|obsah| |index autorů | | index názvů | | index témat | | archiv |
Knihovna plus
2005, číslo 1
Petr Boldiš
Nejrozšířenější technikou vyhledávání informací na internetu je v současnosti bezesporu používání tzv. vyhledávačů (search-engines). V době, kdy se odhaduje datový objem informací na internetu přibližně na 0,532 exabytů [Lyman, Peter – Varian, 2003], jsou zatím jedinou technologií schopnou zachytit alespoň jejich část. Jde o populární, ale velmi nedokonalou službu, od které se očekává mnohdy víc, než je skutečně schopna dát. Přes veškerou snahu o technická vylepšení je používání vyhledávačů stále spojeno s řadou problémů, které jsou tématem tohoto článku.
Trh vyhledávačů je velmi náročným ekonomickým prostředím, které jednotlivé firmy neustále žene do technologických a marketingových inovací, jen aby si udržely svou pozici na trhu, případně aby svůj tržní podíl rozšířily. Změny, které nastávají na žebříčcích hodnocení, ukazují, jaký význam firmy tomuto prostředí přikládají a jak velikým hnacím motorem jsou tyto faktory pro další, především technologický, vývoj.
Tržní podíly jednotlivých firem se od zrodu této technologie významně změnily. Danny Sullivan ve svém článku [Sullivan, 2005] nazývá ostré soupeření mezi vyhledávači "válkami" a rozdělil je do čtyř období: 1. válka (září 1997 – červenec 1999), 2. válka (září 1999 – červen 2000), 3. válka (červen 2002 – prosinec 2002) a 4. válka (od srpna 2003).
| Vyhledávač | Deklarovaná velikost indexu | Limit pro indexaci stránek (v kilobytech) |
| 8.1 miliard | 101K | |
| MSN | 5.0 miliard | 150K |
| Yahoo | 4.2 miliard (odhad) | 500K |
| Ask Jeeves | 2.5 miliard | 101K+ |
V těchto "válkách" jde především o zlepšení relevance vyhledávače a především o zvýšení deklarované velikosti indexu vyhledávače. Tato hodnota je totiž hlavním marketingovým údajem, který je mezi uživateli podvědomě chápán jako určitý ukazatel kvality. Firmy se tak neustále předhání v publikování tiskových zpráv o velikosti svých indexů. Situace k lednu 2005 je uvedena v tabulce 1.
Deklarované velikosti indexů není možné objektivně porovnat, navíc se mohou lišit i definice, co je měřitelnou jednotkou (webová stránka včetně grafiky, započítání textové stránky a grafiky jako samostatných dokumentů apod.). Odhady velikosti indexů vyhledávačů na serverech jako searchenginewatch.com nebo searchengineshowdown.com se tak provádějí zkušebním vyhledáním série dotazů na každém z nich a následným porovnáním počtu odkazů. Na konci roku 2004 se objevil i specializovaný software Thumbshots Ranking[1], který umožňuje porovnání velikostí indexů dvou vyhledávačů podle zadaného slova.
Na základě nově publikovaných údajů, které jsou shrnuty v tabulce 1, pravděpodobně nastává již pátá "válka" mezi vyhledávači. Méně konkurenceschopní odpadávají z tohoto boje, nové firmy a technologie se objevují a také dochází ke slučování některých firem mezi sebou (např. firma Inktomi a Yahoo!). Pro srovnání je možné uvést statistiky vyhledávačů s největším indexem mezi léty 1997-2002, které jsou v tabulce 2.
| březen 2002 | Google, WiseNut, AllTheWeb |
| duben 2001 | Google, Fast, MSN (Inktomi) |
| duben 2000 | Fast, Alta Vista, Northern Light |
| březen 1999 | Northern Light, Alta Vista, HotBot |
| květen 1998 | Alta Vista, HotBot, Northern Light |
| únor 1998 | HotBot, Alta Vista, Northern Light |
| červen 1997 | HotBot, Alta Vista, Infoseek |
Tabulka 2: Vyhledávače s největším indexem 1996 – 2002
Zdroj:Notess, 2002
Tento trh výstižně popisuje Stephen Arnold [Arnold, 2003] slovy: "Darwinistická podstata vyhledávacího průmyslu dovoluje, aby se malé specializované společnosti na trhu rychle objevily a často zmizely stejně rychle... Doufejme, že některé [z nových společnosti] přežijí a budou prosperovat. Je ale sporné, zda v blízké budoucnosti budou výzvou pro dominantní společnosti na trhu." Všechny uvedené firmy nabízí své vyhledávací služby zdarma[2]. Zisk, který je podmínkou jejich přežití, tak musí získat jinak – z reklamy (včetně placených odkazů ve výsledcích) nebo z licencování své technologie dalším vyhledávačům. Tento trh je velmi perspektivní a výnosný. Jen za rok 2002 uvádí [Arnold, 2003] zisk firem Overture 500 miliónů dolarů a Google 300 miliónů dolarů. Vzhledem k těmto tržbám se nabízí otázka, zda není objektivita ve výsledcích těchto vyhledávačů omezována na úkor placených odkazů. V tomto prostředí má ale každý uživatel na výběr – používat vyhledávač zdarma nebo využít placených vyhledávačů, které budou zcela bez reklam. Vývoj a provoz každého vyhledávače musí být zaplacen jakoukoli formou. Přirozeně se tak na trhu nejlépe drží firmy, které jsou již dostatečně finančně zajištěné – např. MSN (provozuje firma Microsoft) nebo Google (nyní již veřejně obchodovaná akciová společnost). Zároveň tyto firmy mají dostatečný podíl na trhu reklamy na internetu a jsou ziskové. Celosvětové odhady tržních podílů vyhledávačů jsou velmi obtížně zjistitelné, takže musíme pro ilustraci zvolit pouze Spojené státy americké.
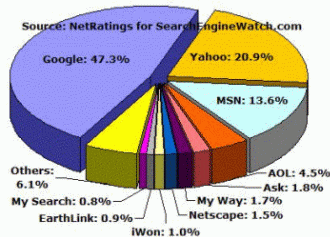
Obrázek 1: Distribuce dotazů na vyhledávače – květen 2004
Zdroj: Sullivan, 2005a
Podíl dotazů v různých vyhledávačích v květnu 2004 je znázorněn na obrázku 1. I když jde pouze o trh vyhledávačů v USA, zdá se, že několik velkých firem začíná dominovat celému trhu (Google, MSN, Yahoo!). Tato dominance neplatí v celém světě bezvýhradně, protože národní vyhledávače[3], které mají zvláštní podporu jazyka (skloňování, časování) a indexují hlavně domácí zdroje, jsou oblíbenější, protože z pohledu uživatelů přinášejí často relevantnější informace. Průzkum můžeme ale vnímat jako podíly na celosvětovém trhu, kterému společnosti z USA dominují.
Na obrázku číslo 2 je graf zachycující podíl dotazů v jednotlivých vyhledávačích téměř o rok později – v březnu roku 2005. Podle průzkumu na vyhledávače tří firem (Google, Yahoo! a MSN) směřuje celkem 81 % všech dotazů. Znamená to, že tyto firmy trhu vyhledávačů výrazně dominují, což ale neznamená, že se situace v několika málo letech nemůže změnit.
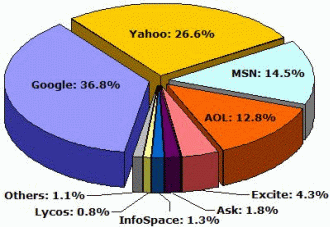
Obrázek 2: Distribuce dotazů na vyhledávače – květen 2004
Zdroj: Sullivan, 2004b
Pokud akceptujeme koncepci vyhledávačů jako hledání klíčových slov doplněné dalšími nabídkami k usnadnění hledání, musíme si uvědomit omezení a možné problémy, které jsou s nimi spojeny. Mezi základní problémy můžeme zařadit:
Velikost indexu označuje množství dokumentů, které vyhledávač nalezne, jejich indexovaný obsah uloží do své interní databáze, ve které následně komunikují uživatelé. Tato velikost je přibližným měřítkem množství informací, které je v těchto vyhledávačích možné najít. Žádný z vyhledávačů neindexuje všechny dostupné stránky či jiné dokumenty, ale mezi vyhledávači spíše dochází k částečnému překrytí indexů. Studie [Lawrence-Giles, 1999 ani jedním vyhledávačem a zároveň množství unikátních odkazů u ] poukázala na to, že pokrytí webových stránek vyhledávači mezi léty 1997 a 1999 pokleslo, a vzhledem k dynamickému nárůstu počtu nových stránek se tento trend bude prohlubovat. Dále tato studie dochází k závěru, že vzájemné překrytí indexů mezi různými vyhledávači je velmi nízké. To znamená, že neustále bude existovat obsah, který nebude zachycen každého z vyhledávačů.
Aktualizace indexu je pro vyhledávání klíčová. Uživatel vždy komunikuje s databází vyhledávače, a tak nutně dochází ke zpoždění mezi časem indexace informace vyhledávačem a její prezentací uživateli. Podle statistik Grega Notesse z roku 2003 [Notess, 2003] je průměrnou dobou pro obnovení indexu přibližně jeden měsíc. Tuto dobu potvrzuje i francouzská studie z října stejného roku [How do search tools work, 2003]. Společnost Inktomi podle [Metadent, 2004] tvrdí, že její "pavouk" jménem Slurp dokáže indexovat 10 miliónů stránek za den, a veškeré změny se tak v indexu projeví do dvou dnů. I když je to oproti roku 2003 zřetelný posun, riziko hledání ve starých informacích přetrvává i nadále.
V prostředí internetu a speciálně v prostředí služby word wide web se objevují i další formáty dokumentů, které kladou zvýšené nároky na zpracování. Jde především o soubory ve formátu PDF, který se stal standardem pro oficiální a akademické publikace, a o soubory ve formátech MS Office, které jsou známkou malé schopnosti uživatelů publikovat informace ve formátu HTML. Tyto dokumenty jsou ve vyhledávačích zpracovávány doplňkovými moduly (např. pro čtení souborů PDF). Přesto jejich indexace není bezproblémová, a tak jejich podíl v celkovém objemu indexu vyhledávače bude vždy nižší než počet stránek založených na jazyku HTML.
Dynamicky tvořené stránky jsou pro vyhledávače dalším problematickým okruhem. Tyto stránky jsou zobrazovány na základě konkrétního požadavku uživatele (tzv. on-demand). Každý požadavek je jedinečný a pravděpodobnost jeho opakování klesá s rostoucím množstvím zpřístupněných dat v datovém souboru – např. databázi. Zmíněné databáze tak mohou ve formátech, určených pro webové stránky (tzv. nativních) zveřejňovat pouze odpověď na dotaz uživatele jen jako dynamicky generovanou stránku, která bude v této podobě zobrazena nejvýše několik minut. Z klasického pohledu na organizaci informací je tento stav špatný, neboť informace není dohledatelná. Na druhé straně ale není technicky možné ani logicky účelné zachycovat informace, které mají význam pro krátký časový úsek (např. kurzovní lístek, předpověď počasí).
Jedním z největších problémů současných vyhledávačů je tzv. index spamming. Jde o souhrnné označení metod, které mají za cíl oklamat algoritmus vyhledávačů hodnotící relevanci stránek tak, aby byla vytvořená stránka hodnocena v seznamu výsledků co nejvýše, i když tematicky dotazu neodpovídá. Jak výstižně upozorňuje Greg Notess, tento problém souvisí spíše s lidskou povahou: "Všechny standardní techniky pro hodnocení relevance selhaly kvůli nečekanému aspektu velmi dynamické povahy webu. Nebo možná přesněji kvůli lidské povaze. Od doby, kdy začaly být vyhledávače používány pro hledání informací, se tvůrci webových stránek neustále snaží zvýšit hodnocení svých stránek v těchto vyhledávačích." [Notess, 1999].
Časté praktiky index spammingu jsou například:
Z určování relevance se stal boj mezi ctižádostivými autory a tvůrci vyhledávačů, kteří musí zajistit určitou relevanci nalezených odkazů, aby obstáli v náročné konkurenci tohoto trhu. Tento boj se neustále vyvíjí – na nový způsob hodnocení relevance reagují autoři dalšími triky. Řešení tohoto problému bohužel zatím není v dohledu. Jedná se čistě o etický problém, který se v prostředí internetu, kde schází centrální řídící autorita, na technické rovině nedá uspokojivě vyřešit.
Vyhledávače a metody založené na vyhledávání podle klíčových slov obecně mají před sebou celou řadu velkých výzev, které je potřeba pro vylepšení tohoto konceptu vyhledávání naplnit. Stephen Arnold [2003] uvádí jako hlavní koncepční problémy:
Tyto okruhy můžeme tematicky rozčlenit do tří skupin na problémy spojené se:
1. Zpracování přirozeného jazyka.
S příchodem internetu se ještě více prohloubila tendence vyřazení jakýchkoli umělých selekčních jazyků z procesu vyhledávání. Trendem je přizpůsobování veškerých vyhledávacích nástrojů pro přirozené jazyky. Důvody jsou zřejmé – jednoduchost obsluhy, zrychlení procesu vyhledávání a široká uživatelská základna. Jak se ale ukazuje, představy o jednodušším vyhledávání pomocí přirozeného jazyka nejsou zcela správné.
Porozumění definice termínu a jeho propojení s konceptem je a bude v automatizovaném zpracování vždy problémem. Jevy jako metafory, synonymie nebo homonymie jsou pro vyhledávací systém těžko řešitelné bez asistence člověka. Podskupinou těchto problémů bude vyřešení jazyků se znakovými sadami, které jsou jiné než latinka. Jazyky jako čínština, korejština nebo arabština (tj. hláskové jazyky obecně) budou pro zpracování a vyhledávání velkou výzvou.
Otázkou do budoucnosti bude využití nových značkovacích jazyků (především XML) pro popis a definice terminologie, užívané v dokumentech. Tato myšlenka – tj. odlišení hlavního obsahu dokumentu od jeho nevýznamových částí – je jedním ze základních pilířů konceptu sémantického webu, který je ovšem stále ve stadiu akademického bádání.
2. Interakce lidí s vyhledávači.
Lidé při hledání často nemají představu o tom, co hledají a snaží se své myšlenky převést do podoby dotazu. Z tohoto důvodu jsou velmi oblíbené webové katalogy (např. Open Directory nebo Yahoo!), ve kterých se vyhledává procházením nabídek v kategoriích a podkategoriích. Jejich hlavním problémem je omezený rozsah, který i u největších z nich (Open Directory uvádí přes čtyři milióny zatříděných stránek) dosahuje pouze zlomku objemu dokumentů registrovaných vyhledávači. Vzhledem k obrovskému nárůstu nových dokumentů tak zůstane vůdčí postavení vyhledávačům, které musí vyvíjet další pomůcky, pro lepší porozumění a zpracování dotazu uživatele. Už nyní se objevují nástroje pro návrhy dotazů – např. služba Google Suggest[4], která navrhne uživateli klíčové slovo a zároveň uvede počet odkazů, které na ně má ve své databázi.
Drtivá většina problémů, která při práci s vyhledávači vzniká, je způsobena nesprávnou představou uživatelů o jejich funkci nebo jejich nedostatečnými znalostmi pro práci s nimi. Uživatelé ve většině případů pracují s vyhledávači velmi krátce a jakýkoli výsledek považují za úspěch, aniž by je dále zkoumali. Výzkumná studie [Pollock – Hockley, 1997] tak výstižně podotýká, že: "...vyhledávače by měly jasně vysvětlit koncept hledání na internetu jako proces, spíše než jednorázovou událost."
Stejná studie dělí konkrétní chyby uživatelů do několika skupin:
Značné mezery ve schopnostech uživatelů potvrzují i novější studie – [Jansen, et al, 1998], [Jansen et.al, 2000], [Spink, et. al., 2001], které shodně dokládají malé užívání pokročilých operátorů pro vyhledávání, nedostatečnou pozornost zpracování výsledků a následné zpětné vazbě pro vyhledávač.
Tyto problémy nejsou řešitelné jiným způsobem než důslednou informační osvětou ze strany vyhledávačů i informačních pracovníků, kteří tak opět mají příležitost zvýšit prestiž svojí profese.
3. Etické aspekty komunikace na internetu – Ověřování informací
Uživatelé chtějí přesná, dohledatelná data. Především v případě vědeckých, zdravotnických a spotřebitelských informací je důležité zajistit jejich pravdivost. Ne vždy jde o životně důležitou informaci jako u popisu nežádoucích účinků nového léku, ale pokud je naše jednání těmito informacemi ovlivněno, stává se pro nás jejich pravdivost nejdůležitějším faktorem. Hlavním problémem není odlišení pravdivé a nepravdivé informace, ale odlišení placené reklamy a stránek nalezených vyhledávačem, což souvisí i s problematikou již zmíněného index spammingu. Studie [Fallows, 2005] poukazuje na nízkou schopnost uživatelů placené odkazy odlišit od nalezených výsledků a také na značnou naivitu uživatelů při posuzování pravdivosti a vyváženosti nalezených informací. Bezplatné vyhledávání informací na internetu bude vždy spojeno se zvýšeným rizikem při užití informace, což je skutečná cena jejich "bezplatnosti".
Problémy vyhledávačů nebudou pravděpodobně nikdy úplně vyřešeny. Dokonalost výpočetní techniky se neslučuje s lidskou nedokonalostí ve formulování myšlenek, a tak člověk množství chyb vytváří tím, že nepochopil koncept a problémy tohoto systému vyhledávání informací. Hlavní oblastí, která by se měla zlepšit, je tak osvěta uživatelů.
Je pravděpodobné, že vyhledávače si i v budoucnu udrží pozici vůdčí technologie pro vyhledávání informací na internetu. Tato technologie, již lze označit za obdobnou té, kterou používají systémy automatizované klasifikace a kategorizace, bude nadále předpokladem pro zpracování alespoň částí stále se zvětšujícího prostoru internetu. Vedle vývoje vyhledávací technologie, která je hlavním předpokladem pro úspěch, můžeme pozorovat další vývojové trendy, které lze rozdělit do několika skupin:
1. Inteligentní funkce pro porozumění dotazům
Jeden z hlavních problémů vyhledávačů je nalezení relevantních stránek na velmi obecný dotaz uživatele. Kromě nabídek typu "Narrow Your Search", které uživatelům pro vyhledávání navrhovaly užší termíny, se nyní objevují nové služby, které návrhy na znění dotazu uvádějí souběžně se zadáváním několika prvních písmen výrazu do hledacího řádku. Tuto službu nabízí například Google pod označením "Google Suggest", kde je u navrhovaných výrazů zároveň zobrazen počet stránek, které jsou k tématu registrovány, nebo český Seznam pod označením "Našeptávač".
Nový vyhledávač společnosti Microsoft umožňuje přímo z vyhledávacího řádku využít i další pokročilé funkce, jako jsou matematické výpočty nebo převody míry a váhy nebo objemu a teploty.
Zajímavý je také přístup vyhledávače AskJeeves, který je zaměřen více na hledání konceptů místo hledání klíčových slov. Jednou z nabídek je hledání zadaného slova, ale zároveň i jeho synonym a významově nejbližších termínů. U výsledků jsou vždy nabídky příbuzných termínů (related topics), které tyto termíny sdružují podle témat (např. u slova "taxonomy" na "plant classification" nebo "species classification"). Ask Jeeves na rozdíl od svých konkurentů používá také lidmi tvořenou databázi odpovědí na otázky (tzv. editorially selected answers), která obsahuje přibližně dva milióny zodpovězených otázek. Tím je zaručena daleko vyšší přesnost odpovědi vyhledávače a také spokojenost uživatele s odpovědí, i když je tento postup finančně velmi nákladný.
2. Selekce zdrojů pro vyhledávání
Tvůrci vyhledávače se snaží vylepšit také prvotní fázi zpracování dotazu a jeho analýzy. Většina dotazů se týká různých faktů a statistických údajů, a proto začaly některé firmy zpracovávat dotazy nejprve v různých encyklopediích a slovnících a teprve poté hledat na webových stránkách. Tento postup zvolila například firma Ask.com (vyhledávač AskJeeves), která vyhledává ve slovnících Merrian-Webster. Google používá slovníky WordReference.com Dictionary, Anzwers.com nebo komunitně tvořenou encyklopedii Wikipedia a vyhledávač Microsoftu – MSN vyhledává ve své naučné encyklopedii Encarta. Zajímavou skutečností je, že celá encyklopedie je přístupná pouze předplatitelům, ale pokud se kdokoli dostane k encyklopedii prostřednictvím MSN, může v ní bezplatně vyhledávat dvě hodiny.
Další náznaky vylepšování selekce zdrojů vyhledávači představují i další služby vyhledávačů, jako je hledání map, zboží nebo informací o celebritách. V delším časovém horizontu bude také zajímavé zhodnotit přínos služeb Google Scholar (vyhledávání v akademických zdrojích) nebo Google Print Library Project (digitalizace a zpřístupnění tištěných knih).
3. Personalizace vyhledávače
Vyhledávač již není pouhým nástrojem pro vyhledávání informací, ale spíše výchozím místem pro jakoukoli práci na internetu. Tím, že si jej mnozí nastavují jako výchozí – domovskou stránku, získávají na významu. Firmy, které tyto vyhledávače provozují, si tuto pozici uvědomují, a snaží se proto vylepšit dostupné vlastnosti a spektrum služeb tak, aby uživatel našel vše, co potřebuje, na jejich serveru a nemusel hledat jinde. Tyto nabídky zahrnují i personalizaci vyhledávacího rozhraní, nastavení speciálních funkcí (např. integrace plánovacího kalendáře k poštovnímu účtu na serveru Yahoo!) nebo informace, které zohledňují fyzické bydliště uživatele (např. obchodní porovnávací systém Bizrate dokáže na základě zadané adresy v USA vypočítat poštovné u zboží, které zákazníka zajímá).
Ze stejného principu vychází i jazykové mutace těchto vyhledávačů, které se snaží více orientovat na lokální zdroje, a konkurovat tak národním vyhledávačům. Stránky vyhledávačů se stávají spíše univerzálními portály se širokou nabídkou služeb, jak to ukazují příklady Google nebo Yahoo!.
4. Vyhledávací lišty pro použití v prohlížeči (toolbars)
Řada vyhledávačů se snaží o to, aby uživatel využíval jejich služeb co nejvíce. Jednou z možností, které uživatelům nabízí, jsou proto tzv. "vyhledávací lišty” (toolbars). Jde o malý program, který se integruje do okna prohlížeče a ze kterého lze přímo vyhledávat. Tyto lišty nabízí v rámci konkurenčního boje řada velkých (např. MSN Toolbar suite, Google Toolbar), ale i menších vyhledávačů (např. Dogpile Search Toolbar, A9 Toolbar).
Uživatel, který má takovou lištu nainstalovanou, bude pravděpodobně vyhledávat především pomocí této lišty, což pro vyhledávač znamená udržení zákazníka a budování vlastní pozice na trhu. Tyto lišty dnes nabízí řadu doplňkových vlastností od vyhledávání ve "Zlatých stránkách” a seznamech firem v USA, přes vyhledávání kurzů akcií až po doplňkový software pro blokování samovolně se otevírajících oken prohlížeče (tzv. pop-up window).
Tento trend vývoje může být odpovědí na praxi společnosti Microsoft a jejího (v současnosti pravděpodobně nejpoužívanějšího) operačního systému Windows a prohlížeče Internet Explorer, který obsahuje také integrovanou funkci vyhledávání na serveru MSN, jež tato společnost vlastní.
5. Doplňkové vyhledávací programy (personal computer search)
Vyhledávací lišty byly prvním krokem k přemístění vyhledávacího rozhraní z webových stránek na počítač uživatele. Hlavním cílem společností, které vyhledávače vlastní, je snaha o globální řešení všech informačních potřeb uživatele svojí technologií. Na konci roku 2004 se proto začaly objevovat aplikace pro personalizované vyhledávání na disku pevného počítače uživatele (tzv. desktop search). Tyto aplikace (např. Copernic Desktop Search, Google Deskbar, od ledna 2005 také Yahoo! Desktop Search) kombinují vyhledávání souborů na pevném disku, osob v adresáři nebo e-mailů s vyhledáváním webových stránek. Technologie jedné firmy tak může zajistit kompletní servis pro vše, co uživatel potřebuje. V této oblasti můžeme očekávat velmi tvrdý boj, protože tyto programy mohou ovlivnit pozici současných vyhledávačů na trhu [Delaney, 2004].
Důvodem souboje největších vyhledávačů o počítač uživatele je také možný příjem z reklamy. Pokud se budou indexovat dotazy, které tento uživatel klade, je možné připravit cílenou reklamu právě pro tohoto uživatele. Je možné, že tyto programy budou dostupné jako tzv. adware, tj. software zdarma, v jehož liště se objevuje reklama. Jestliže se tato technologie uchytí, je možné očekávat i znásobení zisků z reklamy.
Jak ukazuje tento vývoj, konkurenční boj mezi vyhledávači se netýká pouze vlastní vyhledávací technologie, ale ve velké míře také marketingu. Nadstandardní služby uživatelům (doplňkové služby e-mailu zdarma apod.), personalizace vyhledávače nebo nabídka doplňkového softwaru jsou cestou jak zvýšit podíl na trhu a následně i vydělat. Komerční prostředí se tak v případě vyhledávání stává hnacím motorem pro vývoj, který je pro oblast pořádání informací nesmírně důležitý.
Zatím ale vyhledávače nelze považovat za optimální řešení pro pořádání a vyhledávání informací na internetu. Jak uvádí Steve Steinberg [1996]: "Dokonce ani lidé nejsou schopni rozhodnout, jaká informace je relevantní pro zadanou otázku. Pokoušet se, aby to dělal počítač za ně, je skoro nemožné.”
Poznámky
[1] http://ranking.thumbshots.com/
[2] Existují také firmy jako např. Verity nebo Northern Light, které se zaměřují na firemní sektor a nabízí placené vyhledávače nebo komplexní firemní řešení pro vyhledávání.
[3] V České republice například http://www.jyxo.cz.
[4] http://www.google.com/webhp?complete=1&hl=en
Použité zdroje
Arnold, Stephen. 2003. In search of the good search: The invisible elephant. Searcher, 2003, vol. 11, no.3, s. 40–56.
Delaney, Kevin. 2004. Yahoo lets users fine-tune web searches. Wall Street Journal, 2004, October 5, s. D. 9.
Fallows, Deborah. Search engine users: Internet searchers are confident, satisfied and trusting – but they are also unaware and naive [online]. Pew internet & American life project,2005-04-07 [cit.2005-05-10]. Dostupné z URL: http://www.pewinternet.org/pdfs/PIP_Searchengine_users.pdf.
How do search tools work : the freshness. The average freshness for Google, AltaVista, Alltheweb and Inktomi [online]. 2003 [cit.2005-01-14]. Dostupné z URL: http://www.revue-referencement.com/ENGLISH/search_tools_freshness.htm.
Jansen, B.J.Spink, A. - Saracevic, T. A study of users queries on the Web. Information Processing and Management, 2000, vol. 36, no.2.
Jansen, B.J., et al. Real life information retrieval: A study of user queries on the Web. SIGIR Forum, 1998, vol. 33, no.1, s. s. 5-17.
Lawrence, Steve - Giles, C. Lee. Accessibility of information on the web. Nature, 1999, vol. 400, no. 8 July 1999, s. 107-109.
Lyman, Peter – Varian, Hal R. How much information [online]. University of California at Berkeley. School of Information Management and Systems, October 27, 2003 [cit. 2005-04-25]. Dostupné z URL: http://www.sims.berkeley.edu/research/projects/how-much-info-2003/.
Metadent. Search engine software company Inktomi [online]. 2004 [cit.2005-01-14]. Dostupné z URL: http://www.metamend.com/inktomi.html.
Spink, Amanda, et al. Searching the web: The public and their queries. Journal of the American Society for Information Science and Technology, 2001, vol. 52, no.12, s. 1073-1075.
Steinberg, Steve. Seek and ye shall find (maybe). Wired, 1996, vol. 4, no.5, s. 108-114.
Sullivan, Dany.2004. Nielsen NetRatings search engine ratings [online]. 2004 [cit.2005-01-13]. Dostupné z URL: http://searchenginewatch.com/reports/article.php/2156451.
Sullivan, Danny. Nielsen NetRatings search engine ratings: Share of searches: March 2005 [online]. 2005a [cit.2005-04-27]. Dostupné z URL: http://searchenginewatch.com/reports/print.php/34701_2156451.
Sullivan, Danny. Search engine sizes [online]. January 28, 2005b [cit. 2005-04-20]. Dostupné z URL: http://searchenginewatch.com/reports/article.php/2156481.
Sullivan, Dany. 2004. comScore media metrix search engine ratings [online]. 2004a [cit.2005-01-13]. Dostupné z URL: http://www.searchenginewatch.com/reports/article.php/2156431.
Sullivan, Dany. Nielsen NetRatings search engine ratings [online]. 2004b [cit.2005-01-13]. Dostupné z URL: http://searchenginewatch.com/reports/article.php/2156451.
Notess, Greg. Search engine statistics: Freshness showdown [online]. May 17, 2003 [cit. 2005-01-14]. Dostupné z URL: http://www.searchengineshowdown.com/stats/freshness.shtml.
Notess, Greg.2002. Search engine statistics: Relative size showdown [online]. 2002 [cit.2004-12-22]. Dostupné z URL: http://www.searchengineshowdown.com/stats/size.shtml.
Notess, Greg. 1999. On the net: Rising relevance in search engines. Online, 1999, vol. 23, no.3.
Pollock, Annabel – Hockley, Andrew. What´s wrong with internet searching. D-Lib Magazine [online]. 1997 [cit. 2005-01-15]. Dostupné z URL: http://www.dlib.org/dlib/march97/bt/03pollock.html.
CITACE:
Boldiš, Petr.
Vyhledávače: současné problémy a trendy vývoje.
Knihovna plus [online]. 2005, č. 1 . Dostupný z WWW:
<http://knihovna.nkp.cz/knihovnaplus51/boldis.htm>. ISSN 1801-5948.
| nahoru | |obsah| | archiv | | domů |
| index autorů | | index názvů | | index témat |