| |index autorů | | index názvů | | index témat | | archiv |
Knihovna
2009, ročník 20, číslo 1, s. 58-87
Jindřiška Pospíšilová, Karolína Košťálová, Hana Nemeškalová
Národní knihovna ČR – oddělení referenčních a meziknihovních služeb
e-mail: jindriska.pospisilova@nkp.cz
Změny, které proběhly v knihovnách v posledních dvaceti letech, zásadním způsobem ovlivnily jejich vnímání jako informačních institucí. S nástupem a rozvojem užívání ICT a vznikem "soutěživého prostředí" s jinými informačními subjekty především komerčního zaměření se knihovny snaží uhájit své místo na informačním trhu. V 90. letech začaly vystavovat své OPAC na webu a svým uživatelům nabízely přístup do několika dalších zdrojů, nikoliv však online a ze kteréhokoliv počítače knihovny. Na počátku nového století lze již hovořit o konsorciálním zpřístupnění zdrojů, objevují se nové nástroje jako federativní vyhledavače (v českém prostředí je používán MetaLib od roku 2002 a jeho nadstavba pro přidané služby SFX), protokol Z39.50 či o něco později "sběrné" technologie jako OAI–PMH. V současné době již knihovny nepřemýšlejí pouze o tom, zda a jak zpřístupnit své zdroje (to je samozřejmostí), ale uvažují o zpřístupnění svých sbírek v uživatelsky vlídném prostředí, které by se stalo jakýmsi základním nástrojem pro všechny klienty knihoven a mohlo "konkurovat" a spíše doplňovat svou přesností a rozsahem zdrojů volně dostupné vyhledávače a portály.
V posledních několika letech knihovny začaly svým uživatelům nabízet své sbírky v katalozích nové generace (next-generation library catalogue), které ve větší míře splňují očekávání současné generace webu znalých uživatelů. Všechny tyto snahy pramení z poznání, že ačkoli knihovní katalogy byly vyvíjeny na poskytování bohatých funkcí souvisejících s dostupností knihovních sbírek a služeb, ne vždy zcela sledují a následují zvyklosti běžné z hlediska vyhledávání na volném internetu.
Webová kultura přeměnila návyky nás všech, uživatelé webových služeb přicházejí do knihovny se stejnými očekáváními a zvyklostmi nasbíranými z používání volného rozhraní internetu. Je třeba tato očekávání vzít v potaz a nabízet katalogy na té samé úrovni stylů a propracovaných systémů jako nabízí běžný web. Z tohoto pohledu mají současné běžně užívané katalogy následující nedostatky1:
Katalogy nové generace prezentují obsah z různých zdrojů knihovny, cílem všech nástrojů je posílení vizuální působivosti (přitažlivosti) a zvýšení množství informací dostupných koncovému uživateli. Jeden z klíčových cílů katalogů nové generace tedy zahrnuje jednotné, jednoduché, přehledné, intuitivní místo vstupu do všech typů zdrojů a informací dostupných v knihovně (katalogy, EIZ, digitální knihovny, portály atd.). Některé součásti zveřejnění obsahu a dalších informací o dokumentu mohou splývat s informacemi, které jsou dostupné již v současných OPAC, např. obálky a další umělecká ztvárnění dokumentu, obsah, resumé, přehledy, recenze, kritiky. Obohacení záznamů není nový koncept, nová jsou však řešení, která usnadňují knihovnám poskytování těchto informací, jako např. Syndetic Solutions2, případně knihovny spolupracují s komerčními subjekty, např. Amazon.com nebo Google Book Search3 .
Jednotlivé snahy a kroky, které předcházely zpracování analýzy, vycházely z přesvědčení, které bylo podpořeno zkušenostmi načerpanými na zabezpečení portálu JIB, že není pro potřeby služeb nejdůležitější vybrané systémy analyzovat z hlediska technického, implementačního, finančního či standardizace(to jsou především podmínky a specifikace,ikdyžproknihovníkyzásadní,kterélzepostupemvývojeačasupřekonat),ale hodnotit je z pohledu uživatele, co přinášejí, jaké služby nabízejí, jak usnadňují a čím rozvíjejí jeho informační potřeby. Toto by měla být základní kritéria výběru nástrojů nového typu. Je nasnadě, že knihovny byly vždy ovlivňovány a omezovány svými finančními možnostmi, možnostmi technického zabezpečení, a že výběr nového SW nástroje byl v konečné podobě kompromisem. To však již není možné, knihovny musejí především myslet na své uživatele, na jejich potřeby, očekávání a rozvoj jejich schopností.
Studiem dostupné odborné literatury bylo vytipováno 6 systémů, které byly testovány na aplikacích zahraničních knihoven, které jsou volně dostupné na webu, dále byly studovány popisy a detaily na stránkách jednotlivých poskytovatelů. Kompletní analýza jednotlivých systémů včetně odkazů na využité aplikace je k dispozici na informačním portálu JIB, v sekci O projektu4.
Na základě zkušeností se systémy MetaLib a SFX a na základě informací o postupech a preferencích při vyhledávání koncovými uživateli (školení, zpětná vazba, atd.) byly stanoveny čtyři okruhy, které byly dále podrobně rozpracovány do konkrétních otázek:
Je třeba zdůraznit, že všechny otázky v jednotlivých okruzích (celkem 71 otázek) vybrané systémy zkoumají z uživatelského hlediska, pokud jsou zahrnuta technická kritéria jednotlivých systémů nebo finanční otázky spojené s implementací/provozem, tak jedině ve spojitosti s uživatelským rozhraním nebo poskytovanými službami. Testování bylo prováděno od listopadu do konce prosince 2008, všechny zjištěné parametry uváděné v analýzách jednotlivých systémů (bez další specifikace) se vážou k tomuto období.
Komentáře k jednotlivým analyzovaným systémům:
Systém AquaBrowser v sobě spojuje grafické i vyhledávací vlastnosti webového prostředí doplněné o unikátní vizuální nástroj "word clouds". Díky svému jednoduchému a uživatelsky vstřícnému rozhraní se stal velmi oblíbeným vyhledávacím nástrojem zejména pro potřeby veřejných knihoven. Společnost Medialab Solutions, producent systému AquaBrowser, vstoupila na trh s vyhledávacími systémy pro knihovny již v roce 2002 a od počátku AquaBrowser vyvíjela takovým směrem, aby se stal jedním z předních systémů katalogů nové generace. V současné době rozhraní AquaBrowser využívá asi 400 knihoven po celém světě, převážně veřejných, nechybí však aplikace ani v akademických knihovnách či konsorciích.
Pro testování jsme zvolili implementace v následujících knihovnách:
University of Pittsburgh – akademická knihovna zpřístupňující v rozhraní AquaBrowseru svůj online katalog, který obsahuje různé typy dokumentů. Oprávnění uživatelé mohou pomocí odkazu využít vzdálený přístup k licencovaným zdrojům – článkům, e-časopisům, e-knihám. V této aplikaci je k dispozici také modul "MyDiscoveries", který slouží pro sdílení informací (hodnocení, tagy, recenze atd.) mezi uživateli.
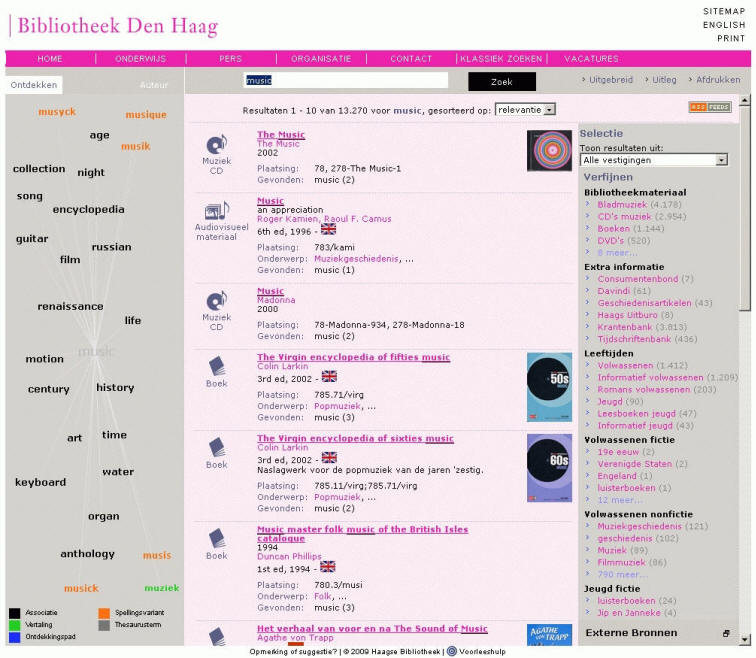
Bibliotheek Den Haag – jedná se o přístup ke katalogu veřejné knihovny, do vyhledávání jsou zahrnuty i externí zdroje, jejichž výsledky se zobrazují odděleně. Přístup k záznamům z těchto zdrojů je podmíněn zadáním uživatelského jména a hesla.
Federativní vyhledávání – testovací aplikace AquaBrowseru s modulem pro federativní vyhledávání. Dotaz probíhá současně ve všech zdrojích, které mohou být zařazeny v předmětových či jiných kategoriích. Primárně jsou zobrazovány výsledky z lokálních zdrojů.
a) Vzhled uživatelského rozhraní
Uživatelské rozhraní systému AquaBrowser je velmi jednoduché, zejména úvodní stránka obsahující pouze jediné vyhledávací pole napovídá, že se systém snaží co nejvíce přiblížit potřebám uživatelů zvyklých pracovat v prostředí webovských vyhledávačů. Grafická podoba rozhraní AquaBrowseru však může být přizpůsobena potřebám instituce, lze ho také integrovat přímo do webových stránek knihovny, aby uživatelé měli z jednoho místa spolu s vyhledáváním k dispozici i další související informace. AquaBrowser je založen na 3 principech, které uživatele postupně navádějí k cíli – získání dokumentu. Jedná se o Search (Vyhledat), Discover (Objevovat) – pomocí tzv. word clouds, a Refine(Zpřesňovat) – pomocí fasetové navigace.
Samotný systém je vybaven velmi jednoduchou textovou nápovědou, která poskytuje pouze základní informace o možnostech vyhledávání. Mnohem větší důraz je v AquaBrowseru kladen na grafické prvky,jako jsou ikony odlišující jednotlivé typy dokumentů nebo navazující služby umožňující získání dokumentu, a zejména netradiční vizuální zobrazování termínů souvisejících se zadaným dotazem – tzv. word clouds.
O tomto nástroji bude podrobněji pojednáno v dalším textu.
Na druhou stranu by uživatelé v systému mohli ve větší míře postrádat nástroje pro získání zpětné vazby, knihovny většinou nabízejí pouze odkaz na službu Ptejte se knihovny nebo běžný kontakt pro zaslání připomínek. AquaBrowser lze rozšířit o doplňkový modul MyDiscoveries, který však slouží především pro sdílení informací mezi uživateli – tagování, psaní recenzí apod.
AquaBrowser je také jedním ze tří testovaných systémů, které podporují standardy pro možnost využívání portálů handicapovanými uživateli, jeho rozhraní je přizpůsobeno pro zrakově znevýhodněné uživatele.
b) Výběr zdrojů
AquaBrowser nabízí velmi jednoduchou cestu k nalezení dokumentu. Celý proces vyhledávání probíhá na pozadí systému, uživatel nemá možnost ovlivnit, ve kterém zdroji by chtěl vyhledávat (v případě paralelního vyhledávání ve více zdrojích najednou), není možné zjistit, které zdroje jsou knihovnou prostřednictvím systému nabízeny.
V aplikacích, které jsme analyzovali, knihovny používají rozhraní AquaBrowseru zejména pro vyhledávání ve svém online katalogu, případně umožňují paralelní vyhledávání
v externích zdrojích, zejména placených online databázích, jejichž výsledky se zobrazují odděleně. Uživatel proto nemusí být zatěžován údaji o zdrojích. Tato strategie by však nemusela vyhovovat knihovnám, které by měly zájem zpřístupňovat prostřednictvím AquaBrowseru i další lokální zdroje (digitální knihovny, autoritní databáze, článkové bibliografické databáze apod.).
c) Zadání dotazu a vyhledávání
Jak již bylo zmíněno výše, v rámci systému AquaBrowser mohou uživatelé vyhledávat ve více zdrojích najednou, a to díky modulu s názvem Federated search (systém také umožňuje integraci s federativními vyhledávači). Výsledky z těchto "vzdálených" zdrojů jsou zobrazovány odděleně od záznamů vyhledaných v lokálních zdrojích, např. online katalogu. Možnosti zapojení vzdálených zdrojů knihovny využívají zejména pro zpřístupnění záznamů ze svých placených online databází. Přístup k záznamům z těchto zdrojů je vázán heslem.
Podobně jako většina ostatních katalogů nové generace AquaBrowser nenabízí možnost prohlížení rejstříků, stejně tak možnosti vyhledávání jsou z našeho pohledu omezené. Hledaný termín je možné zadat do jednoho vyhledávacího pole, dotaz je poté proveden ve všech polích záznamu a výsledkem většinou bývá velké množství záznamů. Vyhledávání lze omezit na konkrétní pole záznamu (autor, název, klíčové slovo) zapsáním výrazů "author", "title" nebo "keyword" přímo do pole, až poté následuje hledaný výraz. AquaBrowser také podporuje vyhledávání podle logických operátorů AND a OR (nutno zadávat velkými písmeny), operátor NOT je nahrazen znaménkem "-". Při vyhledávání lze použít i pravostranné zkrácení výrazu, není nutné zapisovat žádný speciální znak, systém operaci provádí automaticky. V případě, že uživatelé nechtějí této vlastnosti využít, je nutné hledaný výraz zadávat do uvozovek. Přestože AquaBrowser nabízí i pokročilý způsob vyhledávání, většina knihoven ve svých aplikacích volí možnost zadání velmi obecného dotazu do jednoho pole, pro složitější vyhledávání případně odkazuje na katalog v původním rozhraní. V AquaBrowseru mohou uživatelé pro podrobnější vyhledávání/zúžení dotazu využít fasety. Formulář pokročilého vyhledávání umožňuje vyhledávat v několika polích, která jsou však předem definovaná,tzn.jeurčeno,vekterých polích záznamu bude dotaz proveden. Knihovna si může sama nastavit pole pro vyhledávání, kromě základních jako autor, název, předmět, rok vydání, ISBN/ISSN nebo nakladatel, mezi ně patří také např. formát dokumentu nebo signatura. Nicméně i pokročilému způsobu vyhledávání v AquaBrowseru chybí pružnost, zejména širší možnosti pro kombinaci jednotlivých hledaných termínů pomocí Booleovských operátorů. Při zadávání dotazu AquaBrowser uživatelům pomáhá nástrojem "Did you mean...?", v případě, že zadají termín s překlepem, s jazykovou chybou apod. K úpravě zadaného výrazu lze využít také "word clouds", jejichž součástí jsou i skupiny slov zvané "spelling variations" nabízející další alternativní termíny pro zadání dotazu.
d) Zobrazení záznamů
Vyhledané výsledky jsou v AquaBrowseru zobrazeny velmi přehledně, na první pohled je možné odlišit různé typy dokumentů nejen pomocí ikonek, ale i slovním vyjádřením (např. Books, Videos and DVD´s, Website, Journals and Magazines aj.). Přehled zobrazených záznamů uvádí stručné informace o dokumentu, jako je název, autor, rok vydání, předmět, signatura, ale například i edice. Pohyb mezi jednotlivými stránkami je možný pomocí tlačítek "předchozí" a "další", systém rovněž umožňuje přesunutí na první a poslední vyhledaný záznam. Kliknutím na název dokumentu se zobrazí úplný záznam, který obsahuje všechny informace o titulu, včetně údajů o dostupnosti, možnosti objednání či získání dokumentu. Výsledky vyhledávání je možné zobrazit ze všech zdrojů najednou, pouze záznamy z externích zdrojů jsou dostupné odděleně. V případě lokálních zdrojů knihovny si uživatelé mohou zvolit zobrazení záznamů podle lokace/fondu, ve kterém se dokumenty nacházejí, pomocí návěští "Showing results from". AquaBrowser dokáže také slučovat nalezené záznamy neboli odstraňovat jejich duplicity a umožňuje aplikaci metody FRBR buď pomocí speciálního modulu, nebo na základě pravidel pro "FRBRizaci" záznamů, která si knihovna či skupina knihoven může specifikovat a do systému implementovat. AquaBrowser je schopný spolupracovat s jakýmkoliv zdrojem dat a poskytnout uživateli stejně kvalitní záznamy jako původní či originální prostředí katalogu, podporuje formáty typu MARC a XML.
e) Práce s výsledky a navazující služby
Z vlastností katalogů nové generace usnadňujících uživatelům práci s výsledky a poskytujících další navazující služby se nám v testovaných aplikacích podařilo zjistit pouze některé z nich. AquaBrowser je možné obohatit o speciální modul MyDiscoveries, kde si uživatelé mohou jednoduchým způsobem vytvořit svoje konto, které jim slouží zejména pro vytváření tagů, psaní recenzí, ukládání záznamů do seznamů, tedy spíše ke sdílení informací s dalšími uživateli. Modul nenabízí možnost nastavení systému podle potřeby, např. volbu formátu pro zobrazování záznamů, nastavení jazyka apod. Výhodou MyDiscoveries je možnost propojení kont s bází uživatelů knihovny.
V aplikacích, které jsme zkoumali, bylo možné záznamy pouze exportovat do citačního managera (RefWorks, EndNote, ProCite), katalogy nenabízely možnost uložit záznamy na počítač, poslat e-mailem nebo tisknout. Některé z knihoven tyto chybějící funkce nahradily odkazem do svého původního katalogu, který výše zmíněné služby nabízí.
AquaBrowser neumožňuje prohlédnout předchozí zadané dotazy; návrat o několik kroků zpět, například při zužování dotazu pomocí faset, lze provést pomocí tzv. drobečkové navigace (breadcrumbs). Jedním z benefitů systému je možnost využití služby RSS.Zobrazení záznamů prostřednictvím této služby lze libovolně nastavit, buď na stručnou citaci, úplný záznam nebo vybraná pole záznamu. V aplikacích jsme se také setkali s vítaným pomocníkem – službou Ptejte se knihovny, která bývá do systému integrována převážně formou odkazu.
AquaBrowser dokáže spolupracovat s jakýmkoliv knihovním systémem, který umožňuje export záznamů ve formátu MARC. Kromě online katalogu však mohou být integrovány i další zdroje knihovny – bibliografické či plnotextové databáze,digitální knihovny,autoritní databáze aj. Systém podporuje různé standardy pro stahování dat – Z39.50, SRU/SRW, OAI, Webfeat, SerSol.
Jak vyplývá z předchozího textu, v rámci AquaBrowseru je možné vyhledávat také v externích zdrojích, online databázích, které si knihovny předplácejí. Oprávněnost využívat tyto zdroje, resp. prohlížet z nich vyhledané záznamy, je vázána na přístupové heslo. Nástroj pro autentizaci může být propojen s databází uživatelů knihovny.
AquaBrowser využívá původní OPAC knihovny pro zobrazování aktuální dostupnosti a statusu dokumentu. V případě, že chce uživatel provést požadavek na výpůjčku nebo rezervaci dokumentu, je odkazován do originálního prostředí katalogu. Prostřednictvím AquaBrowseru také není možné využít další služby vážící se k získání dokumentu, jako např. objednání kopie, služby DDS apod. V aplikacích, které jsme analyzovali, jsme se s takovým případem nesetkali, je však možné, že tyto služby může některá z knihoven nabízet prostřednictvím původního OPAC.
Navazující služby by knihovny mohly uživatelům v rámci AquaBrowseru zprostředkovat zapojením nástroje typu link resolveru. AquaBrowser podporuje standard OpenURL potřebný pro fungování link resolveru, nicméně z testovaných aplikací se zdá, že knihovny zatím této možnosti nevyužily.
Velmi atraktivním prvkem, který se v systému objevuje, je možnost obohacování záznamů o náhledy obálek, obsahy, recenze nebo stručné anotace. Lze využít některý z komerčních nástrojů, např. Syndetic Solutions od firmyBowker,AquaBrowsersivšakrozumí i s volně dostupnými zdroji jako Google Book Search. Do záznamu je možné integrovat odkaz na API rozhraní Google Book, jehož prostřednictvím se uživatelé mohou dostat až k plnému textu naskenovaného dokumentu.
Tematické třídění a možnost specifikace dotazu Jednou z výjimečných vlastností systému AquaBrowser jsou tzv. word clouds, jakási vizuální mapa shluků slov, která se generuje na základě zadaného dotazu. Word clouds zobrazují překlady výrazů do jiných jazyků, navrhují alternativní slova při překlepech nebo chybném zadání a nabízejí další související termíny a synonyma, čímž pomáhají uživatelům při formulování dotazu. Každý typ výrazů je zvýrazněn jinou barvou, po kliknutí na konkrétní termín se spustí nové vyhledávání. Všechny dosud použité výrazy však stále zůstávají v kontextu nového dotazu, v rámci word clouds jsou zvýrazněny modrou barvou. Word clouds vznikají tak, že AquaBrowser porovnává zadané výrazy s metadaty v záznamech OPAC knihovny. Pro word clouds je také možné využít slovník, tezaurus nebo databázi autorit.
Dalším významným nástrojem pro zpřesňování či zužování dotazu je vyhledávání pomocí faset, které uživateli pomohou získat pouze určitou skupinu dokumentů odpovídajících konkrétnímu hledisku. Pomocí drobečkové navigace (breadcrumbs), která se nachází nad vyhledanými výsledky, se však uživatelé vždy mohou vrátit k předchozí fasetě či původnímu dotazu. AquaBrowser nabízí bohatou skladbu faset, jejichž počet si knihovna může sama nastavit. Nejčastěji se objevují fasety pro typ dokumentu, autora, předmět, jazyk, edici, rok, žánr, téma nebo místo.
Vyhledané výsledky je také možné seřadit pomocí relevance, roku, názvu nebo autora.
V této oblasti může být AquaBrowser oproti klasickému katalogu pro knihovnu velkým přínosem. Vzhledem k tomu, že v České republice zatím neexistuje žádná funkční instalace AquaBrowseru, nepodařilo se nám zjistit, jak by systém dokázal reagovat na češtinu, zejména u nástroje word clouds.
Technické vlastnosti a implementace AquaBrowser má již okolo 400 implementací po celém světě, je rozšířen zejména mezi veřejnými knihovnami. Podle zástupců firmy Medialab lze systém implementovat ve velmi krátkém časovém horizontu, knihovny si také mohou jeho rozhraní upravit dle svých potřeb. Průběh instalace i technické požadavky pro bezproblémový chod systému jsou podrobně popsány v dokumentu s názvem AquaBrowser FAQ5. Zákazník hradí cenu za licenci k systému a roční poplatek za údržbu, výše těchto poplatků se řídí velikostí fondu knihovny. Dvojjazyčné rozhraní je již v ceně systému.
Firma Medialab nabízí zákaznickou podporu prostřednictvím telefonu nebo e-mailu, je také možné využít tematická školení, která probíhají vzdáleně (po síti). Některé případy si mohou vyžádat školení za přítomnosti pracovníka Medialab přímo v knihovně (ovšem za poplatek navíc), pracovníci knihovny mohou být také proškoleni v budově Medialab. Limit pro počet souběžně pracujících uživatelů není v AquaBrowseru omezen, při testování jsme nepociťovali, že by měl systém při vyhledávání problém s češtinou, ani při zobrazování diakritiky. Knihovny jistě oceňují velmi podrobné statistické výstupy, které AquaBrowser zpracovává, např. počet zadaných dotazů za určité období, využití filtrů,nejčastější výsledky vyhledávání, využívání paralelního vyhledávání atd.
Cílem Encore, který je produktem firmy InnovativeI nterfaces,nenínahraditvknihovnáchdosud užívané katalogy nebo jiné poskytované databáze. Encore je rozhraní, které se stávajícími zdroji knihovny spolupracuje, množství zdrojů i více zviditelňuje a uživatelsky přitažlivým způsobem prezentuje vyhledaná data. Je možné, že právě to je příčinou, proč některé funkce, které jsou standardně dostupné v současných online katalozích nebo licencovaných databázích, zatím ve zkoumaných aplikacích chybí.
V rámci analýzy byly zkoumány tyto instalace systému Encore:
University of Nebraska – Lincoln Libraries (UNL Libraries) – z testovaných aplikací zde Encore nabízí nejbohatší skladbu zdrojů, UNL Libraries se zvláště zaměřují na podporu sklízení dat. Před publikováním tohoto článku byla nově implementována verze 3.0. Aktuálně Encore UNL Libraries umožňuje prohledávat katalog UNL, digitální sbírky vytvářené na UNL, pomůcky k dokumentům uloženým v univerzitních archivech, Digital Commons – institucionální repozitář UNL a vybrané licencované zdroje.
Wayne State University – University Libraries (WSU University Libraries) – knihovna využívá Encore přibližně od srpna 2008, nyní je do Encore zapojený katalog knihovny a licencované zdroje. V budoucnosti by se mělo vyhledávání rozšířit i o další databáze a lokální digitální zdroje.
Scottsdale Public Library – patří mezi knihovny, které se od počátku podílely na vývoji Encore. V rozhraní Encore mohou uživatelé prohledávat katalog knihovny a licencované databáze. Knihovna nabízí online registraci, díky níž je možné využívat v Encore (a případně též v ResearchPro) i licencované zdroje. Veškeré informace o způsobu vyhledávání v externích licencovaných zdrojích či o práci s nalezenými záznamy vycházejí tedy z aplikace Scottsdale Public Library.
a) Vzhled uživatelského rozhraní
Z uživatelského hlediska je rozhraní Encore velmi přehledné a v kladném slova smyslu graficky jednoduché a čisté. Ztohoto důvodu pravděpodobně není Encore vybavený rozsáhlejší nápovědou přímo od producenta systému (např. v kontextové podobě). Nejvíce informací o novém katalogu Encore, jeho obsahu a způsobu využívání najdeme na stránkách UNL Libraries, které také z našeho pohledu využívají systém Encore nejpokročilejším způsobem. Vzhledem k formulaci informačních textů se domníváme, že nalezené nápovědy a různé výukové materiály vznikly přímo v jednotlivých knihovnách.
Encore UNL Libraries od doby, kdy probíhala analýza, mírně změnil v souvislosti s přechodem na verzi 3.0 svůj vzhled a současná grafická podoba tétoaplikace se může některým uživatelům jevit jako méně výrazná. Všechny analyzované instalace Encore zachovávají grafické rozdělení obrazovky na tři sloupce. Výsledky vyhledávání se zobrazují v prostředním sloupci, levý je věnován fasetám. Po pravé straně pak uživatelé najdou klíčová slova navrhovaná pro upřesnění dotazu (RefinebyTag),nabídku"externích" zdrojů (Articles and More) a další doplňující informace (např. Recently Added nebo Popular Choices). K záznamům mohou knihovny doplnit ikonky, které identifikují druh dokumentu; příjemné je, že hledaná slova jsou pro rychlejší orientaci v záznamech barevně zvýrazněna.
Encore nabízí informaci o počtu nalezených záznamů pouze v přehledu výsledků hledání, při prohlížení úplných záznamů již tento údaj není k dispozici a záznamy nejsou očíslované. Pro pohyb mezi záznamy v úplném zobrazení slouží svislá lišta s náhledy obálek, která je výrazným grafickým prvkem rozhraní. SystémEncore obsahuje i nástroj pro zpětnou vazbu s uživateli. Prostřednictvím tzv. Community Tags, Community Reviews mohou registrovaní uživatelé do záznamů přidávat své poznámky, názory, v některých instalacích se objevují i hvězdičky pro hodnocení dokumentu.
Bohužel se nám u tohoto systému nepodařilo z dostupných informací zjistit, do jaké míry odpovídá Encore standardům tvorby webu pro handicapované. Překvapilo nás jen, že ve všech aplikacích se v záhlaví prohlížeče zobrazuje pouze název systému (<title>Encore</title>), který není doplněn o bližší identifikaci konkrétní knihovny.
b) Výběr zdrojů
Při práci s Encore si uživatelé nemohou zvolit zdroje, které by chtěli přednostně prohledávat a nenajdou zde ani jejich základní charakteristiku. Tyto údaje jsou k dispozici spíše na stránkách knihoven, např. UNL Libraries v tomto směru poskytují velmi dobrý přehled. Nenalezli jsme také žádnou informaci o limitu pro počet souběžně prohledávaných zdrojů, v boxu "Articles and More" je však uvedeno vždy pouze pět licencovaných databází. Odkaz "more resources" vede u Scottsdale Public Library do systému
ResearchPro, podmínkou pro další práci je registrace v knihovně.
c) Zadání dotazu a vyhledávání
Encore umožňuje paralelní hledání ve více zdrojích. Katalogy a různé digitální knihovny (v UNL Libraries jsou pro potřeby vyhledávání v Encore tyto zdroje sklízeny pomocí Encore Harvester) jsou prohledávané odděleně od externích zdrojů. K externím zdrojům patří např. různé licencované databáze nebo Google Scholar, jejich přehled se zobrazuje v samostatném boxu "Articles and More".
Systém Encore nenabízí v analyzovaných aplikacích možnost prohlížení zapojených zdrojů prostřednictvím rejstříků. Pro zadání dotazu je k dispozici vždy pouze jedno vyhledávací pole, které odpovídá zvyklostem vyhledávání na internetu. V této fázi tedy není v Encore možné specifikovat, zda se hledané slovo má nacházet v poli autor,název, předmět, rok vydání atd. Zpřesnění dotazu tímto směrem je možné pouze při prohlížení výsledků hledání, a to pomocí nabízených faset, např. faseta "Search Found In" upřesňuje, ve kterém poli byl výraz nalezen, fasety "Language" a "Publish Date" pak umožňují zvolit jazyk dokumentu nebo konkrétní rok vydání. Součástí Encore je odkaz na pokročilé hledání, které však probíhá mimo Encore v rozhraní původního katalogu dané knihovny.
Encore podporuje zadávání dotazu pomocí některých logických operátorů. Jednotlivá slova zapsaná do vyhledávacího pole jsou automaticky spojena operátorem AND, operátor OR není podporován. K vyloučení některých termínů je nutné použít symbol – (např. –history), hledaná fráze se zadává do uvozovek. Proximitní operátory Encore při formulaci dotazu nevyužívá. Pro všechny zdroje integrované do Encore je používán jednotný symbol pro pravostranné rozšíření hledaného termínu. Vyhledávací pole s posledním provedeným dotazem se zobrazuje i v přehledu nalezených záznamů a při prohlížení záznamů v úplném zobrazení. Uživatel tak může kdykoliv doplnit do vyhledávacího pole další termín, jímž chce svůj dotaz zpřesnit. Všechna hledaná slova se tedy zapisují do jednoho řádku.
V souladu s rysy katalogů nové generace i Encore má integrovanou nápovědu při zadávání dotazu, tzv. našeptávače Did you mean ... ? V případě, že Encore považuje zadané slovo za chybně zapsané nebo je výsledkem hledání malý počet záznamů, nabídne uživateli po provedení dotazu jinou variantu zápisu. Pro upřesnění výsledků dotazu je možné využít klíčová slova (termíny) "Limit by Tag", které Encore zobrazuje vždy u výsledků hledání. Funkce "Limit by Tag" v Encore nepředstavuje možnost alternativního způsobu zadání nového dotazu, ale je spíše nástrojem pro zpřesnění skupiny nalezených záznamů pomocí údajů převzatých z věcného popisu jednotlivých záznamů.
Jak jsme již výše uvedli, Encore umožňuje paralelní vyhledávání ve více zdrojích. Bližší pohled na způsob zadávání dotazu a možnosti vyhledávání Encore ukazuje, že u jednotlivých zapojených zdrojů nabízí jejich nativní rozhraní více možností pro formulaci dotazu a vyhledávání než prostředí Encore.
d) Zobrazení záznamů
Výsledky vyhledávání ve všech zapojených zdrojích se v Encore zobrazují ve dvou samostatných oddělených skupinách. První skupinu tvoří záznamy z volně dostupných zdrojů, nejčastěji jde o katalogy knihoven a různé digitální knihovny. Všechny záznamy nalezené v zapojených volných zdrojích jsou v Encore prezentovány najednou. Nejširší nabídku zdrojů prohledávaných prostřednictvím rozhraní Encore obsahuje z analyzovaných aplikací systém UNL Libraries. Pomocí fasety Collection si zde uživatelé mohou filtrovat výsledky také podle jednotlivých zapojených digitálních knihoven.
Druhou skupinou, která je zobrazována odděleně od záznamů z volných zdrojů, jsou výsledky z externích databází (box "Articles and More"). Přístup k výsledkům vyhledávání je vázaný na registraci uživatele v dané knihovně. Nalezené záznamy mohou být zobrazeny najednou bez ohledu na zdroj, z něhož pocházejí, uživatelé si však mohou vybrat i konkrétní databázi a prohlížet si pouze záznamy vyhledané v tomto zdroji.
Před zobrazením výsledků Encore nalezené záznamy neporovnává a neprobíhá zde ani odstraňování případných duplicit. Všechny nalezené záznamy jsou stahovány ze zapojených zdrojů naráz a uživatel tedy může okamžitě pracovat s celou množinou vyhledaných záznamů. Pro prezentaci výsledků Encore v analyzovaných aplikacích nevyužívá metodu FRBR. Bohužel se nám z dostupných materiálů nepodařilo zjistit, jaké formáty (MARC, UNIMARC, MARC21 atd.) jsou při konverzi údajů v systému podporovány a zda si knihovny mohou vytvořit vlastní pravidla pro konverzi. Obsahově se záznamy
z volných zdrojů (katalogy, digitální knihovny) v Encore shodují se záznamy v originálních rozhraních jednotlivých zapojených zdrojů. U licencovaných zdrojů je záznam v Encore stručnější než v nativním rozhraní, v Encore se zobrazuje pouze název článku, autor a informace o zdrojovém dokumentu. Součástí každého záznamu je však odkaz, který směřuje přímo do dané licencované databáze.
e) Práce s výsledky a navazující služby
Systém Encore je "pouze" rozhraním, které spolupracuje s katalogy, digitálními knihovnami, licencovanými databázemi a dalšími zdroji knihovny. V rámci systému Encore uživatel zadává dotaz a v Encore jsou také prezentovány výsledky vyhledávání. Neregistrovaní uživatelé si nemohou Encore v rámci jedné relace přizpůsobit svým potřebám (např. zvolit počet záznamů zobrazených na stránce nebo preferovaný formát pro zobrazení). Ze všech analyzovaných aplikací Encore se uživatel může přihlásit do své schránky v rozhraní původního katalogu, nezdá se však, že by pak měl možnost si rozhraní Encore jakkoliv individualizovat. U aplikací nižších verzí (Scottsdale Public Library, WSU University Libraries) musí uživatel využít pro návazné služby (např. uložení záznamu v různých formátech a jeho odeslání e-mailem nebo tisk, export záznamů do programu pro správu citací) originální rozhraní katalogu, digitální knihovny atd. Encore 3.0 již nabízí schránku (My Cart), do níž je možné vybrané záznamy ukládat a jejím prostřednictvím odeslat na zadanou e-mailovou adresu. Export záznamů do systému RefWorks je v Encore 3.0 zajišťován prostřednictvím WebBridge, vlastního nástroje firmy Innovative Interfaces pro přidané služby. Mezi služby, které jsme v analyzovaných aplikacích Encore nenalezli, patří i SDI nebo RSS, i když v Encore 2.0 by "Patron records alert" měl být dostupný. K funkcím, které Encore postrádá, patří i přehled dotazů provedených v rámci jednoho přihlášení. Přímo v rozhraní Encore nebo v nástroji WebBridge bývá také uveden odkaz na služby typu Ptejte se knihovny (např. Ask a Question).
S výjimkou UNL Libraries využívají všechny analyzované knihovny možnost zobrazovat v Encore u záznamů i náhledy obálek, Scottsdale Public Library např. nabízí v záznamech odkazy na biografie,anotace,recenze,informace z obálky, veškeré texty se zobrazují v samostatném okně v grafickém rozhraní Encore.ZáznamyUNLLibrariesobsahují odkazy na informace uveřejněné na serveru Kongresové knihovny – Library of Congress (obsahy knih, charakteristiky vydavatelů, biografické údaje atd.). Při obohacování záznamů je v Encore možné využívat standardní komerční produkty (Syndetic Solutions, Taylor Contents Cafe), verze 3.0 by měla podporovat přebírání náhledů obálek z Amazon.com.
Součástí záznamu nalezeného dokumentu je informace o počtu exemplářů a jejich dostupnosti, u časopisů i údaje o online verzích dostupných v rámci různých licencovaných databází. Bližší informace o konkrétních licencovaných zdrojích jsou shromážděny pod ikonou "i". Uživatelé jednotlivých aplikací se mohou z Encore přihlásit ke svému kontu, které je udržováno v originálním katalogu dané knihovny a pomocí odkazu "Request it" si vybranou knihu objednat.
Jak jsme již dříve uvedli, Encore umožňuje ve svém rozhraní integrovat různé typy zdrojů, nejčastěji jsou zapojeny katalogy, digitální knihovny, licencované zdroje (přístup k výsledkům vyhledávání je podmíněn registrací uživatele knihovny). V žádné z analyzovaných aplikací jsme nenalezli zdroje typu e-knih, nebo autoritních databází.
Společnost Innovative Interface vyvinula vlastní nástroje pro správu licencovaných zdrojů a přidané služby (ERM, WebBridge), které jsou kompatibilní s Encore. Prostřednictvím WebBridge si v UNL Libraries mohou uživatelé např. objednat doručení dokumentu. WebBridge nalezneme i v Encore Scottsdale Public Library (odkaze "Explore"), tato aplikace WebBridge nabízí vyhledání relevantních článků v plnotextové databázi EBSCO MasterfilePremier, zobrazení recenzí v ContentCafeaAmazon.com,nalezení dalších exemplářů vybraného dokumentu v blízkých knihovnách pomocí OCLC
World Cat a také odkazy na vyhledávače Google, Ask.com a Yahoo. V prostředí Encore je však možné využít i SFX, stejně tak je Encore schopen spolupracovat se systémy Aleph 500 a MetaLib. Dostupné materiály nezmiňují v souvislosti s Encore systém HAN, který NK ČR užívá pro zpřístupňování a správu licencovaných zdrojů.
Mezi implementovanými standardy je možné uvést OAI-PHM využívaný v Encore pro sklízení digitálních knihoven (např. UNL Libraries), podle informace z června 2008 však Encore 2.0 nepodporuje standard Z39.50.
Výsledky dotazu lze v Encore dále zpřesňovat pomocí nabídky v boxu "Limit by Tag".
V "Limit by Tag" se uživateli automaticky nabízejí předmětová hesla, která se v nalezených záznamech vyskytují nejčastěji. Velikost použitého písma u jednotlivých předmětových hesel přímo odpovídá frekvenci jejich výskytu v nalezených záznamech.
Encore ve všech analyzovaných aplikacích nabízí fasety pro filtrování výsledků dotazu (Search Found In, Format, Collection, Location, Language, Publish Date). Z každé fasety lze vybrat jednu a s její pomocí dotaz filtrovat. Použité fasety uživatel může ze zúženého výsledku i v libovolném pořadí odebrat a výsledky dotazu tak dále podle potřeby modifikovat.
Nalezené záznamy jsou automaticky řazeny pomocí systému RightResult, dále je uživatelé mohou setřídit i podle názvu a roku vydání. Všechny výše zmíněné funkce nabízí Encore podle našeho zjištění pouze u záznamů z volně dostupných zdrojů (katalogy, digitální knihovny). U externích zdrojů prohledávaných v boxu "Articles and More" nejsou žádné přidané služby k dispozici (Scottsdale Public Library), bohužel nedokážeme určit, do jaké míry jde o standardní řešení.
Odpovědi na otázky z tohoto okruhu nejsou v přístupných materiálech příliš často zveřejňovány. Podle dostupných informací je možné Encore považovat za stabilizovaný systém. Knihovny v této chvíli využívají Encore 2.0, v některých je již instalovaná verze Encore 3.0. Práci na vývoji Encore oznámila společnost Innovative Interfaces v květnu 2006. Na vzniku Encore se podílelo v dvou fázích 21 partnerských knihoven a ve 12 veřejných a vysokoškolských knihovnách z této skupiny byl Encore funkční v říjnu 2007. I na verzi 2.0 uvolněné v červnu 2008 spolupracovaly knihovny (31 partnerů) a ohlášen byl také vývoj Encore 3.0. Innovative Interfaces nadále kooperují s knihovnami při vytváření dalších prvků Encore, např. na statistickém modulu Encore Reporter. Ten se přiřadí k již existujícím volitelným modulům, kterými je možné Encore doplnit (Encore Discovery Client, Encore Harvesting Services a Encore Query API). Ze zprávy z dubna 2008 vyplývá, že Encore si zvolilo více než 100 knihoven po celém světě, M. Breeding ve svém článku dokonce uvádí 153 instalací6. V současné době by systém Encore nejspíše neměl podporu v českém jazyce. Nejbližší evropská zastoupení společnosti jsou ve Francii, Španělsku, Švédsku a Velké Británii. Technická podpora při řešení problémů by tedy pravděpodobně nemohla být formou osobní návštěvy příslušného pracovníka.
Společnost Endeca Technologies byla založena v roce 1999 a působí v oblasti informačních technologií a přístupu k informacím. Produkt Endeca Information Access Platform je jejím hlavním softwarovým řešením, v současné době je instalován asi ve 300 institucích, z valné části komerčních subjektech. Díky svým rozsáhlým možnostem v oblasti organizace, pořádání a zpřístupňování informací, systém Endeca pronikl i do knihoven, kterým může nabídnout zejména silné vyhledávací vlastnosti a velmi kvalitní technologii Guided Navigation pro fasetovou navigaci.
Analyzovali jsme implementace v následujících knihovnách:
North Carolina State University (NCSU) Libraries – jedná se o první aplikaci systému Endeca v knihovnách, nabízí vyhledávání v katalogu knihoven, který obsahuje všechny typy zdrojů, včetně dokumentů s placeným přístupem (e-knihy, e-časopisy). Přístup
k těmto zdrojům je zajištěn přes heslo, mimo kampus univerzity mohou uživatelé knihovny využít i vzdálený přístup. Při jakýchkoliv potížích je možné bezprostředně kontaktovat pracovníky knihovny pomocí služby Ask Us, Chat now.
Triangle Research Libraries Network – rozhraní umožňuje vyhledávání v katalozích 4 akademických knihoven. Jako výchozí je nastaveno vyhledávání ve všech zdrojích zároveň, pro zadání dotazu si lze též zvolit pouze jediný zdroj. Studenti a pracovníci univerzit mohou prostřednictvím speciálního konta využít službu Document delivery pro články a MVS pro určité druhy dokumentů.
State University Libraries of Florida – tato aplikace sdružuje 11 floridských akademických knihoven, které je možné souběžně prohledávat. U každého vyhledaného záznamu se objevuje dostupnost dokumentu pro jednotlivé zapojené knihovny. Zajímavostí této aplikace je integrace přidaných služeb SFX, jejichž ikona se zobrazuje u dokumentů s ISSN.
McMaster University Libraries – katalog knihoven zpřístupňuje různé typy zdrojů, včetně licencovaných online zdrojů pro oprávněné uživatele. Požadavek na dostupnost dokumentu se ověřuje v původním ILS. Knihovna využívá také možnost "otevírání" a "uzavírání" jednotlivých faset, tato funkce se aktivuje kliknutím na název fasety.
a) Vzhled uživatelského rozhraní
Uživatelské rozhraní systému Endeca zohledňuje trend přizpůsobování vzhledu nových katalogů webovému prostředí, jeho jednoduchost a přehlednost se snaží zachovat všechny zkoumané knihovny, i když zčásti si grafiku a některé funkce přizpůsobily potřebám svých uživatelů. Formulář pro vyhledávání lze rovněž integrovat do webových stránek knihovny, takže uživatelé mohou získat všechny potřebné informace o knihovně i vyhledávat v katalogu pohodlně z jednoho místa.
Do rozhraní Endeca lze také zabudovat samostatné portlety, kam knihovny umisťují zejména nápovědy nebo tipy a rady pro vyhledávání. Podobně jako ostatní katalogy nové generace i Endeca ve svém rozhraní využívá grafické prvky v podobě ikon odlišujících různé typy dokumentů, možnosti práce s vyhledanými výsledky nebo služby pro získání dokumentu.
Uživatelé mohou vyjádřit své připomínky, komentáře a názory pomocí odkazů typu "Send us our comments", které se nejčastěji vyskytují v nápovědě, horní navigační liště nebo patičce stránky. Určitým standardem se v katalozích nové generace stává zapojení služby Ptejte se knihovny, která bývá k dispozici především prostřednictvím odkazu v horní liště. U systému Endeca jsme se však setkali také s aplikací, kde nás logo služby s nabídkou chatování (v případě nedostupnosti možnost zaslání e-mailu) věrně provázelo ve všech fázích práce se systémem.
Dostupné zdroje nezmiňují informaci, zda je systém přizpůsoben také handicapovaným uživatelům.
b) Výběr zdrojů
Knihovny, jejichž systémy jsme zkoumali, aplikovaly rozhraní Endeca především na svůj online katalog, některé instalace zpřístupňují v Endeca i více zdrojů (vždy katalogy knihoven), které jsou paralelně prohledávány. Endeca však nepodporuje klasické federativní vyhledávání, kdy jsou výsledky stahovány ze vzdálených zdrojů, ale je nutné záznamy z původního OPAC do systému nejprve naimportovat. Z těchto záznamů si pak Endeca vytváří indexy, ve kterých probíhá vyhledávání. Nicméně i poté systém zůstává do určité míry závislý na původním katalogu, z něhož získává především aktuální informace o statusu dokumentu nebo jeho dostupnosti.
Aplikace nabízející paralelní vyhledávání ve více zdrojích uvádějí jejich přehled většinou na úvodní straně portálu, případně také v nápovědách nebo pomůckách pro vyhledávání. Jako výchozí je nastaveno vyhledávání ve všech zdrojích, uživatelé si případně mohou pro vyhledávání vybrat pouze jediný zdroj. Libovolnou kombinaci zdrojů ani žádná jiná nastavení systém nenabízí.
c) Zadání dotazu a vyhledávání
Zřejmě ojedinělou vlastností systému Endeca, která se u katalogů nové generace příliš nevyskytuje, je možnost prohlížení rejstříků bez nutnosti zadání dotazu. Jedná se zejména o prohlížení podle předmětových kategorií, některé aplikace umožňují dokonce prohlížení podle předmětů a signatur Kongresové knihovny nebo Národní lékařské knihovny USA, či podle nově přidaných titulů.
Endeca oproti ostatním katalogům nové generace uživatelům poskytuje širokou paletu funkcí a možností pro vyhledávání. Pro zadání jednoduššího dotazu nabízí snadný způsob vyhledávání prostřednictvím jednoho vyhledávacího pole, je však možné zvolit, ve kterém poli záznamu bude dotaz proveden (všechna pole, název, název časopisu, autor, předmětové heslo, ISBN/ISSN, také edice nebo signatura). Pro zadání složitějšího dotazu je vhodnější pokročilý způsob vyhledávání s několika vyhledávacími poli (všechna pole, slova z názvu, slova z autora, předmětová hesla, ISBN/ISSN), navíc lze dotaz omezit prostřednictvím dalších speciálních polí pro jazyk dokumentu, formát, druh dokumentu, časový interval nebo knihovnu. Zadané výrazy jsou také automaticky pravostranně rozšiřovány, není nutné zadávat žádný speciální znak. Systém podporuje i vyhledávání podle fráze, hledané výrazy stačí vložit do uvozovek. Vyhledávání pomocí Booleovských operátorů lze provádět pouze ve zvláštní části formuláře pro pokročilé vyhledávání nazvané "Boolean Search", v ostatních polích Endeca na operátory nereaguje.
Kromě klasického vyhledávání se v systému můžeme setkat i s vyhledáváním podle počátků slov ("Search begins with..."), kde mají uživatelé opět na výběr z několika polí.
Při zadávání dotazu jsou uživateli nápomocny nástroje pro kontrolu pravopisu jako "Also searched for...", kdy systém automaticky vyhledá výsledky pro správně zadaný termín, nebo navrhuje vhodnější variantu pomocí "Did you mean...?". Při velkém množství vrácených výsledků lze dotaz upřesnit pomocí funkce "Search within results", která se nachází pod vyhledávacím formulářem. Výběrem pole a zadáním dotazu se nový výraz spojí s původním termínem pomocí AND. Vyhledané výsledky je dále možné omezit na konkrétní skupinu dokumentů pomocí nástroje "RefineYourSearch", konkrétně na aktuálně dostupné dokumenty, dokumenty dostupné online nebo nové tituly. Endeca pro zpřesňování dotazu nabízí rovněž fasetovou navigaci, které se budeme věnovat dále v textu.
d) Zobrazení záznamů
Přehled vyhledaných záznamů poskytuje stručné bibliografické údaje o vyhledaných titulech doplněné názornou ikonkou odlišující typy dokumentů. Důležitým údajem v záznamu je také umístění a dostupnost dokumentu. Po kliknutí na název dokumentu je uživatel přesunut do úplného zobrazení, kde je možné vybrat si požadované informace pomocí záložek (podrobná lokace dokumentu, anotace, obsah, předmětová hesla,
MARC formát, také např. první kapitola), což udržuje záznam přehledným i při velkém množství údajů. McMaster University dokonce ve svém katalogu nabízí netradiční zobrazení plných záznamů, které se pouze "rozvinou" přes vyhledané výsledky a uživatelé tak zůstávají stále na stejné stránce.
Při paralelním vyhledávání ve více zdrojích knihovny využívají možnosti zobrazovat nalezené záznamy ze všech zdrojů najednou, pomocí fasetové navigace (faseta Location) si pak uživatelé mohou zvolit zobrazení záznamů pouze z určitého zdroje. Jak jsme již uvedli v předcházejícím oddílu s názvem "Výběr zdrojů", konkrétní katalog, ve kterém bude vyhledávání provedeno, lze také nastavit ještě před zadáním dotazu. Endeca umožňuje rovněž slučování záznamů a odstraňování duplicit, což zpřehledňuje výsledky nalezené ve více zdrojích. Pokud se stejný záznam objevuje ve více katalozích, uživateli se zobrazí pouze jednou ("master record") spolu s informací, ve kterých zdrojích se nachází, a s aktuálními údaji o dostupnosti nebo možnosti získání dokumentu. Dle našich zjištění se knihovny v rámci systému Endeca také snaží aplikovat metodu FRBR, probíhá její testování. Ve zkoumaných implementacích jsme se zatím setkali pouze se zpřístupňováním záznamů z OPAC knihoven, které byly k dispozici ve formátu MARC. Vzhledem k tomu, že některé z knihoven uvažují také o zapojení dalších typů dokumentů, např. digitálních, lze předpokládat, že Endeca dokáže pracovat i s jinými formáty dat.
e) Práce s výsledky a navazující služby
Při práci s vyhledanými výsledky mohou uživatelé v systému Endeca využít širokou nabídku funkcí, kromě tradiční možnosti tisknout záznamy a posílat je na e-mail (ukládání záznamů na počítač Endeca, zdá se, neumožňuje) se jedná i o zaslání záznamu prostřednictvím textové zprávy na mobilní telefon, možnost exportu záznamů do citačního managera (podporováno RefWorks a EndNote), získání citace pomocí ikony "Cite this" v citačních formátech APA, Chicago, Harvard, MLA nebo Turabian, či permanentního odkazu k záznamu. Endeca na State Universities of Florida umožňuje také ukládání záznamů do schránky, které lze hromadně poslat na e-mail, vytisknout, exportovat či změnit způsob zobrazení.
Některé knihovny také ponechávají u plných záznamů z Endeca odkaz na jejich zobrazení v původním OPAC, který může poskytovat ještě další služby, např. v Endeca chybějící ukládání záznamů na počítač, odkaz na vyhledání podobných titulů nebo více titulů od stejného autora. Nabídka těchto funkcí se však vždy odvíjí od nastavení původního ILS, proto se v jednotlivých knihovnách může lišit.
Uživatelé v systému jistě oceňují propojení na své uživatelské konto, kde si mohou kontrolovat a prodlužovat své výpůjčky, také ukládat nalezené záznamy nebo provedené dotazy. Tato uživatelská konta však slouží pouze registrovaným čtenářům knihoven, které mohou dostupné služby libovolně nastavit. V aplikaci na State Universities of Florida prostor pro personifikaci systému i pro neregistrované uživatele do jisté míry nahrazuje funkce schránky pro ukládání vyhledaných záznamů.
V rámci Endeca si uživatelé nemohou prohlédnout předchozí provedené dotazy, mohou se pouze vrátit k předchozím operacím (upřesňování dotazu prostřednictvím "Search within results" nebo faset) pomocí drobečkové navigace (breadcrumbs), u které se také nabízí ikona pro využití služeb RSS.
I když knihovny zpřístupňují přes rozhraní Endeca záznamy různých typů dokumentů (knihy, časopisy, elektronické dokumenty, mikrofilmy,videaatd.),dlenašehoúsudkusevždy jedná o záznamy z jednoho zdroje – online katalogu. Nicméně některé z knihoven uvažují o integraci dalších zdrojů, zejména digitálních knihoven nebo článkových databází. Z tohoto důvodu předpokládáme, že Endeca dokáže spolupracovat s různými typy zdrojů. Součástí katalogů knihoven bývají i licencované elektronické časopisy a knihy (články jsou k dispozici v samostatných databázích mimo Endeca), přístup k plnému textu bývá omezen heslem, příp. IP adresou počítače. Knihovny využívají různé nástroje pro autentizaci s propojením na bázi svých uživatelů, pro vzdálený přístup také např. EZ Proxy. Samotný systém nenabízí žádný nástroj typu link resolver, do rozhraní Endeca však lze integrovat nástroj SFX pro přidané služby. V jedné z testovaných aplikací se ikona SFX zobrazuje u všech záznamů, které obsahují ISSN. Díky propojení systému Endeca na původní OPAC knihovny může uživatel získat informace o aktuálním statusu dokumentu, jeho dostupnosti a případně také využít navazující služby jako je objednání dokumentu z knihovního fondu (a následný výběr knihovny, ve které má být dokument připraven) nebo zadání požadavku na MVS. Záznamy je možné zatraktivnit přidáním náhledů obálek, obsahů, anotací, recenzí, hodnocení apod., pro které knihovny využívají i volně dostupné zdroje, např. server Amazon.
Endeca je vybavena silným nástrojem pro fasetovou navigaci (Guided Navigation), která uživateli umožňuje zúžit vyhledané výsledky na určitou skupinu záznamů. Po výběru konkrétní fasety se provede zpřesnění výsledků a faseta z nabídky zmizí. Uživatel se k ní však v případě potřeby může vrátit pomocí drobečkové navigace. Pokud je faset velké množství a hrozí, že uživatel bude muset dlouho rolovat po stránce, je možné zobrazování faset upravit tak, že se zobrazuje pouze stručný přehled jejich názvů (možnost "Collapsed all") a pokud faseta uživatele zaujme, může si ji kliknutím na název otevřít. Fasety jsou tvořeny ze strukturovaných polí záznamu (Author, Format, Language), podle místa uložení (Library) či dostupnosti dokumentu (Availability) a také podle třídění Kongresové knihovny. Fasety je rovněž možné napojit na databázi autorit. Endeca podporuje řazení vyhledaných záznamů podle různých kritérií, např. relevance, roku vydání (vzestupně i sestupně), abecedně podle názvu a autora, podle signatury a popularity. Při vyhledávání jsme nezaznamenali žádný problém při zadávání slov s diakritikou, ovšem vzhledem k vybraným implementacím v anglicky mluvících zemích, nedokážeme v tomto směru odhadnout chování uvnitř systému např. při tvorbě faset.
Systém Endeca zatím nevyužívá mnoho knihoven (zjištěno 6 instalací), jeho aplikace lze nalézt spíše u komerčních subjektů (např. Home Depot nebo WalMart), které potřebují nástroj pro zpřehlednění a organizaci dat na svých webových stránkách tak, aby zákazník vždy našel, co potřebuje.
O průběhu implementace a případných technických požadavcích na vybavení knihovny se nám bohužel z dostupných zdrojů nepodařilo zjistit příliš mnoho informací. Endeca bez problémů komunikuje s běžnými prohlížeči jako MSIE nebo Mozilla Firefox, z jedné aplikace jsme také zjistili, že dokáže spolupracovat i s knihovnickým systémem Aleph, který je v České republice hojně rozšířen.
Dodavatel zajišťuje podporu při instalaci systému a jeho testování. Endeca umožňuje knihovnám také podrobné monitorování využívání systému pomocí statistického modulu "SATELITE = Statistical Analysis Toolset for Endeca, Libraries and Information Technology Environment". Modul sleduje například nejčastěji zadávané termíny, nejvyužívanější fasety, počet "neúspěšných" dotazů zadaných s překlepem nebo chybou apod. Přehled statistických výstupů, které Endeca zpracovává, si zájemci mohou prohlédnout na stránkách University of West Florida Libraries (http://library.uwf.edu/satelite/).
SirsiDynix ohlásil Enterprise v červnu 2008 jako vyhledávácí nástroj nové generace, který pracuje s fasetami. Pro uživatele katalogů společnosti SirsiDynix měl být dostupný ve 3.čtvrtletí roku 2008. Verze 2.0 byla uvolněna v lednu 2009 a dále probíhá vývoj Enterprise 3.0. Vedle Enterprise nabízí SirsiDynix i automatizované knihovní systémy Symphony, Unicorn a EPS/Rooms jako další nástroje pro tvorbu portálů a kvalitní vyhledávání.
Během analýzy prováděné koncem roku 2008 se nám nepodařilo nalézt žádnou knihovnu, která by již své zdroje v Enterprise zveřejnila. Velkou část informací převážně technického charakteru jsme přebrali z korespondence a z materiálů firmy SirsiDynix, bohužel, ve využitých dokumentech není přímo specifikováno, ke které verzi Enterprise se data vztahují. Během posledních měsíců byl Enterprise zpřístupněn v několika amerických veřejných knihovnách, dříve získané údaje jsme nyní tedy mohli doplnit i o analýzu uživatelského rozhraní systému a popis reálně nabízených funkcí.
Souběžně se získáváním údajů o Enterprise jsme prováděli koncem roku 2008 i analýzu dalšího produktu firmySirsiDynix,systémuEPS/Rooms.StejnějakoEnterpriseiEPS/Rooms je schopen integrovat v jednom rozhraní více zdrojů, ať jde o katalogy, licencované zdroje nebo volně dostupný internet. Při vyhledávání EPS/Rooms nabízí zvláště pro katalogy široké možnosti formulace dotazu, záznamy jsou obohaceny o doplňující informace, nicméně např. grafické řešení systému není z pohledu současných trendů příliš přívětivé. Vzhledem k tomu, že Enterprise odpovídá, alespoň podle materiálů producenta, představám a požadavkům katalogů nové generace více než systém EPS/Rooms, rozhodli jsme dát v tomto textu přednost systému Enterprise. Veškeré informace související s analýzou EPS/Rooms jsou k dispozici ve formě tabulek na informačním portálu JIB.
Analyzované instalace systému Enterprise:
Wells County Public Library – knihovna využívá Enterprise několik měsíců. V současné době je možné pracovat jak s původním katalogem (tzv. e-Library), tak vyhledávat v systému Enterprise (tzv. enhanced searching). Knihovna se chystá na beta testování Enterprise 3, od této verze očekává doplnění funkcí, které zatím v současné verzi uživatelé postrádají.
Cromaine Library – Enterprise byl v knihovně spuštěn 21.3.2009, kromě informací
z katalogu jsou v Enterprise pomocí funkce Library Favorities indexovány i některé regionální www stránky. Knihovna souběžně uživatelům zpřístupňuje i původní katalog (ILS Horizon, SirsiDynix), v příštím roce by však měl být katalog převeden do systému Symphony, který je s Enterprise kompatibilnější. Cromaine Library plánuje zpřístupnit v Enterprise i licencované zdroje a službu ChiliFresh pro přidávání uživatelských recenzí k jednotlivým titulům, zapojení zmíněných funkcí je však závislé na implementaci nové verze Enterprise, která by měla tyto služby podporovat.
V některých částech analýzy je možné pozorovat poměrně velké rozdíly mezi teoretickými předpoklady Enterprise a živými instalacemi systému. Případné odchylky jsou v textu vždy zmíněny. Jak jsme již výše uvedli, z materiálů SirsiDynix zcela nevyplývá, od jaké verze Enterprise jsou popisované funkce standardní součástí systému. S největší pravděpodobností jde často o vlastnosti plánované pro verzi 3.0 (knihovny nyní zřejmě využívají verzi 2.0), velkou roli při implementaci nejspíše hraje i využívaný ILS.
a) Vzhled uživatelského rozhraní
Rozhraní Enterprise je z pohledu uživatele jednoduché a "čisté". Svým pojetím vychází z grafiky již využívané v jiných ILS firmy SirsiDynix(např.katalogeLibraryprovozovanýknihovnou Wells County Public Library). Tato podobnost může dle našeho názoru uživatele do jisté míry mást, zvlášť s ohledem na fakt, že Enterprise, který je prezentovaný jako nový, pokročilejší produkt, nabízí v současné době ve výsledku zatím méně funkcí než stávající katalogy vybraných knihoven. Kladem jednoduchého designu je, že v Enterprise uživatel nemůže v žádném případě "zabloudit". Vyhledávací pole je umístěno do vrchní části stránky, ve sloupci po pravé straně se zobrazují fasety a výsledkům dotazu je věnována levá část obrazovky. Jednotlivé druhy dokumentů jsou pro přehlednější orientaci označeny návodnými ikonami, přímo ve výsledku vyhledávání se mohou zobrazovat i náhledy obálek. Rozvržení obrazovky je obdobné i při prohlížení podrobných záznamů, jen fasety jsou vystřídány zvětšeným náhledem obálky a nabídkou odkazů na doplňkové informace (souhrn, různé recenze, obsahy). Kliknutím na předmětová hesla nebo jméno autora je možné jednoduše zadat další dotaz. Systém není zatím vybavený nápovědou, ani na stránkách dotyčných knihoven jsme nenašli žádné tipy pro ovládání Enterprise. Přes jednoduchost práce se systémem bychom však v některých fázích drobnou nápovědu uvítali, např. při pochybnostech, zda Enterprise podporuje zadávání dotazu s operátory či znaky pro rozšiřování. Podle dostupných informací Enterprise odpovídá i požadavkům na tvorbu webu pro handicapované. Zatím v systému chybí jeden z prvků Webu 2.0, a to možnost přidávat k záznamům různá hodnocení, tagy a uživatelské komentáře. Tato funkce je plánována pro Enterprise 3.0.
b) Výběr zdrojů
Testované aplikace Enterprise prohledávají pouze jeden zdroj, a to katalog knihovny. Materiály SirsiDynix nezmiňují, že by systém obsahoval nástroje pro identifikaci zapojených zdrojů či pro jejich popis. Stejně tak jsme nenalezli informaci, jak a zda vůbec si uživatelé budou v Enterprise vybírat zdroje, které chtějí přednostně prohledávat, a jestli bude v Enterprise existovat limit pro počet souběžně prohledávaných zdrojů.
c) Zadání dotazu a vyhledávání
Jak jsme již uvedli, současné aplikace systému podle našeho zjištění pracují až na drobné výjimky pouze s daty z katalogu knihovny. Obdobně jako další systémy nové generace by však i Enterprise měl být schopen prohledávat paralelně více zdrojů. Vyhledávání v Enterprise je velmi jednoduché. Pro zapsání hledaných termínů nabízí systém jedno "univerzální" vyhledávací pole bez možnosti dotaz více zpřesnit, na kterou jsme zvyklí ze současných katalogů. Toto vyhledávací pole je i se zadaným dotazem stabilní součástí rozhraní, můžeme tak kdykoliv do pole doplnit další slovo a výsledky hledání dále upravit. Uživatelům, kteří by chtěli v Enterprise zadat složitější dotaz, zatím systém nenabízí žádnou formu pokročilého vyhledávání a nenajdeme zde ani rejstříky pro listování databází. Veškeré zpřesňování, respektive filtrování výsledkůd otazu je tak,kromě zmíněné možnosti doplnit další slova do vyhledávacího pole, založeno pouze na používání faset. Tímto způsobem lze např. filtrovat podle jazyka, roku vydání nebo typu dokumentu.
Více zadaných slov systém automaticky spojuje operátorem AND, nezdá se však, že by při formulaci dotazu Enterprise podporoval užívání dalších logických nebo proximitních operátorů. Zcela jasné není ani užívání zástupných znaků. Enterprise disponuje technologií Fuzzy Logic, která umožňuje vyhledat relevantní záznamy i v případě, že uživatel zadal dotaz s jednoduchými překlepy nebo záměnami v předponách a příponách. Bohužel v současných instalacích možnosti Enterprise pro formulaci dotazu zaostávají za nástroji nabízenými v rozhraních originálních katalogů. Systém Enterprise obsahuje dva nástroje typu našeptávač. Při zápisu dotazu do vyhledávacího pole může systém dynamicky navrhovat vhodné formulace, druhou možností je funkce "Did You Mean", která využívá aktuální termíny z katalogu.
d) Zobrazení záznamů
Analyzované aplikace Enterprise v současné době prohledávají pouze katalogy knihoven. Z tohoto důvodu se nám bohužel nepodařilo zjistit, jakým způsobem jsou zobrazovány výsledky z různých zdrojů, případně zda probíhá deduplikace nalezených záznamů. V materiálech SirsiDynix je pouze uvedeno, že informace získané ze sklízených zdrojů jsou prezentovány jako jeden celek. Zatím se nezdá, že by Enterprise využíval při zobrazování záznamů metodu FRBR. Systém je schopen pracovat se strukturovanými informacemi ve formátech UNIMARC, MARC21, Dublin Core, dokáže však využívat i nestrukturovaná data. Možnost vytvoření vlastních pravidel konverze dokumenty Sirsi Dynix nezmiňují. U záznamů se nijak neliší množství zobrazených informací a jejich kvalita v Enterprise a původním rozhraní, je však nutné znovu zdůraznit, že zatím Enterprise obsahuje pouze záznamy přebírané z katalogů.
e) Práce s výsledky a navazující služby
Díky spolupráci Enterprise a ILS knihovny by uživatelé měli mít přístup ke svým kontům i v rozhraní Enterprise, tzn. že si mohou v tomto prostředí zadávat objednávky, kontrolovat své výpůjčky, finanční operace atd.ProověřováníčtenářůjevyužívánLDAP,ActiveDirectory server, Shibboleth nebo jiný způsob respektující standard SAML. V analyzovaných aplikacích Enterprise jsme možnost přihlásit se do uživatelského konta zatím nenalezli, veškeré operace související s výpůjčkami provádějí uživatelé v původním katalogu. Nástroje pro další práci s výsledky dotazu v Enterprise nejsou příliš bohaté. Označené záznamy je možné odeslat na e-mailovou adresu nebo upravit do formátu vhodného pro tisk a následně vytisknout. Další doplňkovou službou je RSS kanál obsahující výsledky vyhledávání. Jiné formy ukládání záznamů, např. ve schránce nebo export do programů pro správu citací, Enterprise nenabízí. V systému chybí i možnost vrátit se zpět k dříve provedeným dotazům, součástí rozhraní Enterprise není odkaz na službu typu Ptejte se knihovny nebo jinou referenční službu knihovny.
Enterprise je podle materiálů SirsiDynix schopen spolupracovat s různými typy zdrojů, integruje tedy katalogy knihoven, digitální archivy, metavyhledávače atd. Pro kontrolu přístupu k licencovaným zdrojům využívá různé metody nastavení uživatelských práv, zmiňovaný v této souvislosti sice není systém HAN, se kterým pracuje NK ČR, ale je možné použít například EZproxy nebo ověřování pomocí IP adres. Systém Enterprise prochází databáze ILS a záznamy indexuje, aktualizace rejstříků se provádí každý den, probíhat však mohou v případě potřeby i častěji. Data z repozitářů kompatibilních s OAI-PHM získává Enterprise sklízením, další zdroje pak zapojuje prostřednictvím federativních vyhledávačů (Serials Solutions 360 Search, Webfeat, MuseGlobal, MetaLib). Součástí systému je také robot, který může procházet internet a indexovat soubory v různých formátech (html, xhtml, pdf, rtf, MS Office). S těmito skutečnostmi souvisí fakt,že Enterprise podporuje různé standardy (OAI-PHM, Z39.50 search, present, SRU/W a SRU search, present).
Pro poskytování přidaných služeb upřednostňuje SirsiDynix nástroj 360 Link (Serials Solutions), nicméně je možné zapojit i další nástroje podporující OpenURL, tedy i SFX. Enterprise je kompatibilní s ILS SirsiDynix, z dostupných materiálů však vyplývá, že spolupracuje i s knihovními systémy dalších producentů. Jak jsme se již dříve zmínili, systém by měl být schopen nabídnout propojení na bázi uživatelů a s tím související služby, např. objednání nalezených dokumentů nebo zadání požadavku na kopie. Recenze, hodnocení, obálky, obsahy atd. pro obohacení a rozšíření záznamů jsou v Enterprise získávány od různých partnerů, patří mezi ně ChiliFresh.com, Nielsen BookData nebo SyndeticSolution, využít je možné i další zdroje.
U tohoto okruhu otázek testované aplikace nabízejí pouze malou část z výše popsaných funkcí. Ani jedna knihovna zatím do Enterprise nezapojila své licencované zdroje či jiné databáze.
Tato možnost se pravděpodobně vztahuje až na Enterprise 3.0, mezi jejímiž vývojovými cíli je "federated search". Absenci integrace digitálních knihoven do Enterprise by také bylo možné vysvětlit tím, že knihovny nevytvářejí žádný zdroj tohoto charakteru. V rozhraní Enterprise jsme u záznamů nenalezli ani přidané služby, ať již poskytované pomocí 360 Link nebo jiným nástrojem. Záznamy dokumentů obsahují signatury, pro aktuální informace o dostupnosti se používá odkaz "Check Availability/Request Item", který vede k záznamu dokumentu v původním katalogu. Originální katalog slouží i pro objednání dokumentu a další práci se záznamem.
Stejně jako v ostatních katalozích nové generace i Enterprise poskytuje uživateli
prostřednictvím faset řadu možností pro zpřesňování a rozčleňování výsledků dotazu. Standardně v systému nalezneme fasety Author, Library (všechny vybrané knihovny mají své pobočky), Format, Publication Date, Language a Material Type. Z každé skupiny faset lze použít jednu a s její pomocí výsledky postupně filtrovat.Použité fasety se přehledně zobrazují v záhlaví, v případě potřeby je uživatel může odstranit všechny najednou nebo jednotlivě bez ohledu na pořadí, v němž byly původně ve výsledcích dotazu použity. Obdobné je využití fasety Subject, která zobrazuje předmětová hesla přebíraná z věcného popisu v nalezených záznamech. Uvnitř fasety Subject jsou předmětová hesla pouze mechanicky řazena, a to sestupně podle počtu záznamů příslušných k danému heslu. Otázkou je, zda by uživatelé u fasety Subject spíše nedali přednost seskupování hesel vybraných ze záznamů do tematických celků.
Fasety jsou dynamicky generovány vyhledávacím nástrojem Globalbrain, metadatové fasety využívají bibliografické a holdingové informace.V dostupných materiálech se nám nepodařilo zjistit, zda systém Enterprise knihovnám dovoluje vytvářet vlastní fasety, případně ovlivňovat formu jejich zobrazení, spíše se však domníváme, že to není možné. Nalezené záznamy jsou s pomocí speciálního algoritmu automaticky řazeny podle relevance, součástí záznamů je pole Relevance, které uvádí její míru určenou systémem. Další možnosti pro setřídění výsledků jsme v analyzovaných instalacích Enterprise nevypozorovali. Stejně tak jsme nenalezli jasnou odpověď na otázku, zda je Enterprise připraven na češtinu. Enterprise by měl být schopen přizpůsobit se diakritice, správně rozpoznat znaky doplněné o diakritiku. Systém je vybaven funkcí Diacritics Smart, která je schopná se s pomocí Fuzzy logic vyrovnat s diakritickými znaménky v záznamech a zobrazit nalezené výsledky bez ohledu na to, zda diakritiku obsahují.
V porovnání s ostatními analyzovanými systémy začal vývoj Enterprise o něco později, z tohoto důvodu se nám systém zatím nezdá zcela uživatelsky prověřený. Verze 1.0 byla podle informace z prosince 2008 beta testována 11 zákazníky s ILS firmy SirsiDynix (Horizont, Symphony, Unicorn). Uvolnění Enterprise 2.0 ohlásil SirsiDynix 15.1.2009, instalace systému v knihovnách tak byly zveřejněny až v průběhu letošních prvních měsíců. Vývoj dále probíhá, verze 3.0 byl měla být uvolněna pravděpodobně na podzim 2009, některé knihovny se již chystají na její beta testování.
Bližší informace o technických požadavcích Enterprise jsme nenalezli, podle článku M. Breedinga bude systém poskytován pouze formou SaaS (Software as a Service), zatím Enterprise zakoupilo 16 zákazníků. Systém je schopen podporovat rozhraní ve více jazycích, a to včetně těch, které nepoužívají latinku (arabština, čínština). Implementován je také Unicode a kódování UTF-8. Pro práci s Enterprise lze využít různé prohlížeče od MSIE, přes Netscape, Mozillu Firefox až po Safari.
Informace o podpoře producenta při úvodních školeních či helpdesku a souvisejících finančních nákladech nejsou běžně uváděny. Nejbližší zastoupení SirsiDynix je v Německu, předpokládáme tedy, že podpora by pravděpodobně nebyla dostupná v českém jazyce a nejspíše by probíhala formou e-mailu, telefonické nebo online konzultace. Na druhé straně je otázkou, do jaké míry by zpřístupňování Enterprise v modelu SaaS vyžadovalo nutnost konzultací s technickými pracovníky SirsiDynix. V pilotní fázi je u Enterprise limit 500 souběžně pracujících uživatelů, při běžném provozu se pak tento limit rozšiřuje na 1000-2000. Běžně se Enterprise implementuje na katalogy společnosti SirsiDynix, podle dostupných údajů by však měl být schopen spolupracovat s libovolným knihovním systémem. Součástí Enterprise jsou i funkce pro zpracování statistik, metodika jejich zpracování není specifikována.
Společnost ExLibris Group je předním poskytovatelem programových řešení nabízejících vyhledávací služby, správu i zprostředkování všech typů dokumentů (tištěných, elektronických i digitálních). Produkty Ex Libris využívají tisíce institucí ve více než 70 zemích světa, zejména akademické, odborné a národní knihovny. Kromě systému Primo nabízí společnost ještě další nástroje, např. knihovnické systémy Aleph a Voyager, MetaLib pro paralelní vyhledávání, SFX pro přidané služby, Verde pro správu elektronických zdrojů, DigiTool pro správu digitálních objektů.
Firma ExLibris představila tento systém poprvé v roce 2007 (verze 1.0 byla zveřejněna v květnu 2007). Tento produkt je vyvíjen ve spolupráci s knihovnami v USA, Dánsku a Německu, v současné době je přibližně 10 funkčních implementaci, které se v podstatě od sebe vzájemně příliš neliší, rozdílné je jen množství využívaných zdrojů. Systém Primo je prvotřídní portál, který zprostředkovává uživatelům z jednoho místa vše, co požadují, od vyhledávání až k lokalizaci a získání konkrétního dokumentu nebo informace, kde je možné dokument získat, za využití funkcí Web 2.0.
Pro testování jsme vybrali následující instituce:
Vanderbilt University Library – nabízí vyhledávání v knihách a dalších druzích dokumentů pomocí jedné záložky a v článcích pomocí druhé. Bohužel systém neumožňuje kombinaci těchto dvou záložek. Součástí stránky je i odkaz na službu Ask us.
REX – the Royal Library and Copenhagen University Library Service (CULIS) – přístup ke zdrojům dvou knihoven, jejichž sbírky a služby jsou z hlediska uživatelů propojeny. Rozhraní umožňuje přístup ke všem kolekcím a speciálním sbírkám s možností si předem vybrat jeden konkrétní zdroj. Portál také nabízí vyhledávání na webové stránce instituce, a to jako samostatnou složku pro výběr. Hned na úvodní stránce je také k dispozici formulář pro zpětnou vazbu (Tell us what you think), kde jsou uživatelé vybízeni k zadání komentářů k novému vyhledávacímu rozhraní.
Iowa State University – umožňuje vyhledávání ve všech dokumentech, včetně článků, ve kterých nabízí vyhledávání buď samostatně, nebo v kombinaci s ostatními druhy dokumentů (kombinace i pro jednotlivé obory). Na úvodní stránce jsou k dispozici odkazy na službu Ask a library nebo How do I?, které zajišťují standardní uživatelskou podporu.
a) Vzhled uživatelského rozhraní
Grafika systému působí v porovnání s ostatními testovanými systémy o něco těžkopádněji, z našeho pohledu kopíruje v mnohém grafiku užívanou v systému MetaLib.Všechny testované knihovny mají rozhraní přizpůsobené svým potřebám, i když je samozřejmě na první pohled patrné, že se jedná o tento konkrétní systém. Systém splňuje požadavek na jednoduchost a srozumitelnost s možností užití předvolených parametrů nebo vlastní specifikace výběru, všechny možnosti jsou jasně a pochopitelně nazvány (při testování jsme využívali anglické rozhraní vybraných portálů). Úvodní obrazovka nabízí pouze jedno pole pro zadání dotazu, vychází z předpokladu, že uživatelé preferují vyhledávání podobné jako v běžných internetových vyhledávačích. Systém nabízí kontextovou nápovědu, která umožní uživateli v kterékoliv části využít systém podle standardních možností. Systém splňuje požadavky na parametry pro zrakově znevýhodněné uživatele, pro plný přístup lze využít i přímou registraci pro neregistrované uživatele (dánské rozhraní REX).
b) Výběr zdrojů
Primo využívá všech možností a výhod, které mu dávají další systémová řešení, která s portálem spolupracují, jedná se především z pohledu tohoto okruhu o MetaLib. Systém jako jeden z mála testovaných systémů nabízí federativní (paralelní) vyhledávání v různých zdrojích (právě na bázi MetaLib), ovšem bez možností výběru zdrojů pomocí zadání kriterií. Systém Primo umožňuje uživateli zvolit si konkrétní sbírku, ale tímto výběrem uživatel ztrácí variantu nalezení relevantního dokumentu v jiné sbírce, na druhou stranu má uživatel možnost využít pro jedno vyhledávání všechny zdroje dostupné prostřednictvím portálu. Systém nenabízí žádný nástroj pro popis zdrojů (tak jak je známe z JIB), důvodem je jistě snaha producenta co nejvíce zjednodušit práci s portálem a fakt, že pro uživatele není rozhodující, ve kterém zdroji se hledaný dokument nachází.
c) Zadání dotazu a vyhledávání
U analyzovaného systému jsme zkoumali různé parametry vyhledávání, srovnávali jsme vyhledávací vlastnosti zapojených zdrojů v rámci testovaného systému s možnostmi hledání v originálním rozhraní. Při vyhledávání v klasických OPAC jsou uživatelé zvyklí používat především zadání přímo do vyhledávacího pole, případně použít rejstřík. Standardní možnosti pro zadání dotazu většinou umožňují i analyzované implementace systému Primo, přístup pomocí rejstříku není nabízen, tento drobný nedostatek nahrazují různá nastavení, která v případě neznalosti konkrétního termínu pomáhají s upřesněním. Zadání hledaného výrazu je možné do jednoho pole, které má různé možnosti omezení (hledat ve všech polích záznamu, v poli autor, název, předmět nebo také hledat pomocí slov nebo fráze). Standardní součástí všech systémů je pokročilé hledání, systém rozšiřuje původní pole o další položky (např. datum vytvoření, ISBN, předmětová klasifikace–Deweyho desetinné třídění) a další omezení jako je jazyk dokumentu, druh dokumentu, rok vydání a konkrétní sbírka. Při formulaci dotazu je u všech testovaných knihoven také možné využít logické operátory, bohužel systém nenabízí proximitní operátory. Mezi základní vybavení systému patří také možnost využít nahrazení znaku, Primo užívá "?" pro nahrazení znaku uvnitř slova a "*" pro pravostranné rozšiřování.
V případech, kdy si nejsme zcela jisti správným zápisem hledaného výrazu, nám velmi pomohou nástroje pro kontrolu pravopisu nabízené ve všech analyzovaných knihovnách, neboť základním cílem analyzovaného portálu je, aby vyhledávání vždy vedlo
k nalezení relevantních informací. I když systém Primo nepodporuje omezení vyhledaných záznamů pomocí dalšího pole, rozšiřuje možnosti dotazu pomocí různých variant alternativních klíčových slov, které mohou být vytvářeny na základě autoritních databází (toto propojení je velkým kladem systému Primo), případně přebírány přímo z nalezených záznamů (fasety, klastry). Sledované parametry jsou ve všech analyzovaných knihovnách na stejné úrovni, která je z pohledu uživatele hodnocena jako vynikající, umožňující nalezení potřebných dokumentů pro všechny typy dotazů.
d) Zobrazení záznamů
Z hlediska zobrazení nalezených záznamů nabízí systém Primo standardní možnosti, které jsou podepřeny paralelním vyhledáváním a množstvím zapojených zdrojů. Dalším zřejmým důsledkem paralelního vyhledávání v rámci jednoho rozhraní jsou velké objemy nalezených záznamů, pro snadnější orientaci systém nabízí ikonky k různým druhům dokumentů. Jako jeden z mála analyzovaných systémů nabízí Primo slučování výsledků (odstraňování duplicit), a to jak v celé množině nalezených záznamů, tak i při zobrazení pomocí jednotlivých zdrojů, pro toto rozdělení systém využívá fasety. I když deduplikace z hlediska koncových uživatelů nestojí v popředí zájmu (zdroj OCLC studie – viz dále), je to výjimečný nástroj z pohledu pracovníků knihoven a dalších informačních specialistů, kteří se zabývají zpracováním a zpřístupněním dokumentů. Výhodou systému Primo oproti MetaLib (JIB a oborové brány) je skutečnost, že jsou nalezené výsledky stahovány (a tady je možné je využívat) jako celek, nikoliv postupně v určitých dávkách. Zásadní výhodou katalogů nové generace jsou i nové způsoby prezentace dat z katalogů a dalších informačních zdrojů pomocí metody FRBR. Dále je nutné při paralelním vyhledávání, respektive při prezentaci nalezených záznamů, zohlednit fakt, že vedle formátů UNIMARC, MARC21 jsou v prohledávaných databázích využívány i jiné formáty (MAB, Dublin Core, SUTRS, další je možné nakonfigurovat). Systém Primo je schopen pracovat s dalšími metadatovými formáty tak, že zobrazení záznamu v jednotném rozhraní plnohodnotně a kvalitou odpovídá zobrazení v nativním rozhraní, tuto skutečnost potvrdily všechny testované katalogy.
e) Práce s výsledky a navazující služby
Systém Primo splňuje v této oblasti všechna zadaná kriteria, a to především ta, která jsou z pohledu uživatelů důležitá pro kvalitní práci s nalezenými záznamy. Systém nabízí pro komfortní práci nastavení vlastního prostoru pro koncového uživatele, který si ho může pro svoji práci částečně upravit, zároveň je možné toto vlastní nastavení propojit s bází uživatelů knihovny a zajistit tak z jednoho místa komfortní přístup ke všem důležitým informacím z pohledu koncového uživatele. Systém podporuje různé způsoby autentizace do čtenářských kont (jejichž prostřednictvím mohou uživatelé po přihlášení sledovat své výpůjčky, rezervace apod.) a licencovaných databází. Kromě standardního posílání záznamů na e-mail nebo přímého vytištění systém neumožňuje z těchto "vžitých" operací uložení na vlastní počítač. Dále systém využívá možnosti exportu prostřednictvím některého z nabízených citačních standardů a využít i systémy pro správu citací (nejčastěji RefWorks nebo EndNote), i když se nepodařilo zjistit, které konkrétní standardy jsou využívány, neboť každý z testovaných systémů vyžadoval přihlášení pro tuto činnost. Primo podporuje také možnost zobrazení předchozích zadaných dotazů, na kterou jsme zvyklí z klasických OPAC, a to v rámci e-Shelf. V případě, že si uživatelé nevědí rady, je do systému integrována referenční služba typu Ptejte se knihovny, a to převážně formou odkazu, pro další rozvoj a úpravy portálu podle potřeb uživatelů je nabízena většinou formou formuláře možnost zpětné vazby. Uživatelé systému mohou volně využít i RSS a po přihlášení službu Alerts, která je obdobou klasické knihovní služby SDI, dále po přihlášení mohou uživatelé vytvářet tagy a přidávat recenze či komentáře k jednotlivým dokumentům, tedy jsou nabízeny možnosti související s pojetím Web 2.0.
Systém Primo jako jediný z testovaných systémů umožňoval v době testování zapojení všech typů databází na základě federativního vyhledávání, ale nabízí i zapojení databází pomocí OAI, Z39.50, SRU atd., tedy různé možnosti, které vedou k přístupu k různým zdrojům knihoven, kdy se nejedná jen o dokumenty dostupné v knihovnách, ale o všechny typy zdrojů, které knihovna zprostředkovává svým koncovým uživatelům (bibliografické, plnotextové, autoritní,e-knihy).Vzhledemktomu,žesystémjevyvíjenstejným poskytovatelem, jehož další knihovní aplikace jsou užívané v ČR, je zřejmé, že jednoduché a standardní zapojení různých zdrojů dostupných v ČR bude velkým kladem a že bude implementace probíhat bez jakýchkoliv větších problémů. Stejně jako v jiných systémech jsou metadata obohacena z jiných aplikací volně dostupných nebo i komerčních (např. Amazon, Google Books), tedy vyhledané záznamy v analyzovaných katalozích nezobrazují pouze textové informace, ale jsou obohaceny o náhledy obálek dokumentů, obsah, rozpis kapitol, recenze aj. Prioritou systému není jen vyhledávání, ale i získání/dodání požadovaného dokumentu, systém získává potřebné informace z ILS (například status výpůjčky, umístění titulu, informace o přístupu), po autentizaci nabízí i možnost objednání atd., vždy úroveň těchto služeb závisí na nastavení ILS konkrétní knihovny. Integrovanou součástí systému je i SFX, tak jak ho známe z JIB a s jehož pomocí jsou uživateli poskytovány další relevantní služby ke konkrétnímu dokumentu.
Systém Primo nabízí koncovým uživatelům i tematickou specifikaci, a to ve formě faseti klastrů. Fasety jsou vytvářeny na základě předem definovaných polí (např.autor,název, systém nabízí 10 předdefinovaných polí, navíc jich několik může definovat sama koncová knihovna), klastry se vytvářejí na základě textu obsaženého ve vyhledaných záznamech, který není předem definován, případně využívají různé slovníky a tezaury,systém Primo jako jeden z mála z testovaných systémů umožňuje napojení na tento druh databází. Z pohledu uživatele je také velmi důležité třídění nalezených záznamů podle různých kritérií, mezi nejdůležitější patří relevance, dále systém nabízí třídění i podle data vložení, popularity, autora. V rámci implementace mohou knihovny do určité míry formálně či po grafické stránce ovlivnit vytváření faseta klastrů.Uživatel,kterýbyneměl zájem tyto prvky katalogu využívat, však pravděpodobně nemůže v rámci svého individuálního nastavení v systému zakázat jejich zobrazování (aspoň tato informace nebyla nikde obsažena). Systém aktivuje nabídku alternativních cest pro vyhledávání, což uživatelé ocení především v případě záporného výsledku.
Jak jsme již uvedli dříve, systém Primo je prvotřídní komerční systém, na jehož vývoji se podílely i knihovny. Vzhledem k rozsáhlým zkušenostem producenta v oblasti knihovních aplikací (Aleph, MetaLib, SFX a další) je zcela zřejmé, že byl systém vyvíjen jako aplikace pro velké instituce, které chtějí svým uživatelům zpřístupnit veškeré své zdroje pohodlným způsobem. Tomu také odpovídá podpora producenta při instalaci a testování systému, podle dat dostupných volně na internetu není tato podpora v češtině (vzhledem k zastoupení firmy ExLibris v ČR se tato skutečnost nemusí projevit jako zásadní problém). Podle dostupných informací je v současné době připravována demo verze pro Českou republiku, kde lze předpokládat, že bude lokalizováno uživatelské rozhraní a že budou integrovány slovníky pro podporu českého jazyka. Vzhledem k tomu, že systém Primo je komerční produkt, nejsou volně dostupné žádné informace vztahující se k implementaci a podpoře při testování a běžného provozu, i když se můžeme domnívat, že budou na stejné úrovni jako podpora dalších produktů této firmy, které jsou již v ČR využívány. Systém nabízí i modul statistik, i když formát nebylo možné zjistit, lze opět vyvodit, že jsou nabízeny statistiky podle běžně užívaných standardů.
VuFind je portál knihovních zdrojů, který byl vyvinut v USA (Villanova University). První instalace proběhla v roce 2007, v současné době má systém kolem 10 instalací, které buď již "běží” v plném nebo testovacím provozu, další knihovny systém analyzují z hlediska svých potřeb. Hlavním cílem VuFind je umožnit uživatelům vyhledávání ve všech zdrojích knihovny a nabídnout i další doplňkové služby, to vše v jednoduchém, přehledném a pro uživatele návodném rozhraní. Systém je kompletně modulární, je na rozhodnutí každé knihovny, který modul použije. Vzhledem k tomu, že je budovaný jako open source, může knihovna systém zcela přizpůsobit svým potřebám, včetně vývoje nového modulu. Systém VuFind si od svého uvedení našel své příznivce v různých částech světa (Austrálie, USA, Evropa).
Pro naši analýzu jsme vybrali následující instituce:
National Library of Australia – rozhraní pro přístup k vlastním zdrojům knihovny (knihy, časopisy, digitální objekty, atd.). Rozhraní rozlišuje vyhledávání podle typů dokumentů, nelze vyhledávat v konkrétních bázích. V pozadí rozhraní je užíván knihovní systém Voyager, všechny záznamy dokumentů jsou v tomto systému k dispozici (jednotný formát, úroveň popisu, atd.).
Georgia Tech University – rozhraní pro přístup k OPAC knihovny, užívaný knihovní systém Voyager. Pro hledání článků je nabízen v systému odkaz na jiné rozhraní. Z výše uvedeného vyplývá, že systém v této knihovně slouží především k podpoře a rozvoji funkcí klasického ILS.
Villanova University – Falvey Memorial Library – přístup k dokumentům (knihy, časopisy, audio/video materiály, elektronické zdroje…), zdrojům a službám knihovny, mimo OPAC je možné zadat vyhledávání v licencovaných databázích, digitální knihovně, www stránkách, bibliografii nebo referenční službě, jednotlivě v každém zdroji zvlášť.Užívanýknihovní systém Voyager.
a) Vzhled uživatelského rozhraní
Grafika systému působí ve všech knihovnách velmi jednoduše, přehledně a pro uživatele návodně, i když vzhledem k tomu, že každá knihovna má systém implementován v rámci svého "institucionálního grafického pojetí", nelze přesně říci,cojevýsledkemvlastní implementace knihoven a co standardní součástí systému. Systém nabízí standardní pomůcky pro vyhledávání a umožňuje zpětnou vazbu, řešení je v knihovnách různé, včetně zahrnutí služby typu Ask a library, lze vyvodit závěr, že tyto otázky jsou úzce spjaty a závisí na možnostech a schopnostech pracovníků konkrétní instituce. Na úvodní obrazovce je pro uživatele k dispozici jednořádkové vyhledávání s možností dalšího omezení, provedení ve všech analyzovaných knihovnách vycházelo z potřeb konkrétní instituce. Bohužel se nám nepodařilo zjistit, jak tento systém odpovídá pravidlům a standardům tvorby webu pro handicapované.
b) Výběr zdrojů
Systém VuFind je založen na principu co největšího zjednodušení přístupu k dokumentům pro koncového uživatele. Tvůrci systému vycházeli z předpokladu, že uživatele většinou nezajímá cesta, jak se k hledanému dokumentu dostane (koncový zdroj), ale zajímá ho, v jaké formě knihovna požadovaný dokument vlastní a nabízí a jak je možné ho získat (např. National Library of Australia umožňuje vyhledávání napříč svými zdroji, uživateli nabízí pro upřesnění různé druhy dokumentů – knihy, digitální objekty, mapy, atd.). Z výše uvedených důvodů nejsou v systému žádné nástroje pro výběr a popis zdrojů.
c) Zadání dotazu a vyhledávání
Z již uvedeného vyplývá, že tvůrci a uživatelé systému si jsou vědomi limitů, které má současná verze, především v oblasti federativního vyhledávání (mělo by být v další verzi – release) či standardní podpory Z39.50. Z analýzy vyplynulo, že velmi záleží na přístupu a strategii jednotlivé knihovny (např. National Library of Australia nemá do systému zařazeny licencované zdroje, naproti tomu Villanova Univerzity ano, ale pouze pro samostatné vyhledávání v jednotlivých bázích). Systém nabízí standardní pole pro vyhledávání, včetně pokročilého vyhledávání s možností kombinace až 4 polí a dalšími specifikacemi pro omezení (formát,jazyk,rokvydání).Proúspěšnévyhledáváníjsoupodstatné možnosti, které systém nabízí pro jasnou a přesnou formulaci dotazu (a to i včetně využití přístupových rejstříků), včetně užití logických a proximitních operátorů a užití dalších polí pro zpřesnění po vyhledávání na základě konkrétního dotazu (funkce Search within). Pokud si nejsme jisti správným zápisem hledaného slova nebo přesným zněním termínu, můžeme využít různé nápovědy pro kontrolu pravopisu a nabídku dalších oborově příbuzných dokumentů. Sledované parametry jsou zejména v tomto systému na vysoké úrovni, nabízejí uživatelům (kromě zapojení autoritních databází) všechny možnosti pro co nejefektivnější nalezení relevantních dokumentů. Vyhledávání pomocí VuFind je na stejné úrovni jako v dříve užívaných ILS analyzovaných knihoven.
d) Zobrazení záznamů
Důsledkem vyhledávání v rámci jednoho rozhraní jsou velké objemy nalezených dat, první orientaci v množině záznamů slouží obrazové ikonky k rozlišení jednotlivých druhů dokumentů. Pro komfortní práci s výsledky je velkou výhodou, že jsou všechny nalezené záznamy uživateli prezentovány naráz jako celá množina, se kterou je možné dále pracovat (i dále zpřesňovat pomocí dalšího hledání), výsledky lze řadit podle relevance, data, autora a titulu. Systém VuFind nabízí zobrazení nalezených záznamů jako celku, bez ohledu na zdroj, ze kterého záznam pochází (pokud nejsou databáze rozděleny již přímo v nabídce – Villanova University). Pro rozdělení záznamů podle "původních zdrojů" jsou v analyzovaném systému využívány různé fasety, a to faseta rozdělující dokumenty podle druhu (knihy, články, digitální objekty a další), fasety jsou užívány také jako základní nástroj k dalšímu omezování počtu relevantních záznamů, především se jedná o roky vydání, jazyk atd. Ke katalogům nové generace by měly patřit i nové způsoby prezentace dat z katalogů a dalších informačních zdrojů, a to pomocí metody FRBR, v případě VuFind se uplatňuje "Uniform title", i když je nutné zdůraznit, že vše záleží na úrovni standardizace popisu v té konkrétní knihovně. Nativní rozhraní původního OPAC bylo možné porovnat pouze v National Library of Australia, výsledky vyhledávání byly totožné (vysoká úroveň popisu všech typů dokumentů). Vzhledem k tomu, že pojetí testovaných knihoven z hlediska zapojených zdrojů je velmi odlišné, nelze zcela přesně určit, co je standardní součástí systému a co jsou specifické úpravy konkrétních aplikací, nelze ani přesně zjistit, zda je možné vytvořit vlastní pravidla konverze pro přebírání záznamů z dalších formátů (podle dostupných informací za dodržení standardů lze přebrat i další formáty).
e) Práce s výsledky a navazující služby
Analyzovaný systém v této oblasti splňuje všechna zadaná kriteria, která jsou z pohledu uživatelů důležitá pro kvalitní práci s nalezenými záznamy. Pro VuFind mohou "pracovat" na pozadí různé zdroje, v tomto rozhraní jsou výsledky prezentovány novými způsoby oproti klasickým OPAC. Kromě možnosti standardního posílání záznamů na e-mail nebo jejich vytištění je možné záznamy ve většině systémů exportovat prostřednictvím některého z nabízených citačních standardů (z hlediska užití citačních norem systém nepodporuje ISO standard) nebo využít systémy pro správu citací (nejčastěji RefWorks nebo EndNote). Komfort práce zvyšuje také možnost vytvořit si v rámci systému vlastní prostor (většinou nutné přihlášení), který umožňuje zejména interakci uživatele a katalogu – uživatelé mohou přidávat k vyhledaným dokumentům svá hodnocení, komentáře, tagy nebo recenze (Villanova University). Systém podporuje různé způsoby autentizace do čtenářských kont (jejichž prostřednictvím mohou uživatelé po přihlášení sledovat stav výpůjček, rezervací apod.) a licencovaných databází. VuFind nabízí také možnost zobrazení předchozích zadaných dotazů, na kterou jsme zvyklí z klasických katalogů. V případě, že si uživatelé nevědí rady, je nabízeno do systému integrovat referenční službu typu Ptejte se knihovny, a to převážně formou odkazu, stejně jako je nabízena většinou ve formě formuláře možnost zpětné vazby. Uživatelé systému mohou pro větší komfort využít i RSS.
Rozhraní, která umožňují přístup k různým zdrojům knihovny, jsou z hlediska uživatele prvotním a základním nástrojem neboli vstupní branou ke zdrojům knihovny. Nejde jen o dokumenty dostupné v knihovnách, ale o všechny typy zdrojů, které knihovna zprostředkovává svým uživatelům. Pod jednotné rozhraní VuFind je možné zahrnout všechny druhy databází, ovšem pouze za předpokladu, že jsou zpracovány podle standardů (např. National Library of Australia zpracovává všechny druhy dokumentů pod jedním ILS, podle jednotných standardů) a že vzhledem k chybějícímu federativnímu vyhledávání je možné s nimi pracovat buď jako s jedním zdrojem (National Library of Australia), nebo jako jednotlivými vstupními zdroji (Villanova University), i když podle dostupných informací systém podporuje standardy jako je OAI pro sdílení záznamů s ostatními institucemi prostřednictvím OAI serveru (zdroj prezentace Georgia Tech University). Záznamy vyhledané v analyzovaných katalozích nezobrazují pouze textové informace, ale jsou obohaceny o náhledy obálek dokumentů, obsah, rozpis kapitol, recenze aj., u většiny analyzovaných katalogů z volně dostupných zdrojů (např. Google Books, Amazon.com). Vzhledem k propojení s původními ILS prostřednictvím uživatelských kont umožňují knihovny přímé objednávání dokumentu (a další služby jako např. objednání kopie) a přístup k licencovaným zdrojům, pokud jsou v systému zahrnuty (např. Villanova University), vždy po registraci. Systém zatím nepodporuje tzn. link server, tak jak ho známe z prostředí JIB (SFX), kde by všechny navazující služby mohly být soustředěny na jednom místě (podle dostupných informací se na této integraci pracuje, měla být k dispozici na konci roku 2008).
Systém VuFind nabízí koncovým uživatelům i tematickou specifikaci, i když zatím nemá nástroj na zapojení autoritní báze nebo předmětových tezaurů k rozčlenění výsledků podle témat. Systém nabízí řazení nalezených záznamů podle různých kritérií, z nichž nejdůležitější je relevance (dále autor, název, rok), a využívá fasety k filtrování vyhledaných záznamů podle vybraných parametrů (např. formát dokumentu, rok, autor, jazyk, předmět – předmětové třídění Kongresové knihovny, tematické signatury), které jsou tvořeny z jednotlivých polí nalezených záznamů. Podle dostupných informací nelze
v rámci uživatelského nastavení nabídku faset rozšířit či naopak zrušit, pokud je jako koncový uživatel nechci využívat (např. National Library of Australia nabízí v rámci Feedback i několik otázek k užitečnosti faset, včetně hodnocení jejich využití i pro specifikaci dotazua nalezení relevantních záznamů, ověřeno podle nápovědy a odkazu na stránce). Systém aktivuje nabídku podobných zdrojů (pod názvem "Similar Items", "More Like This"), ale využití klastrů (třídění výsledků podle témat) zatím nepodporuje. Záznamy, které jednotlivé katalogy obsahovaly v českém jazyce, byly zobrazovány správně (stejně jako v polštině), ovšem na základě této skutečnosti nelze přesně odvodit připravenost systému na češtinu jako jazyka autoritní či jiné předmětové báze.
Jak již bylo uvedeno dříve, tento okruh otázek byl prověřován pouze ve spojitosti se službami a uživatelským rozhraním. Obecně se dá říci, že systém VuFind nemá problém s dodržováním standardů pro implementaci zdrojů, pracuje na základě běžných HW a SW platforem, nemá problém se zobrazením rozhraní v běžně užívaných nástrojích – např. MSIE, Mozilla, Opera. Není známa žádná implementace systému v ČR, není k dispozici česká lokalizace, což je jistě limitující faktor, dále je také nutné zdůraznit, že k implementaci systému VuFind jsou nutné programátorské práce (programátorské zázemí instituce nebo placené zadání). I když lze využít podporu v rámci portálu VuFind.org, která je podle dostupných informací zdarma, tvůrci systému vlastní podporu nenabízejí, i když se nezříkají prezentací a dalších forem podpory, nejspíše ovšem za předpokladu placení ze strany koncové instituce. Při praktické analýze jednotlivých katalogů jsme nezjistili žádné problémy s použitím českého jazyka na všechny komponenty systému, které se vztahují k prezentaci záznamů, hesel a odkazů, ovšem vzhledem ke specifičnosti je nutná opatrnost v podpoře jazykové flexe pro češtinu.Modul statistik byl ohlášen pro další vývoj v prezentaci v roce 2007, z dalších příspěvků lze vyvodit, že je již k dispozici a že byl vyvíjen na základě běžně používaných standardů. Podle dostupných informací měl Release 1.0 na konci roku 2008 obsahovat i OAI importer, Authority index, Web-based Administration a další (zdroj prezentace Georgia Tech University).
Analýza jednotlivých systémů ve formě tabulek je dostupná na informačním portálu JIB. Vzhledem k množství získaných dat připravujeme publikaci, která bude kromě popisu jednotlivých systémů obsahovat i tabulky, resp. srovnání systémů ve zkoumaných oblastech, a dále související grafy a obrázky.
Studie, kterou nedávno uveřejnilo OCLC8, uvádí, že uživatelé od online katalogů knihoven očekávají především odkazy na dostupné online texty a další media, více informací k obsahu, vyhledání relevantních záznamů (s jasně zřetelnou relevancí), informace o dostupnosti dokumentů a jednoduché vyhledávání pomocí klíčových slov s možností pokročilého volitelného vyhledávání, především pomocí faset a dalších předmětových tezaurů.
Závěry analýzy OCLC jsou v podstatě totožné s okruhy, které jsme si stanovili jako zásadní z pohledu uživatele katalogů nové generace, lze bez nadsázky napsat, že naše analýza tyto závěry také potvrdila, a to i v tom smyslu, že nejen tato očekávání se snaží výše jmenované systémy naplnit a rozvinout v jednoduché intuitivní rozhraní, které uživatelům umožní odkudkoliv, v krátkém čase a v kteroukoliv dobu získat materiál, který požadují. Nejde tedy jen o rozhraní a možnosti vyhledávání, za všemi výše uvedenými okruhy se skrývá i standardizovaný popis, ať jmenný nebo věcný, na jehož základě jsou všechny kvalitativně nové služby a také očekávání uživatelů postaveny.
I když se potřeby koncových uživatelů a pracovníků knihoven podle této studie zcela neztotožňují (pracovníci knihoven preferují funkci deduplikace – porovnávání záznamů, upozornění na typografické chyby a překlepy, aktualizované zkrácené záznamy a více informací k obsahu dokumentu, tedy preference vycházející z jejich úkolů a pracovního zařazení), musí www rozhraní a portály, které využívají obě skupiny, preferovat požadavky koncových uživatelů a těmto požadavkům vycházet co nejvíce vstříc.
Poznámky
1 BREEDING, Marshal. Next-Generation Library Catalogs [online]. Library Technology Reports, 2007, July-August, s. 6 [cit. 2008-03-04]. Dostupný na WWW: <http://www.techsource.ala.org/ltr/next-generation-library-catalogs.html>.
2 Syndetics Solutions [online]. Bowker, 2009 [cit. 2009-05-12]. Dostupný z WWW: <http://www.syndetics.com>.
3 Amazon.com [online]. Amazon.com, c1996-2009 [cit. 2009-05-12]. Dostupný z WWW: <http://www.amazon.com>.
Google Books [online]. Google, 2009 [cit. 2009-05-12]. Dostupný z WWW:<http://books.google.com>.
4 JIB : Jednotná informační brána [online]. Praha : Národní knihovna ČR; Ústav výpočetní techniky Univerzity Karlovy v Praze, c2001-2009 [cit. 2009-05-12]. Dostupný z WWW: <http://www.jib.cz>.
5 AquaBrowser Library FAQ [online]. Bowker; Medialab, last updated 15.5.2008. 58 s. [cit. 2009-05-06]. Dostupný z WWW: <http://www.aip.cz/download/20080909_AquaBrowser_FAQ.pdf>.
6 BREEDING, Marshall. Investing in The Future : Automation Marketplace 2009. Library Journal [online]. 2009, Iss. 6 (1.4.2009) [cit. 2009-05-12]. Dostupné z WWW: <http://www.libraryjournal.com/article/CA6645868.html>.
7 BREEDING, Marshall. Investing in The Future : Automation Marketplace 2009. Library Journal [online]. 2009, Iss. 6 (1.4.2009) [cit. 2009-05-12]. Dostupné z WWW: <http://www.libraryjournal.com/article/CA6645868.html>.
8 Online Catalogs : What Users and Librarians Want : An OCLC Report. Dublin, Ohio : OCLC, 2009. vi, 58 s. ISBN 1-55653-411-6.
AquaBrowser – Bibliotheek Den Haag – s. 60
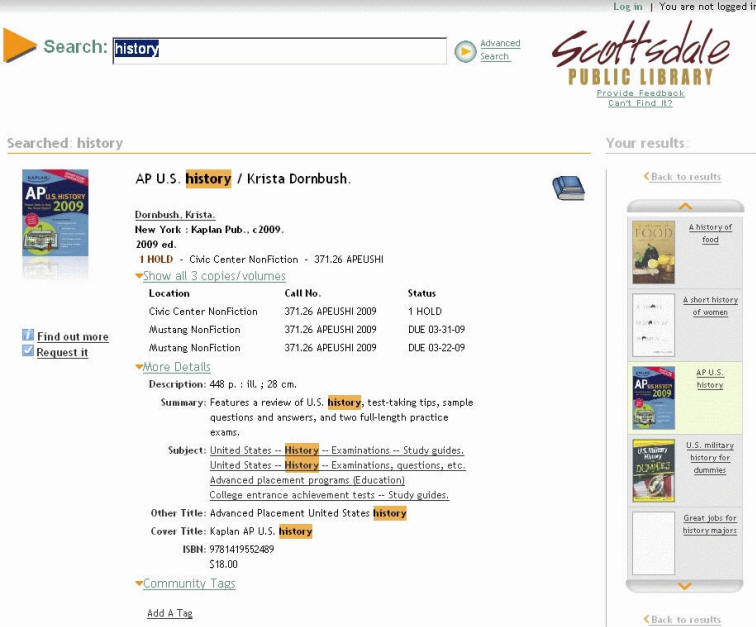
Encore – Scottsdale Public Library – s. 64
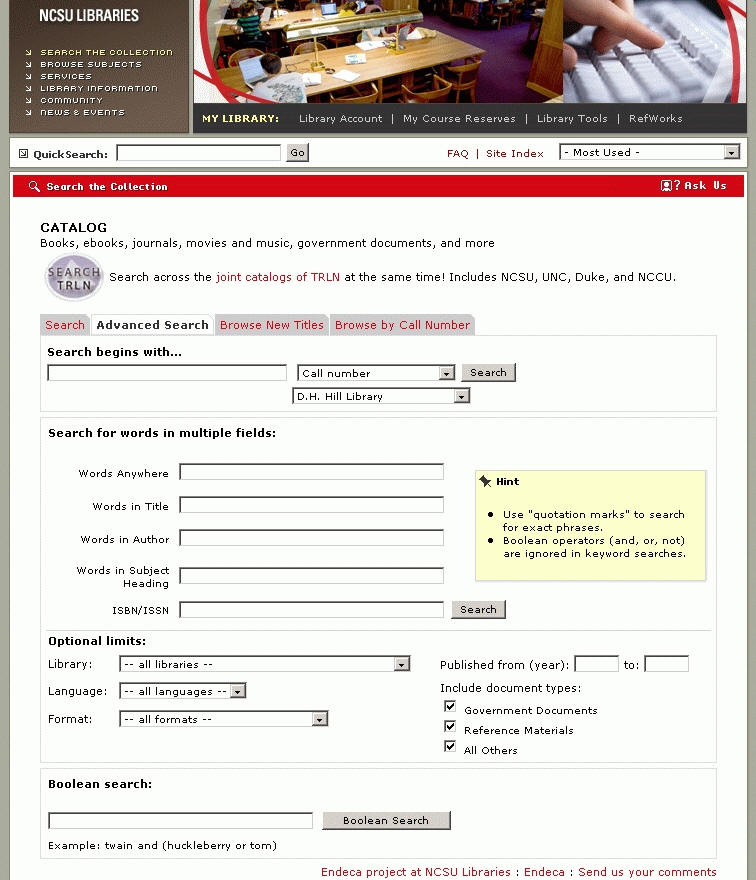
Endeca – NCSU Libraries – s. 68
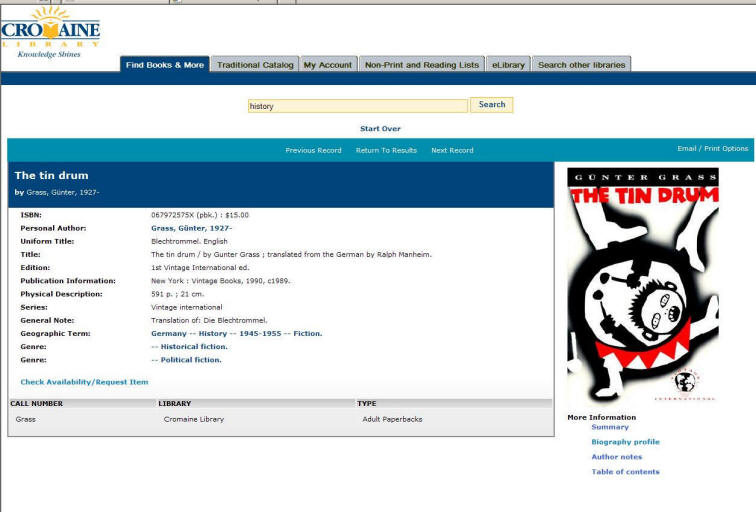
Enterprise – Cromaine Library – s. 72
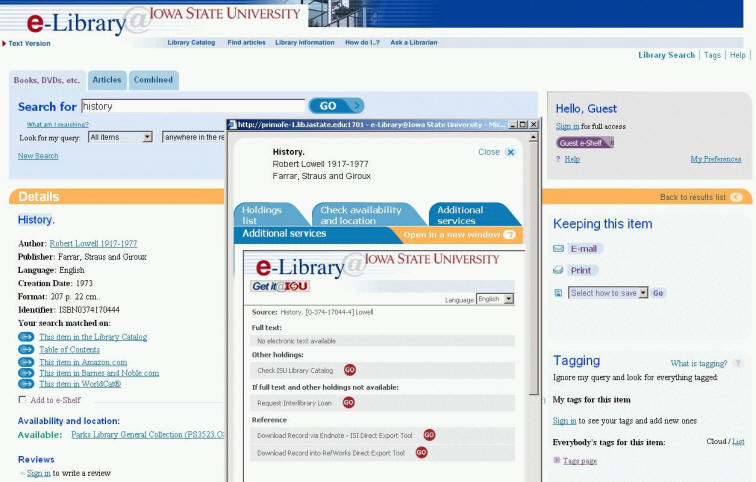
Primo – Iowa State University – s. 76
VuFind – Falvey Memorial Library – Villanova University – s. 80
CITACE:
Pospíšilová, Jindřiška; Košťálová, Karolína; Nemeškalová, Hana. Analýza katalogů nové generace : z pohledu uživatele. Knihovna [online]. 2009, roč. 20, č. 1, s. 58-87 . Dostupný z WWW: <http://knihovna.nkp.cz/knihovna91/pospis.htm>. ISSN 1802-8772.
![]()
| nahoru | |obsah| | archiv | | domů |
| index autorů | | index názvů | | index témat |