|obsah| |index autorů
| | index názvů
| | index témat | |
archiv
|
Knihovna
plus
2010, číslo 1
Vliv trendů systémů organizace znalostí na vývoj Polytematického
strukturovaného hesláře v Národní technické knihovně
Ctibor Škuta, Kristýna Kožuchová / Národní technická knihovna, Odbor
projektů a inovací, Referát PSH /
kristyna.kozuchova@techlib.cz
Resumé:
Polytematický strukturovaný heslář (PSH) je česko-anglický řízený
slovník lexikálních jednotek, který je primárně určen k předmětové
indexaci dokumentů. V současné době je spravován referátem PSH v Národní
technické knihovně (NTK) a jeho údržba probíhá v prostředí softwaru
Aleph 500 ver. 18. Stávající verze PSH 2.1 je pro knihovny dostupná ve
formátu MARC 21 pro autority. Heslář je nyní zveřejněn také v
sémantickém formátu Simple Knowledge Organisation System (SKOS) pod
licencí Creative Commons. Na stránkách knihovny je v sekci PSH pod
odkazem "prohlížení hesláře" vyobrazen seznam 44 hlavních tematických
řad PSH. Systém hypertextových odkazů umožňuje jeho procházení po
hierarchické a asociativní ose. Hlavní navigaci ve stromové struktuře
představují preferovaná znění hesel, avšak k dispozici jsou i hesla
nepreferovaná nebo jejich anglické ekvivalenty. Přítomná vizualizace
hesel je ztvárněna středovým kruhem s aktuálním termínem a připojenými
vazbami na obvodu. Novou funkcí je generování úryvků metadat s hesly PSH
ve formátech Dublin Core a Common Tag. Prostřednictvím zápisu RDF v
atributech (RDFa) je možné jejich zakomponování přímo do těla dokumentů
ve formátu (X)HTML bez vlivu na výsledné zobrazení. V minulém roce byly
zahájeny přípravy na aktualizaci současné verze PSH 2.1. Tento proces je
optimalizován několika způsoby. Jedním z nich je export a následná
analýza klíčových slov použitých při věcném popisu knih v NTK (obsah
pole 653 v bibliografickém záznamu ve formátu MARC 21). Další spočívá v
analýze uživatelských dotazů zadávaných při vyhledávání v katalogu NTK.
Jejich rozbor může být velmi často užitečným nástrojem pro získávání
nových hesel a do určité míry může vyřešit disproporci mezi termíny
používanými při indexaci a termíny používanými samotnými uživateli
popisujícími jejich informační potřeby. Dále byly testovány možnosti
automatické indexace dokumentů s využitím hesel PSH. Za tímto účelem byl
vyzkoušen modul BibClassify z digitálního repozitáře CDS Invenio a Maui
Indexer (Multi-purpose automatic topic indexing).
Klíčová slova: systémy organizace znalostí –
sémantický web – indexace.
Summary:
Polythematic Structured Subject Heading System (PSH) is a set of
subject headings which is used to describe and search the document by
subject. PSH is produced by the National Technical Library in Prague. It
is in its latest version 2.1 bilingual (Czech and English) and the
subject headings in both languages are interconnected. It contains over
13500 subject headings and it is divided into 44 thematic sections.
Subject headings are included in a hierarchy of six (or seven) levels
according to their semantic content. In comparison with uncontrolled
terms and keywords which are created freely, PSH is a controlled
vocabulary which is based on binding principles similar to thesaurus
construction. Despite this, PSH is a user friendly tool. It stems from
the natural language and respects natural word order, and therefore it
makes searching and indexing easier. PSH was published in Simple
Knowledge Organisation System (SKOS) format under Creative Commons (CC)
licencing terms. SKOS is designed to represent traditional knowledge
organisation systems. It provides means for expressing standard
relationships that can be found in most thesauri or subject heading
systems. SKOS is defined using RDF Schema and Web Ontology Language
(OWL) and is expressed in RDF data model.
Keywords: knowledge organisation systems – semantic
web – indexing.
Úvod
 Polytematický strukturovaný heslář je česko-anglický řízený slovník
lexikálních jednotek, který je primárně určen k předmětové indexaci
dokumentů. Je rozdělen do 44 tematických skupin, v nichž jsou hesla dále
hierarchicky členěna v rámci šesti-, výjimečně sedmistupňové hierarchie.
Ve srovnání s klíčovými slovy či nekontrolovanými termíny, které jsou
vytvářeny volně, má PSH pevnou strukturu i obsah. Pravidla pro tvorbu,
správu a údržbu hesláře jsou podobná pravidlům pro konstrukci tezaurů.
Ve své poslední verzi obsahuje PSH přes 13 500 hesel. Je uživatelsky
přívětivým nástrojem, protože vychází z přirozeného jazyka a přirozeného
pořádku slov, čímž umožňuje snadnější a efektivnější vyhledávání.
Polytematický strukturovaný heslář je česko-anglický řízený slovník
lexikálních jednotek, který je primárně určen k předmětové indexaci
dokumentů. Je rozdělen do 44 tematických skupin, v nichž jsou hesla dále
hierarchicky členěna v rámci šesti-, výjimečně sedmistupňové hierarchie.
Ve srovnání s klíčovými slovy či nekontrolovanými termíny, které jsou
vytvářeny volně, má PSH pevnou strukturu i obsah. Pravidla pro tvorbu,
správu a údržbu hesláře jsou podobná pravidlům pro konstrukci tezaurů.
Ve své poslední verzi obsahuje PSH přes 13 500 hesel. Je uživatelsky
přívětivým nástrojem, protože vychází z přirozeného jazyka a přirozeného
pořádku slov, čímž umožňuje snadnější a efektivnější vyhledávání.
PSH byl vyvíjen jako produkt původně Státní technické knihovny v
letech 1991–1993. Podnětem k jeho vytvoření byl především rychlý rozvoj
automatizovaných knihovnických systémů a jejich využívání v českých
knihovnách na počátku 90. let. Vznik a rozvoj hesláře byl několikrát
podpořen grantovými prostředky Ministerstva kultury (MK) a Ministerstva
školství, mládeže a tělovýchovy (MŠMT). Od roku 1995 je používán k
věcnému popisu v NTK, od počátku roku 1997 je rovněž distribuován všem
externím zájemcům, jak knihovnám, tak i komerčním firmám. V roce 2000
získala STK grant MK na překlad PSH do angličtiny. Od konce roku 2006 je
PSH k dispozici ve verzi 2.1, která byla na podzim téhož roku úspěšně
implementována do autoritní databáze systému Aleph.
Heslář je v současné době spravován referátem PSH v Národní technické
knihovně a jeho údržba probíhá v prostředí softwaru Aleph 500 ver. 18.
Referát PSH byl v rámci organizačních změn souvisejících s transformací
Státní technické knihovny na Národní technickou knihovnu zařazen do
odboru projektů a inovací. Nové začlenění vytvořilo důležité interní
vazby na oddělení rozvoje elektronických služeb a oddělení digitální
Národní technické knihovny. Pracovníkům referátu PSH se tak otevřely
možnosti spolupráce na dalších projektech NTK, např. zvažování možnosti
využití PSH v projektu Národního úložiště šedé literatury. Referát PSH
již tradičně spolupracuje s oddělením správy autoritních souborů.
Podstatnou roli ovšem představují také externí vazby, které jsou
reprezentovány institucemi využívajícími heslář a Národní knihovnou ČR
(zejména se jedná o oddělení národních věcných autorit a věcného
zpracování Národní knihovny ČR). Konkrétními aktivními uživateli PSH
jsou kromě Národní
technické knihovny v Praze např.
knihovny Českého
vysokého učení technického v Praze,
Ústřední knihovna Vysokého učení technického v Brně,
Vědecká knihovna v
Olomouci,
knihovna Západočeského muzea v Plzni či
Ústřední knihovna
Filozoficko-přírodovědecké fakulty Slezské univerzity v Opavě.
Heslář mohou zcela zdarma využívat např. knihovny univerzitní,
vědecké, odborné (při specializovaných ústavech a institucích, muzeích
atd.), výjimečně i městské knihovny, knihovny občanských sdružení a
jiné. Jednotlivec se stává uživatelem PSH zprostředkovaně, např. při
vyhledávání v katalogu knihovny, která jej aktivně využívá. Heslář si
mohou uživatelé dále také
stáhnout a
používat v souladu s podmínkami stanovenými licencí Creative Commons
CC-BY-NC-SA (Uveďte autora – Neužívejte dílo komerčně – Zachovejte
licenci 3.0 Česko).
Národní technická knihovna umožňuje PSH zdarma a libovolně používat,
kopírovat, šířit a upravovat, avšak za podmínky, že dílo nebude užíváno
pro komerční účely, s povinností uvést primárního autora (Národní
technická knihovna v Praze) a při vytvoření odvozeniny z původního díla
je nutné šířit jej opět pod dříve uvedenou licencí. K faktorům, které
vedly k uvolnění PSH v rámci zmíněné licence, patří snaha podpořit
knihovnickou komunitu, ale také internetové uživatele, aby se podíleli
na projektech NTK, šířit PSH v otevřených formátech a jako otevřená
data, a umožnit ostatním přístup a právo jej užívat bez nutnosti
souhlasu NTK.
Formáty PSH
Stávající verze PSH 2.1 je pro knihovny dostupná ve formátu MARC 21
pro autority. Heslář je nyní zveřejněn také v sémantickém formátu
Simple
Knowledge Organisation System (SKOS). SKOS představuje rodinu
formálních jazyků určených pro reprezentaci systémů organizace znalostí
– tezaurů, klasifikačních systémů, taxonomií a řízených heslářů. Je
postaven na W3C standardech RDF (Resource Description Framework) a RDFS
(RDF – Schema) za účelem zpřístupnění strukturovaných slovníků pro
sémantický web. XML serializace navíc umožňuje snadné strojové čtení a
jeho další zpracování. SKOS se stal 18. 8. 2009 doporučením W3C a je
spravován pracovní skupinou pro rozvoj sémantického webu.
Možnost zobrazení formátu SKOS je nyní k dispozici jednotlivě pro
každé heslo. Na stránkách PSH je zpřístupněn také celý heslář v daném
formátu pod licencí Creative Commons. Ta je vyjádřena v jazyce ccREL (Creative
Commons Rights Expression Language), založeném shodně na RDF. Bylo
ji tedy možné zakomponovat do distribuce PSH ve formátu SKOS/XML bez
narušení její struktury.

Obr. 1. Zobrazení hesla ve formátu SKOS
Prohlížení hesláře
Primárním přístupem ke sbírkám NTK je vlastní katalog NTK.
Alternativní možností je webové rozhraní na adrese:
http://www.techlib.cz/cs/katalogy-a-databaze/psh/prohlizeni-psh/,
nacházející se pod odkazem "PROHLÍŽENÍ
HESLÁŘE"
na stránkách knihovny v sekci PSH.
Na hlavní stránce je vyobrazen seznam 44 hlavních tematických řad PSH.
Systém hypertextových odkazů umožňuje procházet heslářem po hierarchické
a asociativní ose. Hlavní navigaci ve stromové struktuře představují
preferovaná znění hesel, avšak k dispozici jsou i hesla nepreferovaná
nebo jejich anglické ekvivalenty. V tomto případě je možné zvolit i
celo-anglickou verzi hesláře.
Vizualizace je ztvárněna středovým kruhem s aktuálním termínem a
připojenými vazbami na obvodu. Vztahy okolních hesel jsou indikovány
malými ikonami symbolizujícími nadřazenost, podřazenost nebo similaritu
úrovně PSH. Tento diagram je interaktivní a je ho také možné použít pro
procházení heslářem, resp. knihovním fondem. Simultánně s prohlížením
PSH se pod jednotlivými hesly zobrazuje seznam dokumentů z katalogu NTK,
které byly při katalogizaci daným termínem indexovány. Toto propojení na
knihovní fond umožňuje přímé zadání požadavku na výpůjčku. V minulém
roce byla navíc hesla PSH namapována na předmětová hesla NK ČR. V
případě, že byly nalezeny shodné termíny, jsou pod nabídku publikací z
katalogu NTK zařazeny i záznamy Národní knihovny. Formu nabízených
publikací vyjadřuje ikona vedle údajů o dokumentu, v případě její
dostupnosti je zde zobrazena i obálka.
Unikátní identifikátor deskriptorů zastupuje jejich URI adresa, která se
pro jednotlivá hesla liší pořadovým číslem v hesláři (např.
http://psh.ntkcz.cz/skos/PSH117). Tato "cesta" slouží pro vyhledání
příbuzných konceptů na
Library of
Congress Subject Headings a
DBPedii (Wikipedie ve
formě linked data), které jsou přístupné pod hesly v případě shody.
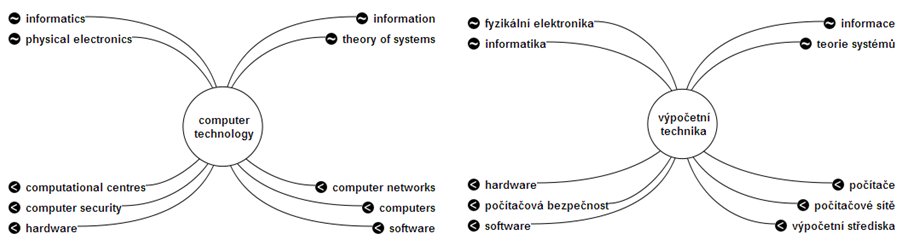
Obr. 2. Vizualizace hesla PSH
Vytváření úryvků metadat
Novou funkcí zpřístupněnou na stránkách hesláře je generování úryvků
metadat s hesly PSH. Prostřednictvím zápisu
RDF
v atributech (RDFa)
je možné jejich zakomponování přímo do těla dokumentů ve formátu
(X)HTML
bez vlivu na výsledné zobrazení. Aktuální webové rozhraní PSH umožňuje
generování metadat ve formátech Dublin Core a Common Tag.
Dublin
Core je soubor
metadatových prvků, jehož záměrem je usnadnit vyhledávání elektronických zdrojů.
Původně byl vytvořen jako popis zdrojů na WWW sestavený přímo autorem, postupně
ale zaujal instituce zabývající se formálním zpracováním zdrojů, jako jsou
muzea, knihovny, vládní agentury a komerční organizace [DUBLIN, 2006]. V
současné době se jedná patrně o nejrozšířenější způsob zápisu předmětových
metadat na webu.
Common Tag
je poměrně mladý sémantický formát pro tagování webového obsahu, přispívající k
jeho vyšší provázanosti, vyhledatelnosti a uspořádanosti [COMMON, 2009].
Byl představen v červnu roku 2009 pod záštitou společnosti Yahoo!, velmi brzy
jej však začali podporovat i další společnosti nabízející internetové služby (Freebase,
Zemanta, Zigtag aj.).
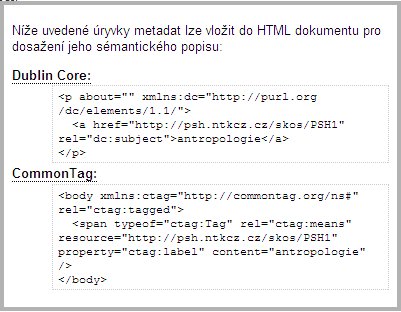
Obr. 3. Zobrazení tagu z řízeného hesláře
Aktualizace PSH (Návrh nového hesla PSH)
V minulém roce byly zahájeny přípravy na aktualizaci současné verze
PSH 2.1. Rychlé zastarávání termínů je typickým problémem všech heslářů,
které mají pevnou strukturu i obsah. Tvorba hesláře se tak stává nikdy
nekončící činností. V otázce časové frekvence aktualizace se střetávají
dva protichůdné požadavky; na jedné straně by řízený slovník měl být
stabilní, na straně druhé by ale měl být aktualizován dle potřeby. Při
aktualizacích PSH by se mělo přihlížet k účelu, pro který byl vytvořen.
V tomto případě bylo cílem tvůrců vybudovat nástroj blízký přirozenému
jazyku, jenž by doplnil nebo částečně nahradil stávající klasifikační
systémy zejména v knihovnách s polytematickými fondy a ve finále také
zkvalitnil vyhledávání v knihovních databázích. Za účelem zvýšení
kvality vyhledávání se v hesláři kromě preferovaných termínů vyskytují
také termíny nepreferované a asociované. Hesla PSH jsou uspořádána v
rámci hierarchie, která nutně nekopíruje strukturu vědních oborů.
Klíčovým kritériem aktualizace PSH je zachování kontinuity. V hesláři
by neměly být prováděny žádné výrazné změny, preferovány jsou pouze
změny dílčího charakteru. Nedoporučuje se proto zbytečně měnit
hierarchickou strukturu a vztahy mezi hesly a přesouvat pojmy mezi
tematickými řadami. Stabilita je totiž důležitější než snaha o vylepšení
detailů. Ne všechna hesla mohou být do nové verze přijata. Zejména je
třeba dbát na skutečnost, že hesla příliš specifická a hesla patřící do
hlubších vrstev logické struktury nemají v PSH místo. V případě
nezbytnosti lze tato hesla zařadit do skupiny odkazů. V zásadě tedy
platí, že při zařazování nových hesel do struktury by měla být dodržena
úroveň obecnosti. Při aktualizaci PSH je téměř vyloučeno vyřazovat
deskriptory použité ve starších verzích. V hesláři je možné provádět
pouze tyto typy úprav – zařazování nových hesel (deskriptorů), která
jsou výsledkem pokroku lidského poznání a tvorba vylučovacích a
přidružovacích odkazů. Vylučovací odkazy se používají pro možné
vyloučení synonym nebo významově příliš podřadných hesel. Přidružovací
odkazy vyjadřují asociativní vztahy mezi pojmy tak, aby pomocí odkazů
umožnily nalézt obsahově příbuzné dokumenty.
Proces aktualizace hesláře je dle Pravidel pro správu a aktualizaci PSH
optimalizován několika způsoby. Jedním z nich je export a následná analýza
klíčových slov použitých při věcném popisu knih v NTK (obsah pole 653 v
bibliografickém záznamu ve formátu MARC 21). Pole 653 je v NTK používáno pouze
doplňkově, a to v případech, kdy danou skutečnost nelze dostatečně přesně
vyjádřit prostřednictvím hesel PSH (jedná se o podrobnější úroveň zpracování
tématu) nebo se v hesláři odpovídající heslo nevyskytuje (jedná se o nový
termín).
Exportovaná data z pole 653 byla již v loňském roce nejprve porovnána
s hesly PSH. Přibližně u 1 700 záznamů byly zjištěny duplicity polí 650
(heslo PSH) a 653 (pole volně tvořený termín). Tyto duplicity byly v
rámci revize odstraněny. Poté byl výpis volně tvořených termínů
programově zpracováván. Výsledkem je tabulka obsahující jednotlivé
termíny s frekvencí jejich výskytů. Termíny, které překročí určenou
prahovou frekvenci multiplicity, jsou posuzovány jako kandidát na nové
heslo PSH. Samozřejmě i pro ně platí stejná pravidla pro zařazení do
hesláře jako u ostatních návrhů.
V souvislosti s přípravou aktualizace PSH se mimo jiné otevřela
otázka, jak mohou uživatelské knihovny a odborná veřejnost přispět k
revizím PSH. Proto byl vytvořen jednoduchý
webový formulář pro zasílání návrhů nového hesla PSH. Využívat jej
mohou jak katalogizátoři oddělení věcného zpracování v NTK, tak externí
uživatelé, např. zájemci o problematiku selekčních jazyků, ale i
zákazníci NTK, kteří se prostřednictvím formuláře stávají tvůrci
samotného obsahu PSH. Pro lepší viditelnost byl odkaz na formulář pro
návrh nového hesla zakomponován ke každému heslu v oddělení "PROHLÍŽENÍ
HESLÁŘE" na stránkách NTK. Po vyplnění příslušných polí je tabulka
odeslána pracovníkům Referátu PSH, kteří získané návrhy posuzují a
zvažují jejich zařazení do struktury PSH. Ti dále ve spolupráci s
katalogizátory NTK u získaných návrhů zvažují účelnost hesel, popř.
kontrolují jejich duplicitu.
Příkladem požadavku na vytvoření nového hesla PSH zaslaného prostřednictvím
webového formuláře je "programovací jazyk C#", synonymum – "programovací jazyk C
Sharp", a také v angličtině "programming language C#", "programming language C
Sharp". Geografické termíny, chronologické údaje, osobní jména a názvy užité
jako předmět mohou být ve vybraných případech použité, např. je-li tématem
dokumentu produkt se specifickým názvem. V současné verzi PSH 2.1 se v řadě
výpočetní technika nacházejí některé názvy programovacích jazyků, např.
programovací jazyk Java, PHP, C, C++. Nabízí se tedy řešení, že do struktury PSH
budou zařazeny také další názvy programovacích jazyků, včetně navrhovaného
programovacího jazyka C#.

Obr. 4. Formulář pro návrh nového hesla PSH
Analýza uživatelských dotazů
V současné době se při aktualizaci PSH kromě přímé cesty v podobě návrhu
nového hesla využívá také další způsob optimalizace aktualizace PSH, který
spočívá v analýze uživatelských dotazů zadávaných při vyhledávání v katalogu
NTK. Rozbor dotazů pokládaných uživateli při práci v online katalogu může být
velmi často užitečným nástrojem pro získávání nových hesel a do určité míry
vyřešit disproporci mezi termíny používanými při indexaci a termíny používanými
samotnými uživateli popisujícími jejich informační potřeby. Návrhy na nová hesla
se získávají z logu vyhledávání. Ten představuje soubor, do kterého se
zaznamenávají uživatelské požadavky společně s textovým záznamem komunikace mezi
zúčastněnými počítačovými vrstvami a systémovými informacemi. V první fázi je
nutné odfiltrovat nepotřebný text. Tento proces využívá schopností regulárních
výrazu, které představují univerzální, uživatelsky nadefinovanou šablonu
struktury textu. Vzhledem k faktu, že je dotaz strukturně vždy stejný, jsou
regulární výrazy vhodným řešením.
Při nalezení části textu shodné s regulárním výrazem je možné tato
data extrahovat a výsledky použít pro jednoduchou statistickou analýzu.
Cílem algoritmu jsou samozřejmě jen termíny zadávané při vyhledávání ve
všech polích nebo jen v poli předmětovém a v heslech PSH. I tato hesla
jsou dále filtrována, za účelem odstranění automaticky nevyhovujících
dotazů (ISBN, ISSN aj.) nebo hesel, která jsou již v PSH obsažena.
Dalším problémem je také multiplicita odeslání dotazu každého
samostatného uživatele. Je logické, že v případě násobného vyhledávání
identických termínů jediným uživatelem je vhodné, aby se tento požadavek
zaznamenal pouze jednou. K této situaci navíc dochází velmi často.
Hlavní příčinou je zobrazení detailu nalezeného záznamu s následným
návratem zpět na výsledky vyhledávání. V tomto momentu totiž dochází k
opětovnému odeslání požadavku do knihovního katalogu. K filtrování proto
nedochází jen na základě vyhledávacích parametrů, ale rozhodují i
systémové informace v podobě IP adresy, data a času.
Získané termíny se periodicky přidávají do výstupního souboru nebo
databáze. Při vyšší frekvenci některého z nich se heslo posuzuje jako
kandidát na nový deskriptor nebo zařazení synonymního výrazu k heslu
existujícímu. Porovnávání výsledků analýzy uživatelských dotazů s hesly
PSH poskytuje také informace o jejich využitelnosti.
Automatická indexace
V souvislosti s možností vytváření úryvků metadat pro hesla PSH a
jejich vkládání do HTML stránek probíhala v minulém roce další testování
týkající se možnosti automatické indexace dokumentů s využitím hesel
PSH. Tento úkol se musí v první řadě opírat o efektní a efektivní
algoritmus zpracování textu. K jeho řešení můžeme přistupovat dvěma
odlišnými způsoby. Prvním z nich je statistická analýza textu, která
odhaluje frekvence jednotlivých slov, slovních spojení nebo jejich
částí. Program načte zpracovávaný text a v místě mezer, interpunkčních
znamének a konců řádků oddělí jednotlivá slova, která uloží do seznamu.
Ten je následně cyklicky prohledáván pro zjištění násobných termínů.
Podle nastavení filtru může některá slova nebo slovní spojení vynechat.
Nejfrekventovanější z nich jsou na konci procesu porovnávány s hesly PSH
pro zjištění shody. V jejím případě by byl dokument indexován.
Dalším možným způsobem zpracování je syntaktická analýza přirozeného
jazyka. Ta však vzhledem k velké nejednoznačnosti a množství možných
způsobů větné stavby vyžaduje výrazně sofistikovanější algoritmus.
Výstup a konečná fáze indexace je stejná jako v prvním případě. Tyto
programy musí navíc splňovat i další kritéria v podobě rychlosti
zpracování nebo nároku na jistý počet již značených dokumentů. To se
týká učících algoritmů, které pracují na základě "zkušeností" získaných
z analýzy ruční indexace.
Ve spojení s PSH byly testovány dva volně dostupné nástroje pro
automatickou indexaci, kdy každý zastupoval jeden z výše popsaných
přístupů indexačního procesu. Oba dva na svém vstupu shodně akceptovaly
PSH ve formátu SKOS/XML.
Pro statistickou analýzu textu byl vyzkoušen modul BibClassify z
digitálního repozitáře
CDS
Invenio.
Jedná se o software pro tvorbu digitálních knihoven vyvíjený institucemi
CERN
(European Organization for Nuclear Research) a
EPFL
(École Polytechnique Fédérale de Lausanne), který je v NTK v současné
době využíván pro repozitář šedé literatury v rámci projektu
NUŠL
(Národního úložiště šedé literatury). Jeho vývojáři zdůrazňují, že
vzhledem k dané metodě indexace je velice závislý na kvalitě použitého
tezauru nebo předmětového hesláře. Jeho hlavní nevýhoda spočívá v nízké
rychlosti zpracování, která se projevuje především u rozsáhlejších
textů.
Nástrojem, představujícím alternativní přístup při analyzování textu,
byl
Maui Indexer
(Multi-purpose
automatic topic indexing,
program vyvinutý
Olenou Medelyan
v rámci doktorského studia na
University of
Waikato na
Novém Zélandu, pod sponzorskou záštitou společnosti Google. Jedná se o
víceúčelový nástroj pro extrakci klíčových slov a frází, automatické
tagování, přiřazování termínů z řízeného hesláře, předmětové indexování
a tematické indexování s termíny získanými z Wikipedie [MEDELYAN, 2009].
Základem pro využití jeho dovedností je dostatečný počet již
indexovaných dokumentů podle přiloženého hesláře. Maui Indexer tyto
dokumenty analyzuje a na základě výsledků vytváří indexační model, který
je možné aplikovat na další texty. Díky schopnostem analýzy přirozeného
jazyka a učení může dosahovat velmi dobrých výsledků.
Vyšší integrace PSH do vyhledávání v katalogu NTK
Hlavním úkolem PSH je usnadnění vyhledávání a orientace uživatele při
prohlížení knihovního fondu NTK a dalších institucí, které jeho služeb
využívají. Primárním cílem je tedy jeho implementace a služba uživateli.
Na základě struktury PSH by bylo možné sémanticky rozšířit vyhledávání
dokumentů v katalogu NTK.
Situace, kdy uživatel hledá titul podobný jinému titulu, jsou na denním
pořádku, avšak ne vždy je jeho nalezení jednoduché. Dalším případem
mohou být dokumenty podrobnější nebo obecnější než je právě aktuální
záznam. Integrace v katalogu by tak mohla zahrnovat nabídku omezeného
počtu dokumentů indexovaných hesly nacházejících se na nejbližších
vrstvách v hierarchii PSH, stejně tak i příbuzných titulů označených
heslem asociovaným v jiné části hesláře. Jejich nabídka by se mohla
zobrazovat v katalogu u každého jednotlivého dokumentu. Pro co
nejefektivnější výběr podobných titulů by závislost knih nesměla být
odvozena pouze z termínů PSH, ale opírala by se také o klíčová slova. To
znamená, že by primárně byly nabízeny tituly s vyšším počtem shodných
údajů. Ve spojení s dalšími informacemi o názvu, nebo například edičními
údaji, by bylo možné nabízet tituly s vysokým stupněm ekvivalence. Pokud
bychom zašli ještě dále a všechny zmíněné možnosti spojili s
uživatelským hodnocením, frekvencí výpůjček jednotlivých titulů nebo
titulů s podobnou tematikou půjčených jediným uživatelem, mohli bychom
dosáhnout nabídky služeb příznačných pro nejmodernější katalogy.
Využití PSH při mapování knihovního fondu
Využití hesláře nemusí být závislé pouze na jeho struktuře a
hierarchickém provázání, ale také na počtu dokumentů, které jsou
jednotlivými hesly indexovány. Suma titulů se stejným indexem PSH určuje
váhu hesla v daném kontextu a současně mapuje knihovnický fond. Tyto
hodnoty se logicky liší pro každou z institucí dle zaměření a pro každé
heslo podle zařazení v hierarchii stromové struktury. Smysl má tedy
porovnávat primárně hesla na stejné úrovni – hesla příbuzná. S využitím
vizualizačních nástrojů je možné sumy titulů převést do grafické podoby
a zobrazit zastoupení určených oborů. Výsledkem aplikace mohou být různé
typy grafů, dnes velmi moderních tag-cloudů (oblak štítků) nebo
jakákoliv jiná vyjádření zobrazující kvantitativně-kvalitativní rozdíly
mezi hesly. Všechny tyto prvky signifikantně napomáhají v navigaci při
procházení katalogy dokumentů a zároveň jejich grafická prezentace
zpestřuje jinak často poměrně nudnou vizuální stránku.
Závěr
V době svého vzniku představoval PSH jednu z prvních aktivit
knihovnické komunity ve směru standardizace termínů věcného popisu. V
současnosti neslouží pouze jako prostředek pro věcnou selekci
bibliografických záznamů, ale jeho potenciál je rozvíjen také v oblasti
třídění a zpřístupňování webových dokumentů. PSH jako zástupce
klasických systémů organizace znalostí lze nyní poměrně dobře integrovat
s novými technologiemi. Sledování a aplikace trendů v této oblasti je
proto nevyhnutelným předpokladem jeho dalšího vývoje.
Pokud máte zájem o informace z oblasti PSH, přihlaste se prosím do
elektronické konference PSH (pshkonference@stk.cz) nebo sledujte
webové stránky PSH. Případné dotazy rádi zodpovíme i na e-mailové
adrese psh@techlib.cz.
Použité zdroje
BibClassify admin guide [online]. Last updated: 2008-03-12 [cit.
2010-02-09]. Dostupný na WWW: <http://invenio-demo.cern.ch/help/admin/bibclassify-admin-guide
>.
Common Tag [online]. 2009 [cit. 2010-02-09]. Dostupný na WWW:
<http://www.commontag.org/Home>.
Dublin Core : Czech homepage [online]. 2006 [cit. 2010-02-09].
Dostupný na WWW: <http://www.ics.muni.cz/dublin_core/index.html>.
JONES, Steve; et al. A transaction log analysis of a digital library.
International Journal on Digital Libraries. 2000, vol. 3, no. 2, s. 152-169.
MEDELYAN, Olena. Useful web resources related to automatic topic indexing
[online]. July 13, 2009 [cit. 2009-11-11]. Dostupný na WWW: <http://maui-indexer.blogspot.com/2009/07/useful-web-resources-related-to.html
>.
MYNARZ, Jindřich. Jak lze prakticky využít Polytematický strukturovaný heslář
pro věcný popis elektronických zdrojů. Ikaros [online]. 2009, roč. 13, č.
12 [cit. 2009-12-01]. Dostupný na WWW: <http://www.ikaros.cz/node/5872>.
URN-NBN:cz-ik5591. ISSN 1212-5075.
MYNARZ, Jindřich; KAMRÁDKOVÁ, Kateřina; KOŽUCHOVÁ, Kristýna. Polythematic
Structured Subject Heading System & Creative Commons. In Seminář ke
zpřístupňování šedé literatury [online]. Praha : Národní technická knihovna,
2009 [cit. 2010-01-25]. Dostupný na WWW: <http://www.techlib.cz/files/download/id/649/psh-cc.pdf>
(text příspěvku) a <http://www.techlib.cz/files/download/id/690/psh-v-licenci-creative-commons.pdf>
(prezentace). ISSN 1803-6015.
MYNARZ, Jindřich; KOŽUCHOVÁ, Kristýna; KAMRÁDKOVÁ, Kateřina. Novinky z
oblasti Polytematického strukturovaného hesláře. Ikaros [online]. 2009,
roč. 13, č. 7 [cit. 2009-07-01]. Dostupný na WWW: <http://www.ikaros.cz/node/5591>.
URN‑NBN:cz-ik5591. ISSN 1212-5075.
SKOLKOVÁ, Linda. Polytematický strukturovaný heslář (Polythematic Structured
Subject Heading System). Praha, 2007. iv, 172 s., 27 s. příl. + 1 CD-ROM.
Diplomová práce. Univerzita Karlova v Praze, Filozofická fakulta, Ústav
informačních studií a knihovnictví. Vedoucí diplomové práce Ing. Miloslav Nič,
PhD. Dostupný také na WWW: <http://www.skolkova.net/diplomka/SKOLKOVA_Linda_DP_PSH.pdf>.
Zásady pro vytváření Polytematického strukturovaného hesláře (PSH) : upravená
verze. Praha, prosinec 1996. 13 s. Dostupný na WWW: <http://www.techlib.cz/files/download/id/53/Pravidla%20pro%20aktualizaci%20a%20spr%C3%A1vu.pdf>.
CITACE:
Škuta, Ctibor;
kožuchová,
Kristýna. Vliv trendů systémů organizace znalostí na vývoj
Polytematického strukturovaného hesláře v Národní technické knihovně .
Knihovna plus [online]. 2010, č. 1 . Dostupný z WWW: <http://knihovna.nkp.cz/knihovnaplus101/sktua.htm>.
ISSN 1801-5948.

| nahoru
|
|obsah| |
archiv
| | domů |
| index autorů | |
index názvů | |
index témat |