 Zákon č. 499/2004 Sb. a vyhláška č. 645/2004 Sb. ve znění novel z roku 2012.
14 Více na: http://sovamm.wz.cz/o_kodech.htm..
15 Více na: http://autority.nkp.cz/vecne-autority/vecne-autority-upravy-2013/.
16 Z důvodu omezení místa je informace o terminologické analýze podstatně zkrácena a omezena pouze na základní termíny.
17 Vyskytuje se pouze v případech, kdy hovoříme o úpravě stávajících autoritních záznamů, např. rozšíření informací v nich obsažených, pro potřeby projektu INTERPI.
18 Aplikace do hloubky jsou aplikace podporující spolupráci, vědu a výzkum prostřednictvím technologií sémantického webu, za pomocí metod pro podporu rozhodování, prezentaci případových studií apod.
19 ExtJS představuje množinu nástrojů využívajících programovací jazyk JavaScript pro tvorbu interaktivních webových aplikací.
Seznam bibliografických odkazů
BERNERS-LEE, Tim, 2006. Linked Data [online]. 2006-07-27, akt. 2009/06/18 [cit. 2013-03-14]. Dostupné z: http://www.w3.org/DesignIssues/LinkedData.html./P>
BERNERS-LEE, Tim, 2013. Semantic Web – XML2000 [online]. [cit. 2013-03-14]. Architecture. Dostupné z: http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide10-0.html.
BITTNER, Thomas, 2013, Maureen DONNELLY, and Stephan WINTER. Ontology and semantic interoperability [online]. [cit. 2013-03-14]. 24 s. Dostupné z: http://www.acsu.buffalo.edu/~md63/BittnerGeosemOnt.pdf.
ČABRUNOVÁ, A. Informačný proces. In: KATUŠČÁK, Dušan, Marta MATTHAEIDESOVÁ a Marta NOVÁKOVÁ. Informačná výchova: terminologický a výkladový slovník: odbor knižničná a informačná veda. Bratislava: Slovenské pedagogické nakladateľstvo, 1998. ISBN 80-08-02818-1, s. 143–149.
DRBAL, Pavel, 2005. Objektové myšlení [online]. Akt. 22. června 2005 [cit. 2013-03-14]. Dostupné z: http://objekty.vse.cz/Objekty/ObjektoveMysleni.
CHIDAMER, S. and C. KEMERER. A metrics suite for object-oriented design. IEEE Transactions on software engineering. 1994, 20(6). Zdroj: PAETAU, Patrik. On the benefits and problems of the object-oriented paradigm: including a finnish study [online]. Helsingfors, 2005 [cit. 2013-03-14], s. 10. Dostupné z: https://helda.helsinki.fi/bitstream/handle/10227/123/151-951-555-894-8.pdf.
Institute of Electrical and Electronics Engineers. IEEE Standard computer dictionary: a compilation of IEEE Standard computer glossaries. New York: IEEE, 1990. 217 s. ISBN 1-55937-079-3.
MADAN, Alok. Object-oriented paradigm in programming for computer-aided analysis of structures. Journal of computing in civil engineering, July 2004, 18(3), 226–236.
MARVANOVÁ, Eva, 2003. Paměťová instituce. In: KTD: Česká terminologická databáze knihovnictví a informační vědy (TDKIV) [online databáze]. Praha: Národní knihovna České republiky, 2003- [cit. 2013-04-14]. Dostupné z: http://aleph.nkp.cz/cze/ktd.
PAETAU, Patrik. On the benefits and problems of the object.oriented paradigm including a finnish study [online]. Helsingfors, 2005 [cit. 3012-03-14]. ISBN 951-555-894-8. 294 s. Dostupné z: https://helda.helsinki.fi/bitstream/handle/10227/123/151-951-555-894-8.pdf.
PECINOVSKÝ, Rudolf. OOP: naučte se myslet a programovat objektově. Vyd. 1. Brno: Computer Press, 2010. 576 s. ISBN 978-80-251-2126-9.
Tezaury a slovníky v systémech správy sbírek v muzeích a galeriích v ČR [online], 2012. Akt. 3. 1. 2012 [cit. 2013-03-16]. Dostupné z: http://www.citem.cz/wp-content/plugins/downloads-manager/upload/13-TezaurySlovnikyCeske.pdf.
W3C, 2013. Semantic Web [online]. [cit. 2013-03-14]. Dostupné z: http://www.w3.org/standards/semanticweb/.
CITACE:
Balíková, Marie; Kunt, Miroslav; Šubová, Jana; Andrejčíková, Nadežda. INTERPI: nástroj pro zpřístupnění národního kulturního dědictví. Knihovna [online]. 2013, roč. 24, č. 1, s. 28-44. Dostupný z WWW: <http://knihovna.nkp.cz/knihovna131/13128.htm>. ISSN 1801-3252.
![]()
| nahoru | |obsah| | archiv | | domů |
| index autorů | | index názvů | | index témat |